维度灾难
维度增多主要会带来高维空间数据稀疏化问题,
也就是说,数据会更加的分散,因而就需要更大的数据量才能获得较好的bias和variance,达到较好的预测效果。
此处,最典型的是对于KNN的预测。
更详细的见:怎样理解"curse of dimensionality",
另一方面看,当维度增加时,也可能导致过拟合现象:训练集上表现好,但是对新数据缺乏泛化能力。高维空间训练形成的分类器,相当于在低维空间的一个复杂的非线性分类器,这种分类器过多的强调了训练集的准确率甚至于对一些错误/异常的数据也进行了学习,而正确的数据却无法覆盖整个特征空间。因此,这样得到的分类器在对新数据进行预测时将会出现错误。
下图是随着维度(特征数量)的增加,分类器性能的描述:
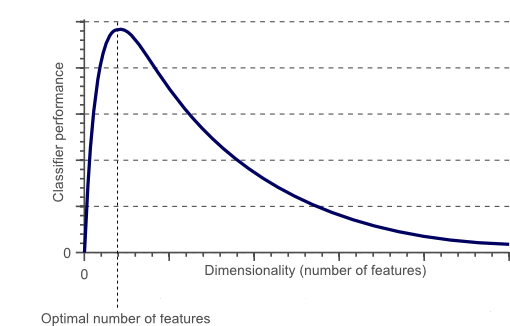
但是如何避免维度灾难呢?
并没有固定的规则规定在分类问题中应该使用多少个特征,因为维度灾难问题和训练样本的数据有关。
事实上,避免维度灾难主要有两种方法:
- 降维。可以是从原本维度中挑选一些维度,或是从原特征的基础上构造新特征
- 交叉验证。
参见:机器学习中的维数灾难
bias与variance的权衡
上面既然提到了bias和variance,趁机就详细说一下
bias与variance到底是个什么鬼
解释1:
bias 偏差 :模型的期望(或平均)预测和正确值之间的差别
variance 方差 :模型之间的多个拟合预测之间的偏离程度
更多关于bias和variance的定义(包括概念定义,图形化定义,数学定义等)见:权衡偏差和方差
解释2:
也就是说,bias和variance分别从两个方面来描述了我们学习到的模型与真实模型之间的差距。
Bias是 “用所有可能的训练数据集训练出的所有模型的输出的平均值” 与 “真实模型”的输出值之间的差异;
Variance则是“不同的训练数据集训练出的模型”的输出值之间的差异。
解释3:
Error反映的是整个模型的准确度,Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。
而这两个与过拟合和欠拟合又有什么关系呢?
处理过拟合和欠拟合的过程就是关于处理bias和variance。模型复杂度越高,过拟合的风险就越大,bias就减小,但是variance就越高。如下图所示:
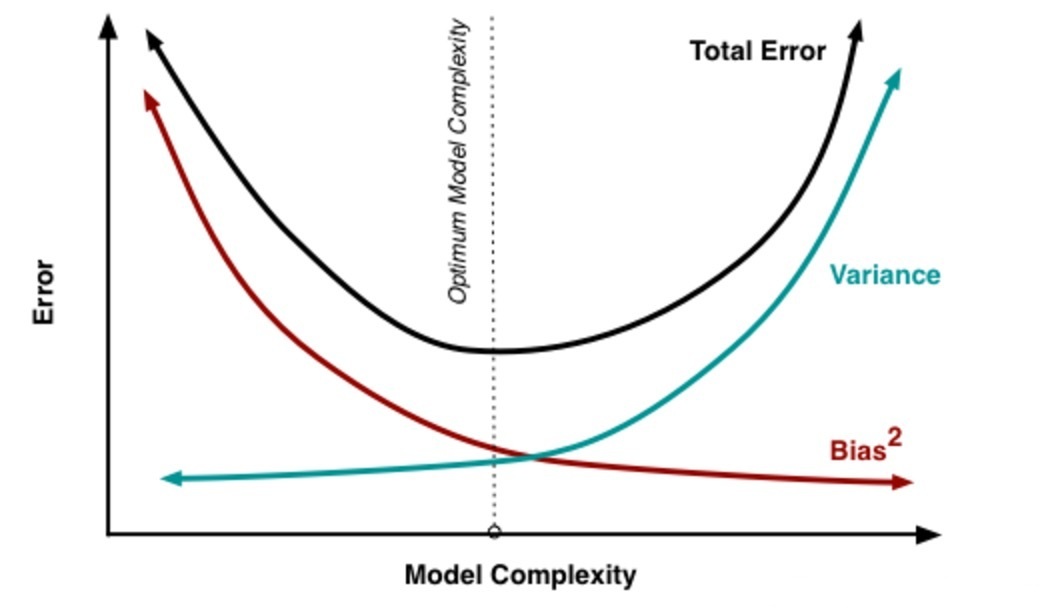
K折交叉验证中K的选择:当k偏小的时候,会导致bias偏高。当k偏大的时候,会导致variance偏高,通常把k控制在5~10的范围里。
bias-variance判断:
- 根据错误均值判断bias,如果错误均值很低,说明在这个数据集上,该模型准确度是可以的。
- 根据错误标准差来判断variance,如果错误标准差很高,说明该模型的泛化能力需要提高。
也就是说,一个好的模型,偏差越小越好,方差越小越好。