1. 应用K-means算法进行图片压缩
读取一张图片
观察图片文件大小,占内存大小,图片数据结构,线性化
用kmeans对图片像素颜色进行聚类
获取每个像素的颜色类别,每个类别的颜色
压缩图片生成:以聚类中收替代原像素颜色,还原为二维
观察压缩图片的文件大小,占内存大小
代码:
#201706120153许卉欣 from sklearn.cluster import KMeans import matplotlib.pyplot as plt import sys import numpy as np image=plt.imread("./data/cat.jpg") #plt.imshow(img) print("压缩前图片大小:",image.size) print("压缩前图片占用的内存:",sys.getsizeof(image)) img=image[::3,::3] #为了研究方便,这里先降低分辨率,每三个取一个值 x=img.reshape(-1,3) #这里我们只对颜色进行聚类,故不考虑点所在的位置,将颜色信息整合成一个数组 model=KMeans(n_clusters=16) #这里我们只取16种颜色 labels=model.fit_predict(x) #对X进行训练和聚类 colors = model.cluster_centers_ #查看聚类中心 newImage = colors[labels].reshape(img.shape) print("压缩后的图片的大小:",newImage.size) print("压缩后的图片占用的内存:",sys.getsizeof(newImage)) plt.imshow(newImage.astype(np.uint8))
结果:



2. 观察学习与生活中可以用K均值解决的问题
从数据-模型训练-测试-预测完整地完成一个应用案例。
这个案例会作为课程成果之一,单独进行评分。
问题背景:某美妆公司推出一款目标用户为女大学生的高端线新产品,苦于无法有效筛选出有效目标用户。根据向目标年龄段发放调查问卷后,获得了一定数据进行分类筛选。
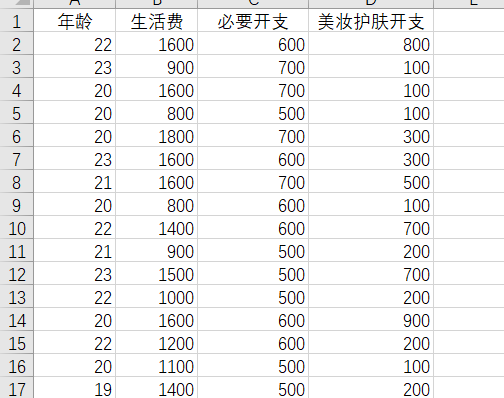
数据内容:用户年龄、用户每月可支配费用、用户每月必要开支、用户每月在美妆护肤上的开支(100以下取100,不满百向上取整至百,数值皆为大致范围)*为方便实验本次只取用300条
数据预览:
代码:
#201706120153许卉欣 from sklearn.cluster import KMeans import pandas as pd import matplotlib.pyplot as plt from pylab import mpl data=pd.read_excel('./data/test.xlsx') #进行数读取 model=KMeans(n_clusters=3) #构建模型 model.fit(data) #模型匹配训练 pre=model.predict(data) #进行分类 #散点作图以直观查看用户分类 mpl.rcParams['font.sans-serif'] = ['Microsoft YaHei'] plt.scatter(data.values[:,1],data.values[:,3],c=pre,s=25) plt.scatter(model.cluster_centers_[:,1], model.cluster_centers_[:,3], s=50,color='red') plt.title("某化妆品公司客户分类") plt.xlabel("可支配收入") plt.ylabel("美妆护肤开支") plt.show()
结果:
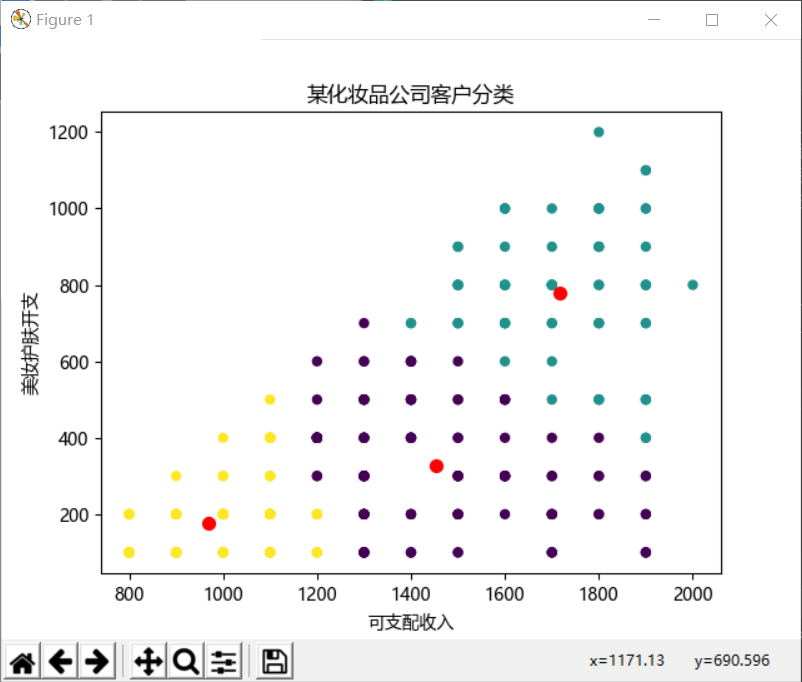
问题结果:进行kmeans分类后,可以看出一部分用户可支配收入高,在美妆方便也愿意投入一定的金钱。用户分为三类,分类为第0类的客户,可支配收入最低,在美妆方面花费的金额也较少;分类为第1类的用户可支配收入最高,在美妆方面花费的金额也更多;分类为第2类的用户,可支配收入高,在美妆方面花费的金额却较少。所以综上所述,当用户分为第0类时,公司可向这部分用户推荐一下低端线的产品,适合用户的条件;当用户分类为第1类时,公司可重点向其推荐新产品,抓牢该部分顾客的市场份额;当用户分类为2类时,用户为潜在客户,可向其介绍推荐一些入门的护肤产品引起兴趣增大她们在这一方面的投入。
下面我们进行客户分类预测,派发调查问卷获得用户的年龄、大致可支配收入,每月必要开支和在护肤品上预期投入金额,将数据放入模型进行预测。
test=pd.DataFrame([[21,1200,800,300],[20,2000,800,1000],[19,1800,1000,800]])#输入三组数据查看属于哪一类顾客 model.predict(test)#输出分类结果
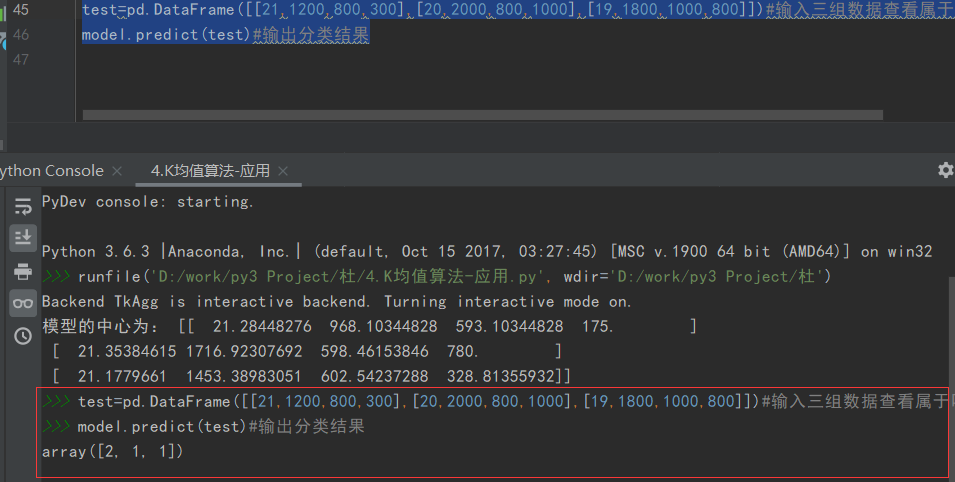
从图可知,这三位客户用户潜在值为低,高,高。