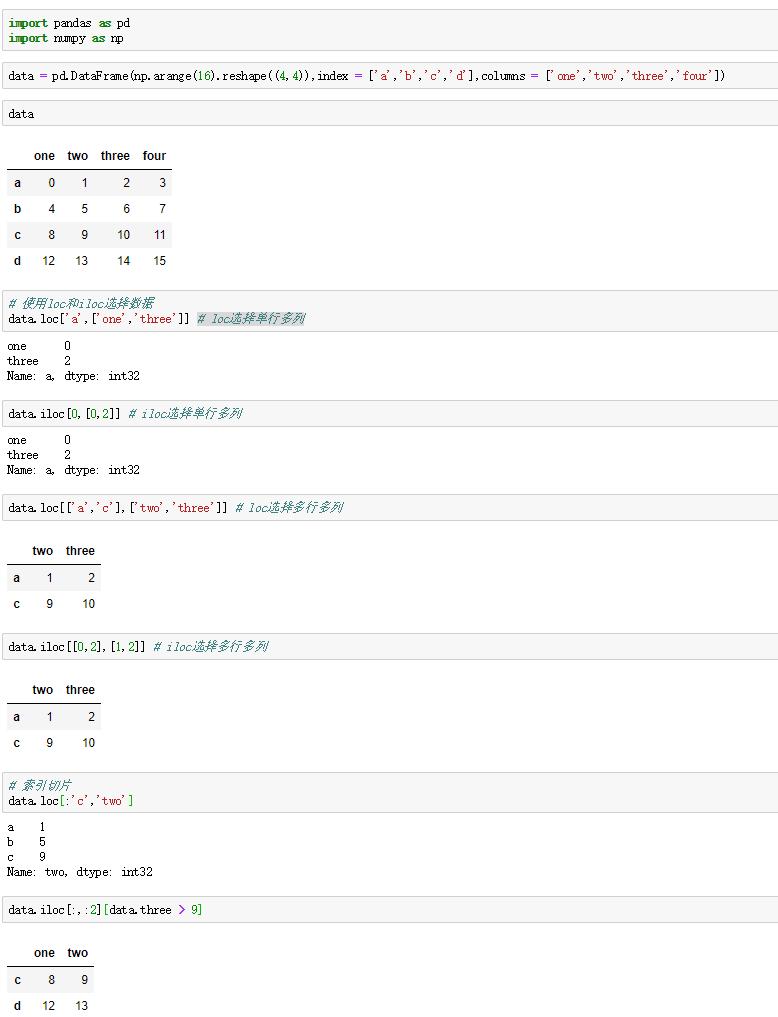
上节介绍了一些索引的选择,下面介绍另外一种选择数据的方式是使用loc和iloc选择数据。这两个分别叫做轴标签(loc)或整数标签(iloc)。
轴标签是通过索引或者列名选择数据。
整数标签是所在位置整数选择数据。
loc和iloc还可以带切片操作。
例如:
4.整数索引
在pandas中使用整数索引可能会产生歧义,尤其是当索引或者列名是整数的时候。想要推断用户所需要的索引方式是很难的。因此此时的轴标签(loc)或整数标签(iloc)就起到了作用了。
5.数据对齐
pandas的一个重要特性是不同索引的对象之间的算术行为。比如相加时,返回的结果的索引将是索引对的并集。没有交集的标签位置,数据对齐会产生缺失值。
例如:
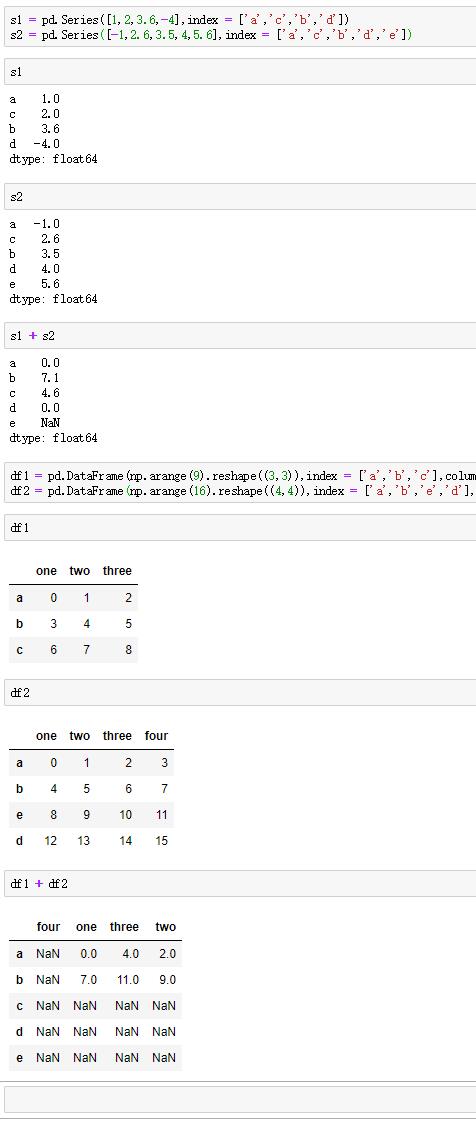
将两个行或列完全不同的DataFrame对象相加,结果将全部为空。
例如:
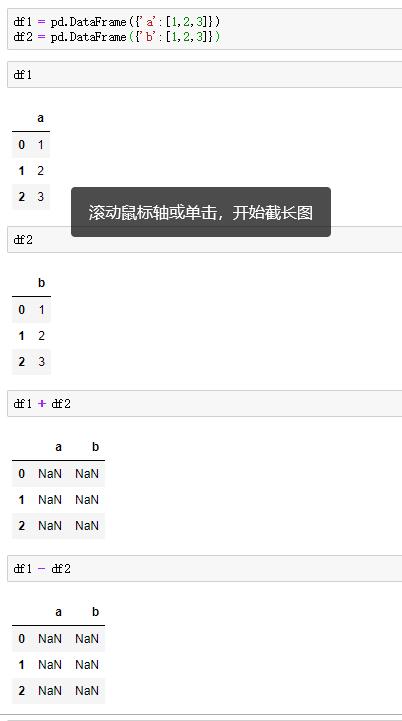
可以在有缺失值的时候将缺失值填充为想要的数值,用fill_value方法。
例如:

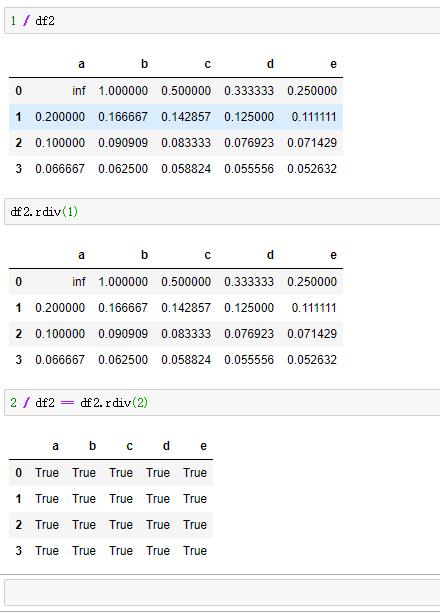
可以用rdiv(n)将数组进行反转,比如将n/df和df.rdiv(n)等价反转。
例如:
6.函数应用和映射
NumPy的通用函数(逐元素数组方法)对pandas对象也有效,这里不详细介绍了。
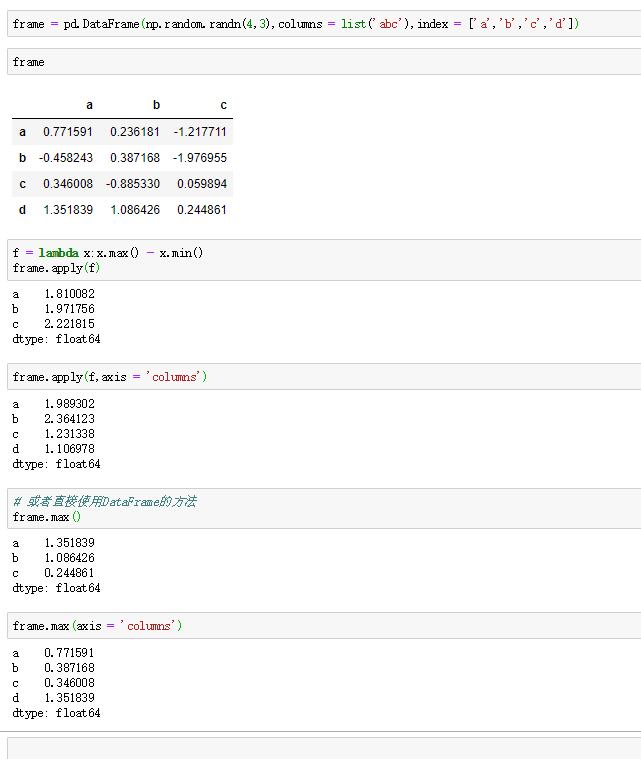
还有一个常用的操作是将函数应用到一行或一列的一维数组上。可以用apply方法来实现这个功能,如果传递axis='columns'给apply函数,将会被每行调用一次,但是apply构建的一些常用函数可以用DataFrame的方法代替。
例如:
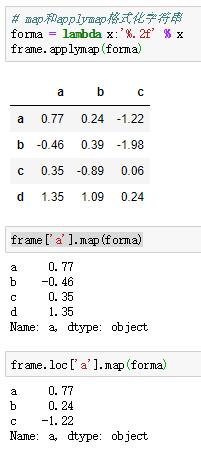
如果想要格式化的话,可以在Series中使用map方法,或者在DataFrame中使用applymap方法。
例如:
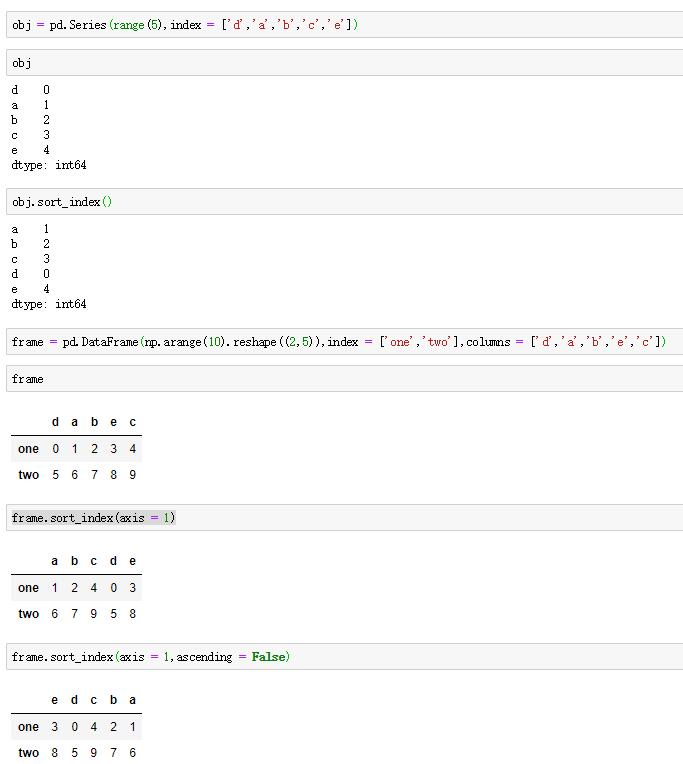
7.排序和命名
对数据按照某种规则进行排序是很重要的操作。比如按行或列索引进行字典型排序,需要使用sort_index方法,以及axis=1,参数。数据会默认升序排列,且所有的缺失值将会被排序至Series的尾部。如果要降序排列的话,需要设置参数ascending=False。
例如:
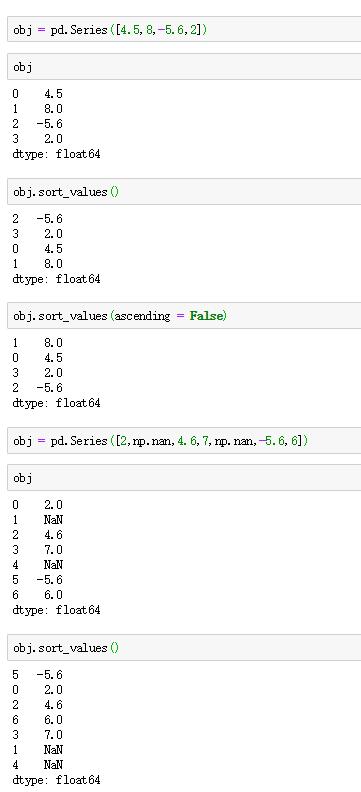
如果要根据Series的值进行排序,需要使用sort_values方法。
例如:
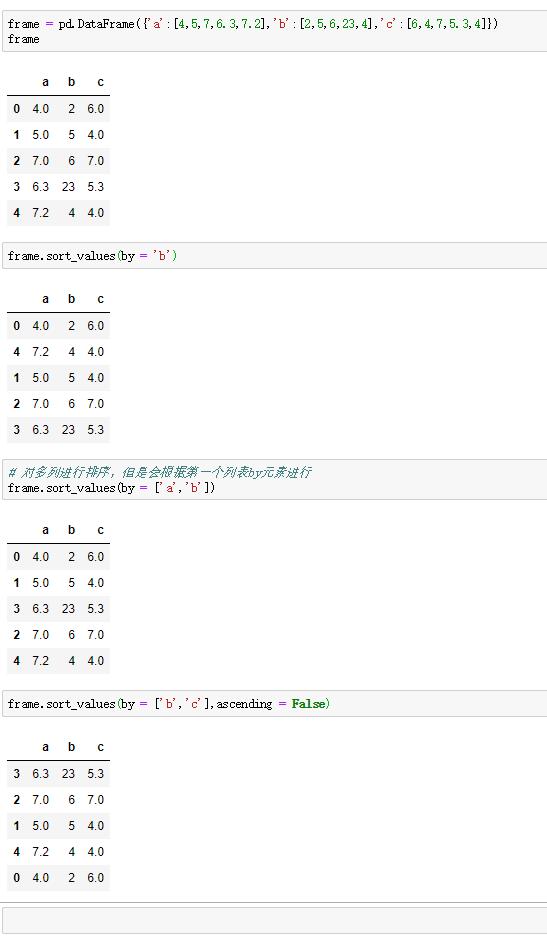
要对DataFrame排序的话,选择一列或多列作为排序键,只要传递可选参数by即可。
例如:
8.含有重复标签的轴索引
有些Series和DataFrame的索引值可能是不止一个的,用is_unique属性可以知道它的标签是否唯一。
例如:
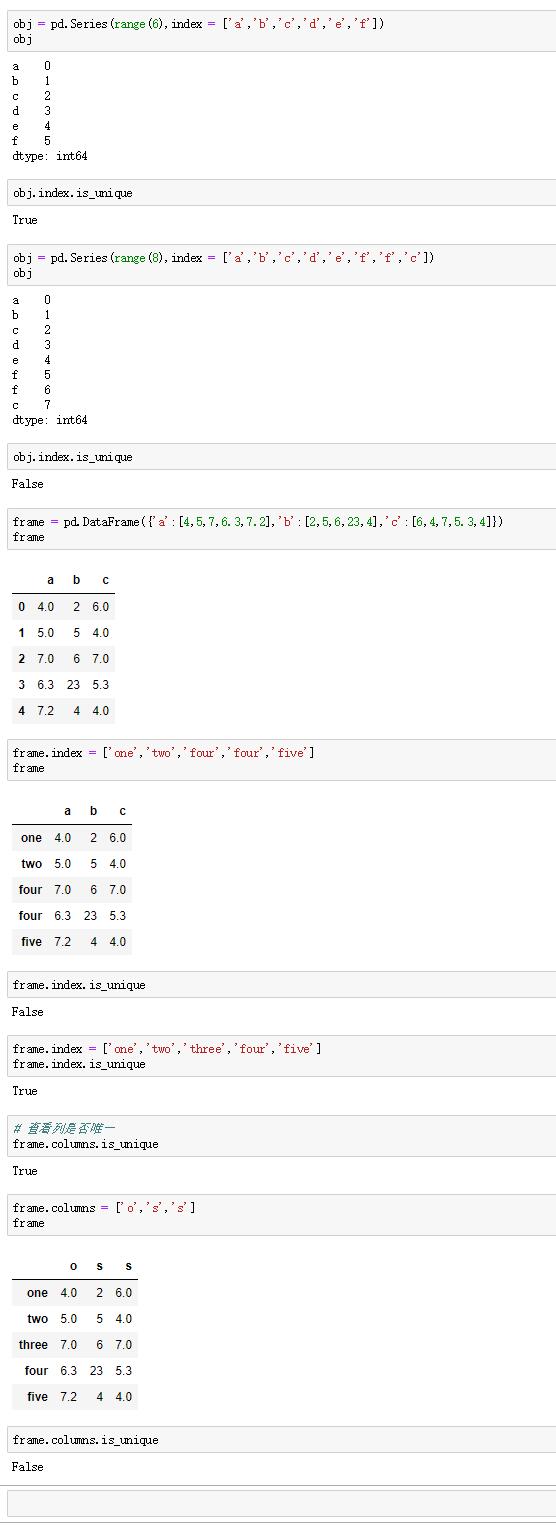
根据一个标签索引多个条目会返回一个序列,而单个条目会返回标量值,因此的话还要进行进一步筛选,因此尽量不要使用多个重复的索引进行构建pandas的数组。