本文将就caret包中的数据分割部分进行介绍学习。主要包括以下函数:createDataPartition(),maxDissim(),createTimeSlices(),createFolds(),createResample(),groupKFold()等
基于输出结果的简单分割
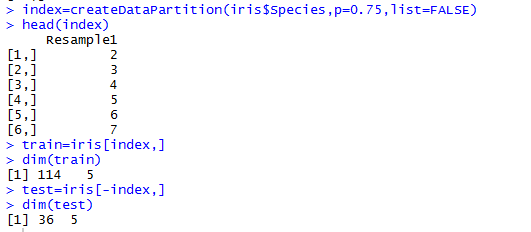
createDataPartition函数用于创建平衡数据的分割。如果函数中的参数y是一个因子向量,则对每一类随机抽样,并且保持数据整体类别的分类。
createDataPartition(y, times = 1, p = 0.5, list = TRUE, groups = min(5, length(y)))
- y 结果向量
- times 创建分区的数目
- p 将要用于训练的数据的百分比
- list 逻辑值。true时,返回结果为列表形式,否则,为floor(p * length(y))行 times列的矩阵
- groups 对于数值y,样本根据百分位数分成组,并在这些子组内进行采样。百分比的数量通过groups参数设置。
基于特征变量的分割
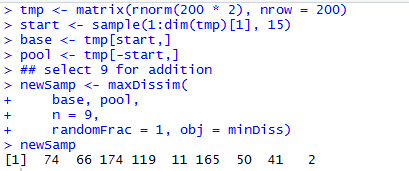
函数maxDissim应用最大相异方法(maximum dissimiarity approach)创建子样本。假设有一个m个样本的数据集A和具有n个样本的一个大数据集B。我们希望从B中抽取和A不同的子样本。为了这样做,对于B中的每一个样本,函数计算与A中每一样本点的相异性。把B中最大相异性的点加到A并继续。注意,计算相异性时,要加载proxy包
maxDissim(a, b, n = 2, obj = minDiss, useNames = FALSE, randomFrac = 1, verbose = FALSE, ...)
- a 小样本数据集,矩阵或数据框
- b 大样本数据集,矩阵或数据框
- n 子样本的大小,其实就是最后想要找出的相异性样本的个数
- obj 衡量总体差异的函数,常用的有minDiss,sumDiss
- useNames 逻辑值,true返回行名,false返回行索引
- randomFrac 在(0,1]中的数值,用于从剩余候选值中进行子采样
- verbose 逻辑值,是否显示每步过程
时间序列的数据分割
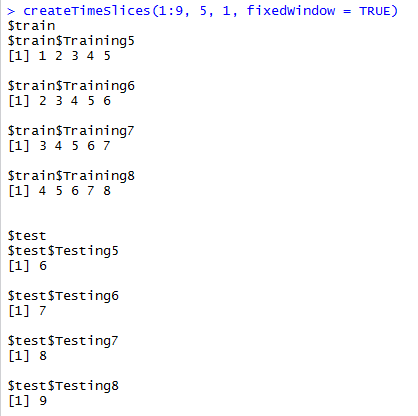
时间序列简单随机抽样并不是对时间序列抽样的最好的方法。Hyndman和Athanasopoulos(2013)讨论了rolling forecasting origin技术。caret包 包含了createTimeSlices函数,它能创建这种类型的切片。
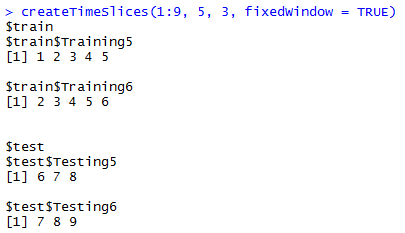
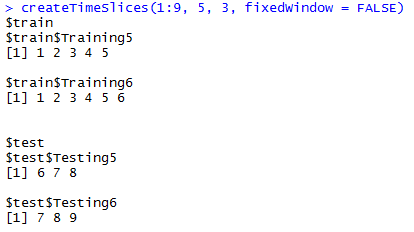
createTimeSlices(y, initialWindow, horizon = 1, fixedWindow = TRUE, skip = 0)
- y 结果向量,按年代或其他时间顺序
- initialWindow 每个训练集样本中连续值的初始数量
- horizon 测试样本中的连续值的数量
- fixedWindow 逻辑值,false时,所有训练样本从1开始
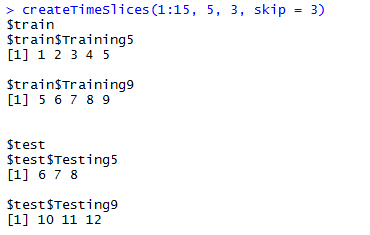
- skip 整数,how many (if any) resamples to skip to thin the total amount
horizon参数值不同时的情形:horizon分别为1,3时,测试样本的数量分别为1,3
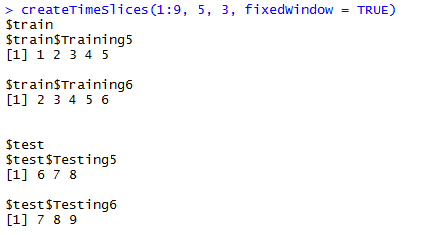
fixedWindow分别为TRUE和FALSE时的情形,可见为false时,训练样本总是从头开始。
skip参数,注意skip为3时,不同训练样本的第一个索引依次加4
其他类似函数
此外,在制造训练集时,还有以下可能用到的函数
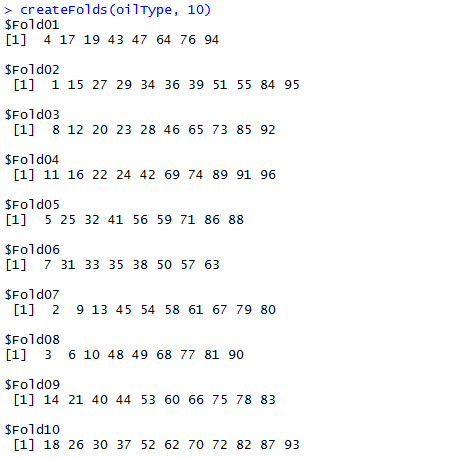
1、 createFolds(y, k = 10, list = TRUE, returnTrain = FALSE)
其中,k是folds的数目,list,是否以列表形式返回,returnTrain,false时返回的是测试集的索引,true时返回的是训练集的索引(仅当list=TRUE时,returnTrain=TRUE才有效)
2、 createResample(data,k)
其中,k是创建训练样本的个数
3、 groupKFold(group, k = length(unique(group)))
其中,k是folds的数目

参考:http://topepo.github.io/caret/data-splitting.html (其中文翻译见)