逻辑回归 (logistic regression) 是一种可以用于分类的回归算法,多用于二分类任务。
Sigmoid 函数
我们为了解决分类问题,可以忽视 (y) 是离散值的情况来使用我们线性回归算法,通过 (x) 来预测 (y)。然而,我们很容易发现这种方法表现得并不好。甚至直观上来看,我们知道 (y) 是0或1,(h_{ heta}(x)) 的值大于1或小于0都是无意义的。为了修正这一情况,我们改变 (h_{ heta}(x)) 的形式,使它满足 (0le h_{ heta}(x) le 1)。
我们称这种新的形式为“s型函数(Sigmoid Function)”,也叫做“逻辑函数(Logistic Function)”:
它的函数图像是这样的

表示的是我们输出为1的概率。比如说,(h_{ heta}(x)=0.7) 表示的是我们的输出是1的概率为70%。
算法过程
(1)收集自变量和因变量的数据,并筛选特征。
(2)构造洛基回归方程。
(3)构造损失函数,利用梯度上升法求得使损失函数最小的回归参数。
(4)模型性能检验,如准确率、混淆矩阵等。
变量筛选
在进行逻辑回归的模型训练过程中,不是所有的变量都适合进入最终的模型。添加进不恰当的自变量反而可能使得模型的效果变差,因此需要对变量做筛选。
常用的筛选方法有 3 种:向前引入法 (forward selection)、向后剔除法 (backward deletion)和逐步回归法 (stepwise selection)。
向前引入法
将自变量逐个引入回归模型。首先,在所有 m 个自变量中选择一个与因变量关系最密切的变量,再在所有剩余的 (m-1) 个自变量中挑选最优的自变量使得模型效果最好,依次不断继续下去,直到当某个自变量进入模型后,模型的效果不再显著提升,即说明该新引入的变量不再对因变量具有显著影响。
这种方法的缺点是先引入的自变量在之后不会被剔除出去,但在新变量加入后,可能导致老变量变得不显著,这时继续保留老的变量是不合理的。
向后剔除法
与向前引入法相反,先引入所有自变量,再逐个剔除掉对模型影响最小的变量,直到剩余的所有变量的显著性水平都高于设置的阈值。
这个方法的缺点和向前引入法类似,先被剔除的变量就再也没机会重新进入模型中了,而随着变量的变化,先被删除的变量可能又重新变得有显著性,但却没有办法重新纳入模型
逐步回归法
逐步回归法综合了以上两个方法的优点。自变量仍然首先逐个引入回归模型,不同的是,每次新变量进入后,又要对所有已有的变量进行检验,一旦发现有变量变得不显著时就立刻删除该变量,如此循环直到保留下的所有变量均无法删除,且新的变量也无法加入为止。
算法的优缺点
优点:
(1)产生的模型可解释性强,可以看到各个自变量的权重和影响。
(2)无需事先假设数据的分布,避免了假设分布不准确造成的问题。
(3)不仅给出预测的类别,也给出概率值的预测,有利于实现其他更精细的决策。
缺点:
(1)对异常值敏感。
(2)无法处理缺失值,需要进行适当的处理。
(3)预测精度一般,容易欠拟合。
多类分类问题
如果分类不止有0和1两种类别,那么就是one-vs-all问题了。
解决办法是建立多个模型,每一个模型都把其中一类与其他所有形成的一个新类分开。
所以如果有3类,那么模型就有3个。(如果有2类,模型只有1个)。
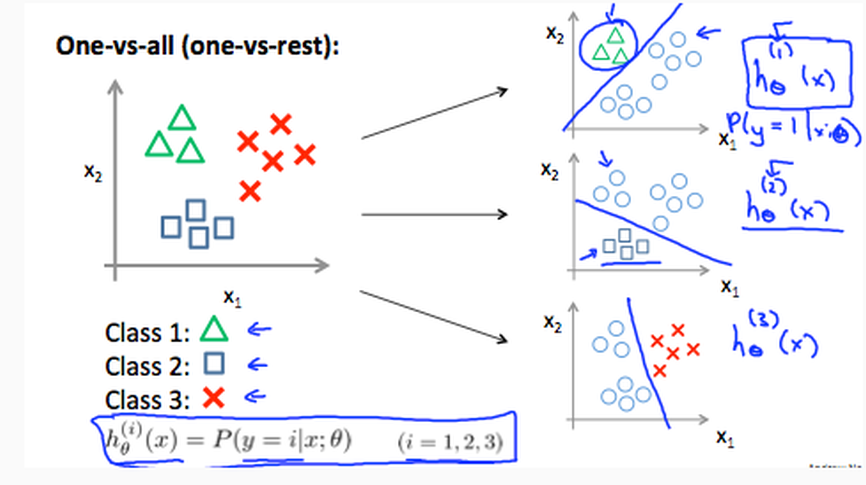
为了确定某个值是哪一类,代入这些模型计算,取 (h_{ heta}(x)) 最大的那一类。
Demo
使用逻辑回归对乳腺癌数据集进行二分类。
Jupyter Notebook 链接为:LR-BC
【References】
[1] 裔隽,张怿檬,张目清等.Python机器学习实战 [M].北京:科学技术文献出版社,2018
[2] Andrew Ng. Machine Learning [EB/OL]. https://www.coursera.org/learn/machine-learning/home/info,2019-6-29