
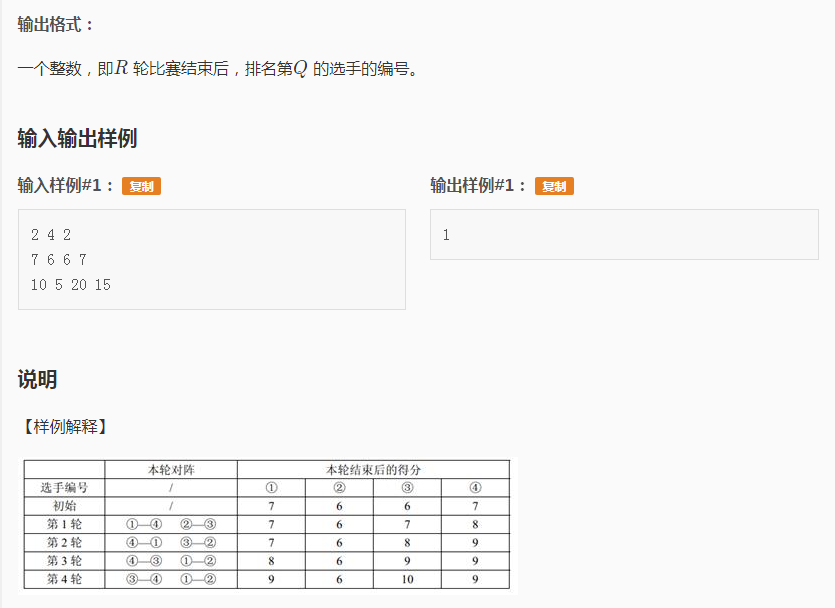

思路非常简单,只要开始时把结构体排个序,每次给赢的加分再排序,共r次,最后再输出分数第q大的就行了。
(天真的我估错时间复杂度用每次用sort暴力排序结果60分。。。)实际上这道题估算时间复杂度时O括号里的n并不是输入的n,而是输入的n乘2,这就要求我们精准地估算时间复杂度以采取合适的算法来解题。显然sort时不行的。为什么sort这么强都会TLE?考虑不行的原因,找找有用的教训:(先普及一下:sort是冒泡排序的改进版,平均时间复杂度为O(n log n),最坏情况下会退化成O(n2)。)
从sort的原理开始考虑:sort排序时会有两个指针分别从头到尾相向而行直到相遇后的分手。然后再分别对左右两部分递归,直到递归的区间长度为1。这样发现,就算这个序列已经有序(或基本有序)时,sort会造成大量的时间浪费。这时同时O(n log n)级别的归并排序就不同了。当序列基本有序时,归并排序会造成更少的时间浪费,因为序列基本有序时,“并”操作左右两区间中的左区间应该是主要都小于右区间的,这样就会使左区间更早地并入答案数组,剩下的右区间的长度相应地更长,用个memcpy就完事了,结果是使使左右区间的开头端点比较的次数减少,进而减少了时间浪费。
发现把一个大轮回比赛里的所有赢家单独拿出来后他们的顺序都是合法且不变的(因为都是从原来的序列中的相应值加1);所有输家的大小顺序也是合法的(因为值都没有改变)。这样可以直接用归并排序的思想,把赢家都放在一个区间、输家放在另一个区间中,两个区间只要归并一次就能得到有序的数列了,无需再各种递归费解合并。
见AC代码:
1 #include<iostream> 2 #include<algorithm> 3 #include<cstdio> 4 #include<cctype> 5 #include<cstring> 6 7 using namespace std; 8 9 struct hum{ 10 int num,s,w; 11 }a[200003],win[100005],lose[100005];//赢的放一起,输的放一起 12 13 int n,r,q,ans,lw,ll; 14 15 char ch; 16 17 bool cmp(hum a,hum b) 18 { 19 return a.s>b.s||(a.s==b.s&&a.num<b.num); 20 } 21 22 inline int read() 23 { 24 ans=0; 25 ch=getchar(); 26 while(!isdigit(ch)) ch=getchar(); 27 while(isdigit(ch)) ans=(ans<<3)+(ans<<1)+ch-'0',ch=getchar(); 28 return ans; 29 } 30 31 int main() 32 { 33 n=(read())<<1,r=read(),q=read(); 34 for(int i=1;i<=n;i++) 35 { 36 a[i].num=i; 37 a[i].s=read(); 38 } 39 for(int i=1;i<=n;i++) a[i].w=read(); 40 sort(a+1,a+n+1,cmp); 41 for(int k=1;k<=r;k++) 42 { 43 for(int i=1;i<=n;i+=2) 44 { 45 if(a[i].w>a[i+1].w) 46 { 47 a[i].s++; 48 win[++lw]=a[i]; 49 lose[++ll]=a[i+1]; 50 } 51 else 52 { 53 a[i+1].s++; 54 win[++lw]=a[i+1]; 55 lose[++ll]=a[i]; 56 } 57 } 58 int l=1,r=1,len=1;//往下都是并的过程 59 while(l<=lw&&r<=ll) 60 { 61 if(win[l].s>lose[r].s) 62 a[len++]=win[l++]; 63 if(win[l].s<lose[r].s) 64 a[len++]=lose[r++]; 65 if(win[l].s==lose[r].s) 66 { 67 if(win[l].num<lose[r].num) a[len++]=win[l++]; 68 else a[len++]=lose[r++]; 69 } 70 } 71 if(l<=lw) memcpy(a+len,win+l,sizeof(hum)*(lw-l+1)); 72 if(r<=ll) memcpy(a+len,lose+r,sizeof(hum)*(ll-r+1));//并的过程结束 73 lw=0;ll=0; //因为是由前缀++维护,所以要初始化为1 74 } 75 cout<<a[q].num; 76 return 0; 77 }
还是要做好时间复杂度估计的说!