本文介绍caret包中的建立模型及验证的过程。主要涉及的函数有train(),predict(),confusionMatrix(),以及pROC包中的画roc图的相关函数。
建立模型
在进行建模时,需对模型的参数进行优化,在caret包中其主要函数命令是train。
train(x, y, method = "rf", preProcess = NULL, ...,
weights = NULL, metric = ifelse(is.factor(y), "Accuracy", "RMSE"),
maximize = ifelse(metric %in% c("RMSE", "logLoss", "MAE"), FALSE, TRUE),
trControl = trainControl(), tuneGrid = NULL,
tuneLength = ifelse(trControl$method == "none", 1, 3))
- x 行为样本,列为特征的矩阵或数据框。列必须有名字
- y 每个样本的结果,数值或因子型
- method 指定具体的模型形式,支持大量训练模型,可在此查询:点击
- preProcess 代表自变量预处理方法的字符向量。默认为空,可以是 "BoxCox", "YeoJohnson", "expoTrans", "center", "scale", "range", "knnImpute", "bagImpute", "medianImpute", "pca", "ica" and "spatialSign".
- weights 加权的数值向量。仅作用于允许加权的模型
- metric 指定将使用什么汇总度量来选择最优模型。默认情况下,"RMSE" and "Rsquared" for regression and "Accuracy" and "Kappa" for classification
- maximize 逻辑值,metric是否最大化
- trControl 定义函数运行参数的列表。具体见下
- tuneGrid 可能的调整值的数据框,列名与调整参数一致
- tuneLength 调整参数网格中的粒度数量,默认时每个调整参数的level的数量
下面来具体介绍一下trainControl函数
trainControl(method = "boot", number = ifelse(grepl("cv", method), 10, 25),
repeats = ifelse(grepl("[d_]cv$", method), 1, NA), p = 0.75,
search = "grid", initialWindow = NULL, horizon = 1,
fixedWindow = TRUE, skip = 0, verboseIter = FALSE, returnData = TRUE,
returnResamp = "final",.....)
- method 重抽样方法:"boot", "boot632", "optimism_boot", "boot_all", "cv", "repeatedcv", "LOOCV", "LGOCV" (for repeated training/test splits), "none" (only fits one model to the entire training set), "oob" (only for random forest, bagged trees, bagged earth, bagged flexible discriminant analysis, or conditional tree forest models), timeslice, "adaptive_cv", "adaptive_boot" or "adaptive_LGOCV"
- number folds的数量或重抽样的迭代次数
- repeats 仅作用于k折交叉验证:代表要计算的完整折叠集的数量
- p 仅作用于分组交叉验证:代表训练集的百分比
- search Either "grid" or "random",表示如何确定调整参数网格
用kernlab包中的spam数据来进行实验
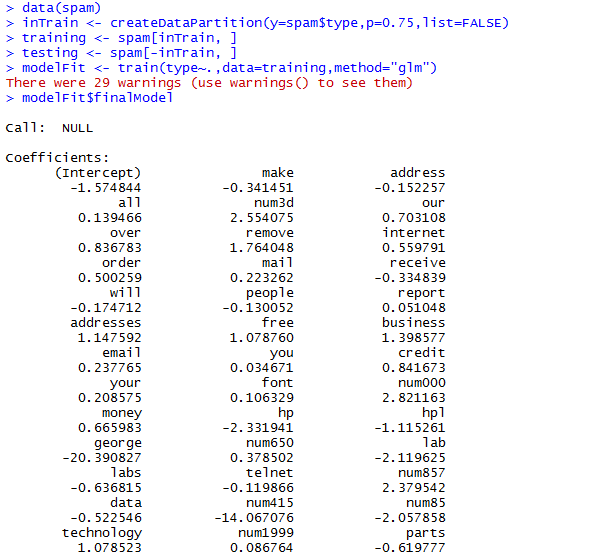
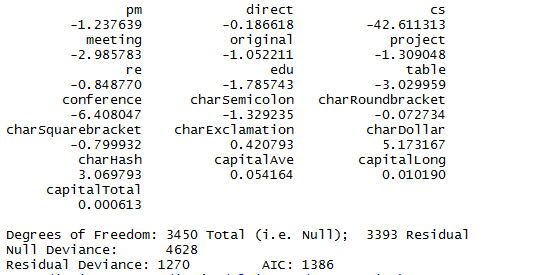
模型预测
当模型的参数全部训练完毕后,就要将测试数据带入模型中进行验证预测了,此时主要用到predict函数
predict (object, ...)
- object 模型对象
- ... 影响生成预测的其他参数
(篇幅有限,仅为部分预测结果)
模型评价
想知道模型预测的准确率如何呢?这个时候就要用到错误分类矩阵了,将模型预测的值和真实的值进行比较,计算错误分类率。通过观察错误分类矩阵,我们可知准确率为0.9333,结果还是很理想的。但是本次举的例子不太好,主要可能是划分训练集和测试集时太随意了。但是大体的过程就是这样了
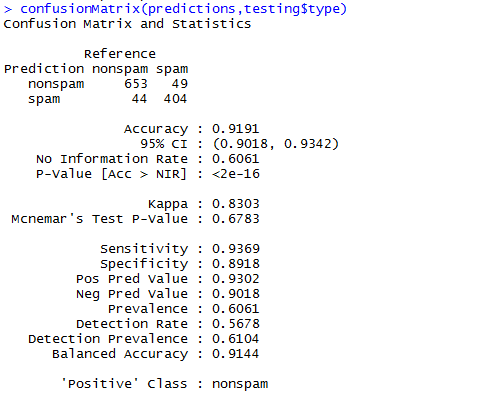
另外,评价模型的还有ROC图,此处用的时pROC包
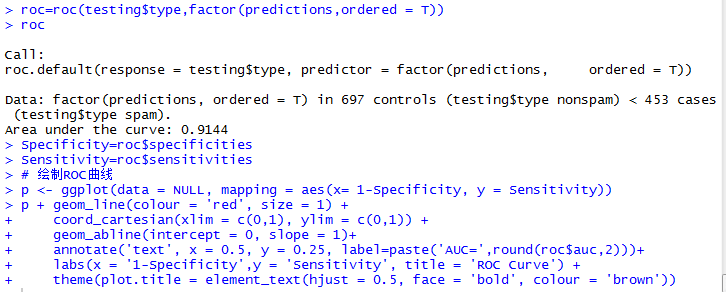
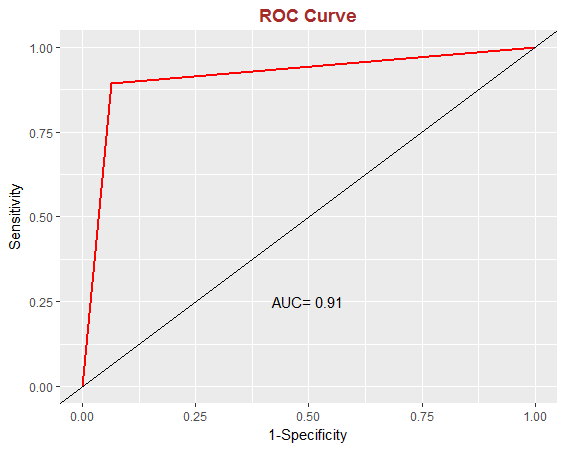
参考: