1.手写数字数据集
- from sklearn.datasets import load_digits
- digits = load_digits()
# 1.数据集读入 from sklearn.datasets import load_digits #读入手写数字数据 digits=load_digits() print("数据集大小:",digits.data.shape) # 查看数据集大小 print("数据集target:",digits.target) # 查看target

2.图片数据预处理
- x:归一化MinMaxScaler()
- y:独热编码OneHotEncoder()或to_categorical
- 训练集测试集划分
- 张量结构
# 归一化:将某一列特征的值缩放到一个最小和最大值(默认0-1)之间,用于去除不同维度的数据的量纲以及量纲单位 from sklearn.preprocessing import MinMaxScaler import numpy as np X_data = digits.data.astype(np.float32) # 转换为32位浮点数 scaler = MinMaxScaler() X_data = scaler.fit_transform(X_data) # 归一化处理 X = X_data.reshape(-1,8,8,1) # 转为图片的格式 X.shape # 查看归一化后的数据大小

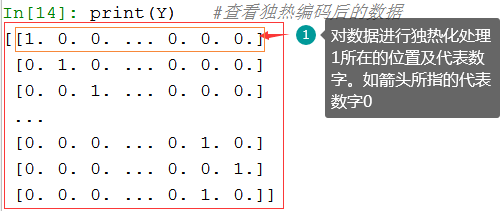
# 独热编码 # OneHotEncode“独热编码”,一位有效编码将分类特征的每个元素转化为一个可用来计算的值 Y_data = digits.target.astype(np.float32).reshape(-1,1) # 将Y_data变为一列 from sklearn.preprocessing import OneHotEncoder Y = OneHotEncoder().fit_transform(Y_data).todense() # 对数据进行独热编码 print(Y) #查看独热编码后的数据
# 进行训练集、测试集划分 # 以训练集:测试集=8:2的比例划分 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0,stratify=Y) print(X_train.shape,X_test.shape,y_train.shape,y_test.shape) # 查看训练集测试集shape

3.设计卷积神经网络结构
- 绘制模型结构图,并说明设计依据。


4.模型训练
- model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
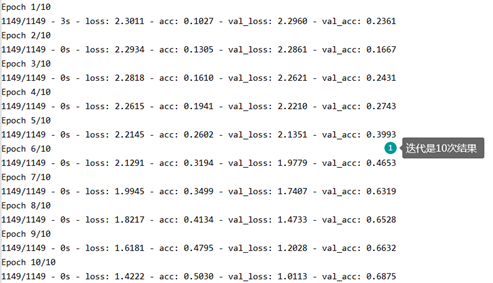
- train_history = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2)
# 4.训练模型 model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) train_history = model.fit(x=X_train,y=y_train,validation_split=0.2, batch_size=300,epochs=10,verbose=2) # 验证集 # 一次性测试的数据个数# 迭代次数(训练次数)


5.模型评价
- model.evaluate()
- 交叉表与交叉矩阵
- pandas.crosstab
- seaborn.heatmap
# 5.模型测试 model.evaluate(X_test,y_test) #传入数据评估

# 观察预测值与实际值 y_pred = model.predict_classes(X_test) print("预测值:",y_pred[:10]) print("实际值:",y_test[:10])

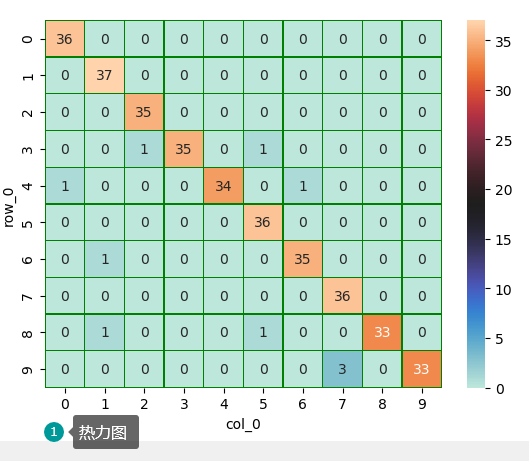
# 转换真实值 y_test1=np.argmax(y_test,axis=1).reshape(-1) y_true=np.array(y_test1[0]).reshape(-1) # 交叉表查看预测数据与原数据对比 import pandas as pd pd.crosstab(y_true,y_pred,rownames=['true'],colnames=['predict'])

# 通过热力图观察预测值与实际值的符合程度 import seaborn as sns a = pd.crosstab(y_true,y_pred) df=pd.DataFrame(a) # summer RdYlBu PuBuGn PUBU sns.heatmap(df,annot=True,cmap="icefire",linewidths=0.2,linecolor='G')