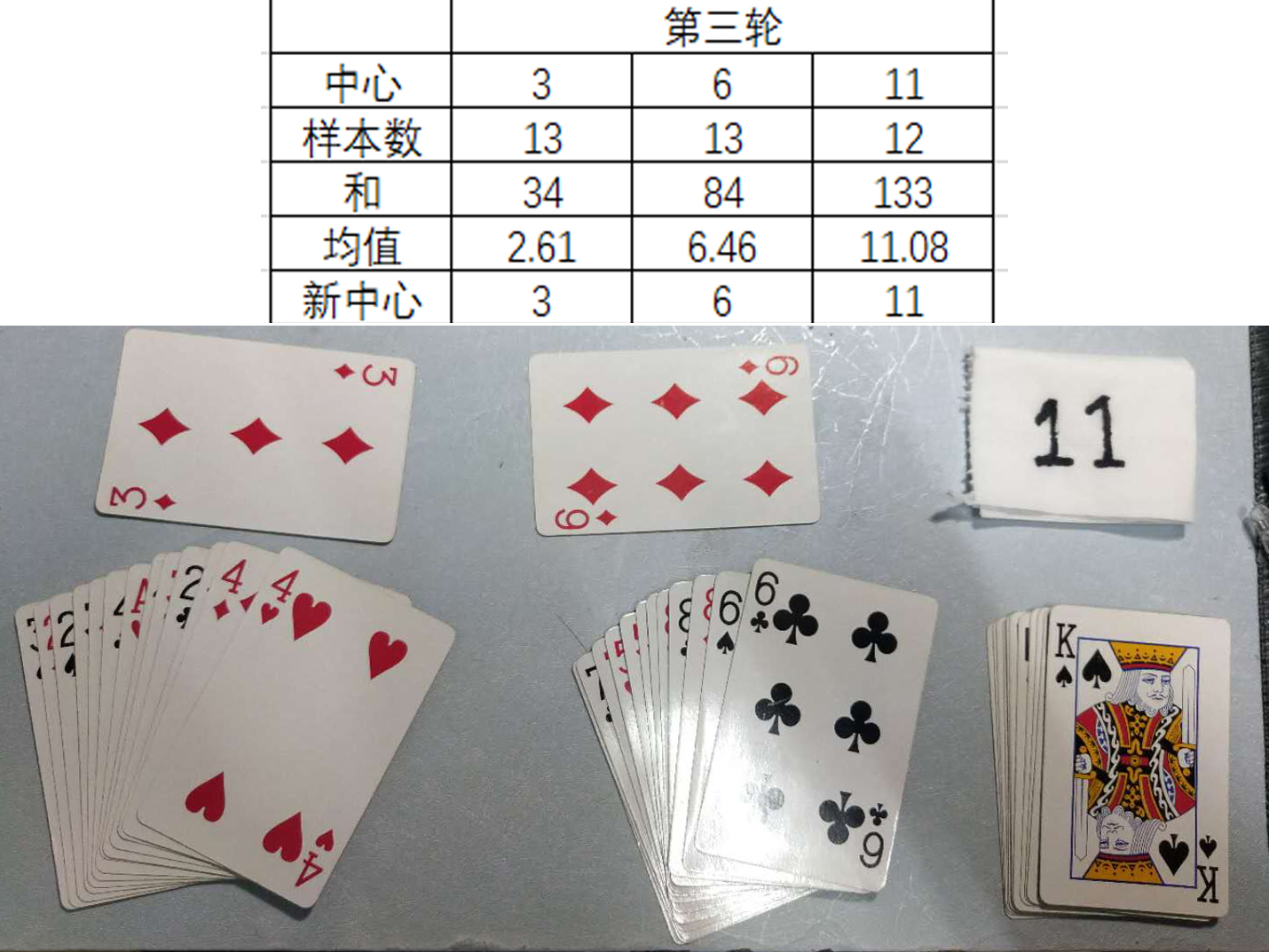
1) 扑克牌手动演练k均值聚类过程:>30张牌,3类


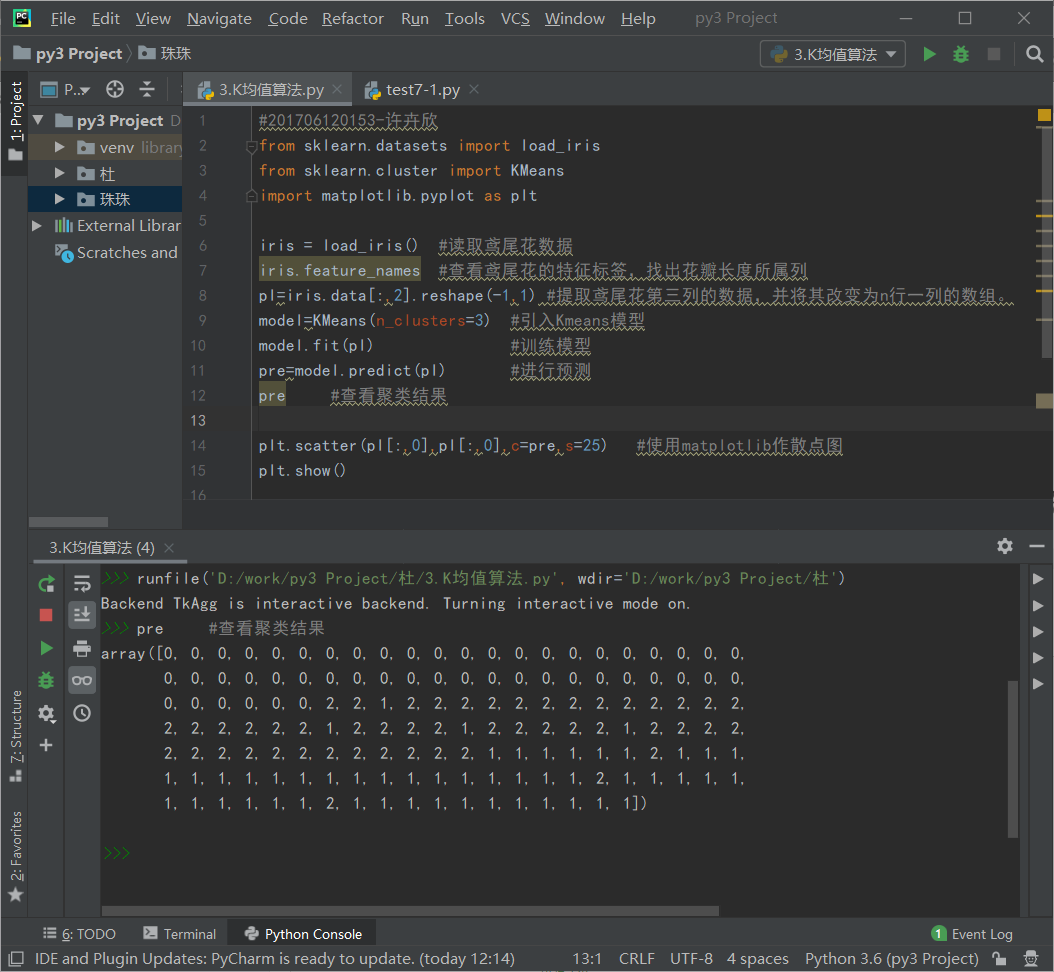
3) 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
代码:
#201706120153-许卉欣 from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt iris = load_iris() #读取鸢尾花数据 iris.feature_names #查看鸢尾花的特征标签,找出花瓣长度所属列 pl=iris.data[:,2].reshape(-1,1) #提取鸢尾花第三列的数据,并将其改变为n行一列的数组。 model=KMeans(n_clusters=3) #引入Kmeans模型 model.fit(pl) #训练模型 pre=model.predict(pl) #进行预测 pre #查看聚类结果 plt.scatter(pl[:,0],pl[:,0],c=pre,s=25) #使用matplotlib作散点图 plt.show()
结果:
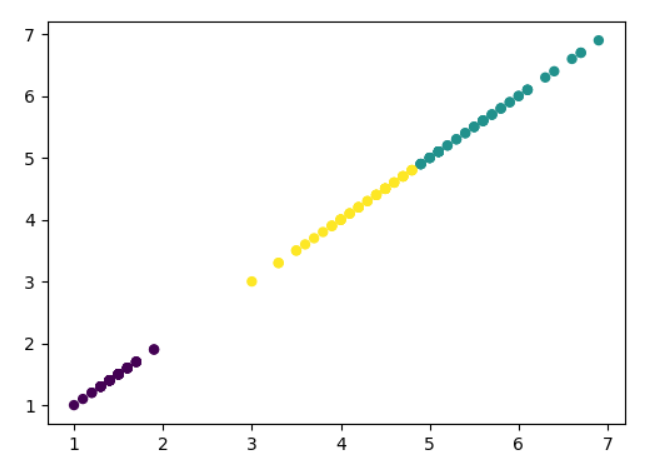
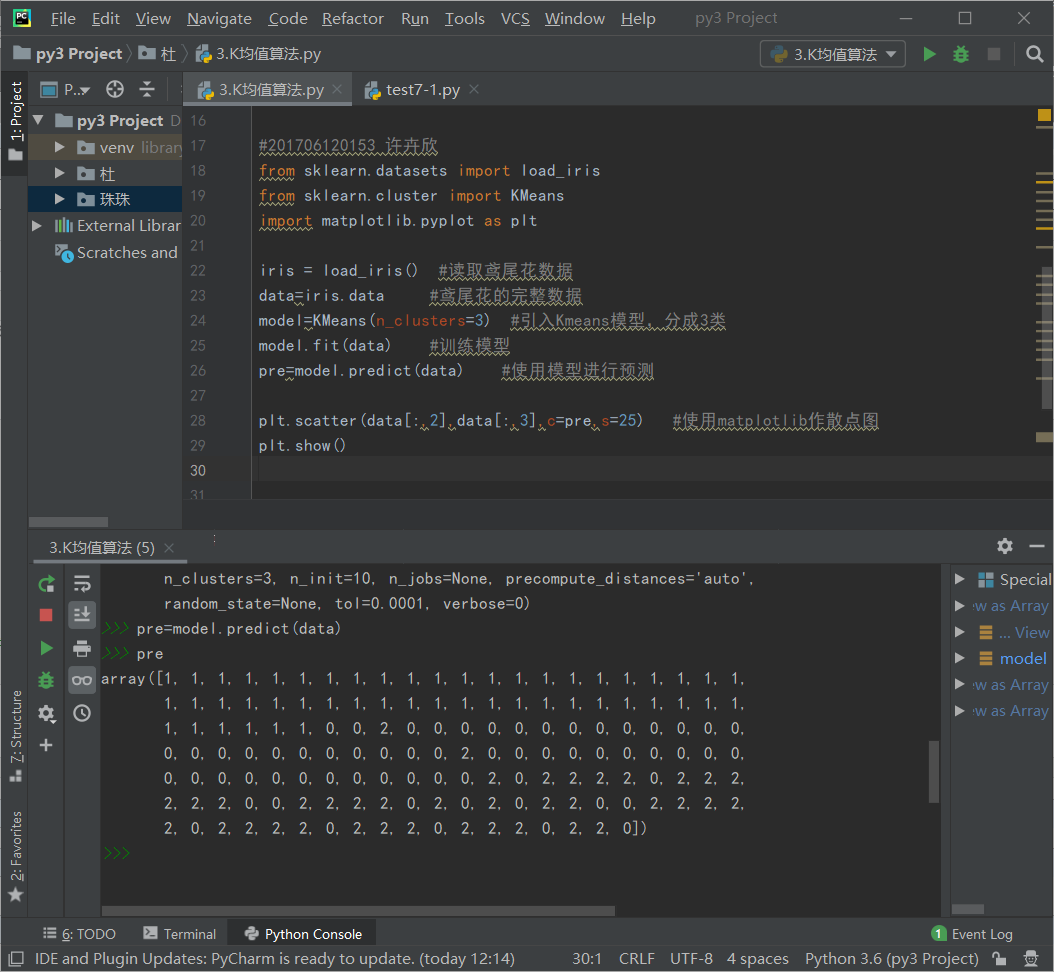
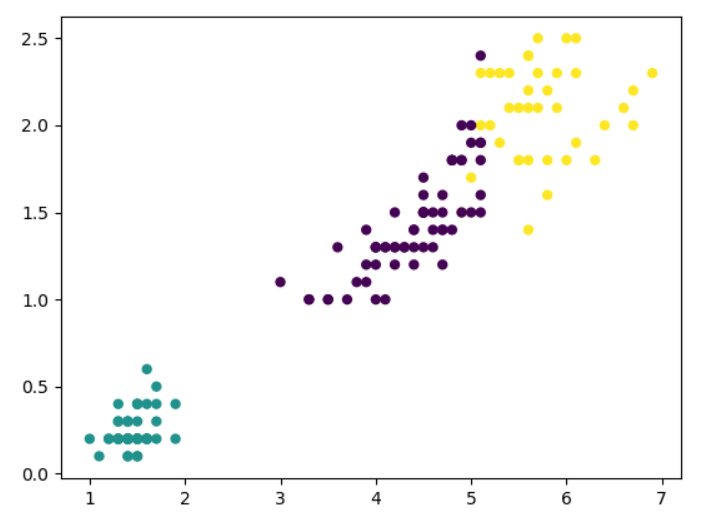
4).鸢尾花完整数据做聚类并用散点图显示.
代码:
#201706120153 许卉欣 from sklearn.datasets import load_iris from sklearn.cluster import KMeans import matplotlib.pyplot as plt iris = load_iris() #读取鸢尾花数据 data=iris.data #鸢尾花的完整数据 model=KMeans(n_clusters=3) #引入Kmeans模型,分成3类 model.fit(data) #训练模型 pre=model.predict(data) #使用模型进行预测 plt.scatter(data[:,2],data[:,3],c=pre,s=25) #使用matplotlib作散点图 plt.show()
结果:
5)想想k均值算法中以用来做什么?
K-means算法通常可以应用于维数、数值都很小且连续的数据集,比如:从随机分布的事物集合中将相同事物进行分组。
可以做文档分类器、客户群体分类、物品传输的优化也可以使用城市中特定地区的相关犯罪数据,分析犯罪类别、犯罪地点以及两者之间的关联,可以对城市或区域中容易犯罪的地区做高质量的勘察。