以前爬的数据量都有点少了,所以现在写个爬房天下全站数据爬虫来,用redis进行URL的去重处理,采用mysql储存清洗过后房产数据,采用线程池来进行调度,进行多线程爬取
后面会用scrapy框架做分布式集群来爬取数据,做完分布式爬虫就差不多了,后面就是scrapy深入研究和数据系统开发的学习
下面是房天下所有地区二手房和新房的URL,为后续爬取提供起始URL,后续会继续优化代码,感觉代码有点不够稳:
1 import requests 2 from lxml import etree 3 4 5 class Ftx_newhouse_Secondhandhouse(object): 6 7 headers = { 8 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36', 9 'Cookie': 'global_cookie=5n55ylc24xzrdp58gka2fm0mx2lj4mqfqak; Integrateactivity=notincludemc; vh_newhouse=3_1499483589_17454%5B%3A%7C%40%7C%3A%5D9af16b0d610e2cdd596b0d5a35400fbd; newhouse_user_guid=925B3734-6802-3162-165C-B593DAA860F1; recentViewlpNew_newhouse=3_1502607112_9948%5B%3A%7C%40%7C%3A%5D54e263288e4374965795dfe7c94c7fd3; city=heyuan; polling_imei=232d98985399f89e; token=59c66a51681142018630f1745e1e739f; Captcha=6E6B7334505855746454384A743161514A46696B346D577833476C613647745662647355494E7570596D4C52612B564F45473832462B59674B5A6E504C63386A34614767326774426455773D; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; sfut=33A48A581B218095B1D7CE492BDDCA86292F2A06B82634CBDD1201D2545F42EE4B54A2BC1247390DE02741E7CA2C9A911EA425B693C59EC2D62EDD7A4D70012C0F8DEE007CB20A5E2A74C8A9B17D4A8E3A7698ADDEAEC479D29D9DC82BC746FB; passport=usertype=1&userid=100371905&username=huangsonghui&password=&isvalid=1&validation=; agent_validation=a=0; __utma=147393320.331855580.1499000907.1504415980.1508935988.27; __utmb=147393320.49.10.1508935988; __utmc=147393320; __utmz=147393320.1508935988.27.21.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; unique_cookie=U_35b7j0utahefmuagw4fol4w8y1bj971iz3h*14' 10 11 } 12 13 def __init__(self): 14 self.url = 'http://newhouse.fang.com/house/s/' 15 self.s = requests.session() 16 17 18 def Newhouse_ftx(self): 19 try: 20 response = self.s.post(self.url,headers=self.headers,verify=False) 21 except Exception as e: 22 print('error:',e) 23 response.encoding = 'gb2312' 24 urls = etree.HTML(response.text) 25 xf_adress = urls.xpath('//div[@class="city20141104"]/div[3]/a/text()|' 26 '//div[@class="city20141104"]/div[4]/a/text()|' 27 '//div[@class="city20141104"]/div[5]/a/text()' 28 ) 29 xf_url = urls.xpath('//div[@class="city20141104"]/div[3]/a/@href|' 30 '//div[@class="city20141104"]/div[4]/a/@href|' 31 '//div[@class="city20141104"]/div[5]/a/@href' 32 ) 33 34 return (dict(zip(xf_adress,xf_url))) 35 36 def Secondhandhouse_ftx(self): 37 self.url = 'http://esf.sh.fang.com/newsecond/esfcities.aspx' 38 try: 39 html = requests.get(self.url,headers=self.headers,timeout=4) 40 except Exception as e: 41 print('error:',e) 42 html.encoding = 'gb2312' 43 Secondhandhouse_urls = etree.HTML(html.text) 44 xf_url = Secondhandhouse_urls.xpath('//div[@class="onCont"]/ul/li/a/text()') 45 xf_adress = Secondhandhouse_urls.xpath('//div[@class="onCont"]/ul/li/a/@href') 46 dictx = dict(zip(xf_url,xf_adress)) 47 return dictx
下面是爬取房产数据代码:
1 import requests,redis,pymysql 2 from mywed.fangtianxia.url import Ftx_newhouse_Secondhandhouse 3 from lxml import etree 4 #from PyMysqlPool import ConnectionPool 5 from concurrent.futures import ThreadPoolExecutor 6 import re,os,time,sys 7 import redis,random 8 from mywed.fangtianxia.logs import log_run 9 10 info_error = log_run() 11 Secondhandhouse_urls_set = {'http://esf.hbjs.fang.com'} 12 dr = Ftx_newhouse_Secondhandhouse() 13 w = dr.Secondhandhouse_ftx() 14 for i in w.values(): 15 Secondhandhouse_urls_set.add(i) 16 #print(Secondhandhouse_urls_set) 17 18 class Secondhandhouse(object): 19 20 def __init__(self): 21 22 self.redis = redis.Redis(host='127.0.0.1',port=int(6379)) 23 headers = { 24 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36', 25 'Cookie': 'global_cookie=5n55ylc24xzrdp58gka2fm0mx2lj4mqfqak; Integrateactivity=notincludemc; recentViewlpNew_newhouse=3_1502607112_9948%5B%3A%7C%40%7C%3A%5D54e263288e4374965795dfe7c94c7fd3; sfut=33A48A581B218095B1D7CE492BDDCA86292F2A06B82634CBDD1201D2545F42EE4B54A2BC1247390DE02741E7CA2C9A911EA425B693C59EC2D62EDD7A4D70012C0F8DEE007CB20A5E2A74C8A9B17D4A8E3A7698ADDEAEC479D29D9DC82BC746FB; passport=usertype=1&userid=100371905&username=huangsonghui&password=&isvalid=1&validation=; searchLabelN=1_1508938813_1512%5B%3A%7C%40%7C%3A%5D3c43a54360cca7c94279c4b5b0205f0c; searchConN=1_1508938813_1781%5B%3A%7C%40%7C%3A%5D05ed4bc0dfcc9f21a32762d6f6d4fb58; new_search_uid=fba148bd42d8c17f17727aba9343de53; newhouse_user_guid=925B3734-6802-3162-165C-B593DAA860F1; vh_newhouse=3_1499483589_17454%5B%3A%7C%40%7C%3A%5D9af16b0d610e2cdd596b0d5a35400fbd; showAdgz=1; indexAdvLunbo=lb_ad1%2C0; __utmt_t0=1; __utmt_t1=1; token=454574fb7c6b43349dcf488232ff5b28; __utmt_t2=1; sf_source=; s=; city=gz; __utma=147393320.331855580.1499000907.1509864975.1509973025.46; __utmb=147393320.8.10.1509973025; __utmc=147393320; __utmz=147393320.1509973025.46.32.utmcsr=lan.wayos.com:8888|utmccn=(referral)|utmcmd=referral|utmcct=/ddate.htm; unique_cookie=U_844in4blp5038dilu98wve9qn1vj9h4j332*17' 26 } 27 28 def get_newhouse_data(self,url): 29 30 for num in range(30): 31 print('paqu:%s'%(num)) 32 #second_url = url + '/house/i3' + str(num) 33 #self.redis.set('url',second_url) 34 try: 35 while True: 36 time.sleep(1) 37 reponse = requests.get(url,headers=self.headers) 38 info_error.File_enter_info('下载成功') 39 reponse.encoding = 'gbk' 40 #print(len(reponse.text)) 41 if len(str(reponse.text)) <=1700: 42 print('cookies已经过期') 43 if reponse.status_code ==200: 44 break 45 else: 46 print('restart donwing ......') 47 except Exception as e: 48 info_error.File_enter_error(e) 49 select = etree.HTML(str(reponse.text)) 50 51 if not len(select.xpath('//a[@id="PageControl1_hlk_next"]/text()')): 52 break 53 else: 54 content_list = select.xpath('//dd[@class="info rel floatr"]') 55 #print(content_list) 56 for i in content_list: 57 title = i.xpath('./p[1]/a/@title') 58 link = i.xpath('./p[1]/a/@href') 59 content = ' '.join(i.xpath('./p[2]/text()'))#坑在这里好久 60 name = i.xpath('./p[3]/a/span/text()') 61 adress = i.xpath('./p[3]/span/text()') 62 63 #print(content) 64 size = select.xpath('//div[@class="area alignR"]/p[1]/text()') 65 #print(size) 66 average_price = select.xpath('//p[@class="danjia alignR mt5"]/text()') 67 #print(average_price) 68 sum_price_list = select.xpath('//p[@class="mt5 alignR"]') 69 sum_price = select.xpath('//p[@class="mt5 alignR"]/span[1]/text()') 70 #print(sum_price) 71 datas_list = list(zip(title,link,name,adress,size,average_price,sum_price)) 72 tuplese = list(datas_list[0]) 73 if ' ' in tuplese: 74 tuplese.remove(' ') 75 #print(tuplese) 76 yield tuplese#返回一个生成器 78 79 def savemysql(self,url): 82 s = self.get_newhouse_data(url) 83 #print(list(s)) 84 for tuples in list(s): 85 self.conn = pymysql.connect(host='127.0.0.1', user='root', passwd='123456789', db='data', port=3306, 86 charset='utf8') 87 self.cur = self.conn.cursor() 88 #print(tuples) 89 sql = '''insert into ftx_datas(title,link,name,adress,size,average_price, sum_price)values("%s","%s","%s","%s","%s","%s","%s")''' %(tuples[0], tuples[1], tuples[2], tuples[3], tuples[4], tuples[5], tuples[6]) 90 self.cur.execute(sql) 91 self.cur.close() 92 self.conn.commit() 93 self.conn.close() 94 return 'ok' 95 96 97 if __name__ =="__main__": 98 t = Secondhandhouse() 99 s= t.savemysql('http://esf.gz.fang.com') 100 #pool = ThreadPoolExecutor(50)#开50个线程来爬,会自动完成爬取任务的调度 101 #f = pool.map(s, Secondhandhouse_urls_set) 102 #t.get_newhouse_data('http://esf.gz.fang.com') 103 104 #s = t.get_newhouse_data
下面是建表代码:
create table ftx_datas( id int not null auto_increment, city varchar(100) null, title varchar(100) not null, link varchar(100) not null, content varchar(100) null, name varchar(100) not null, adress varchar(100) not null, size varchar(100) not null, average_price varchar(100) not null, sum_price varchar(100) not null, PRIMARY KEY (id ) );
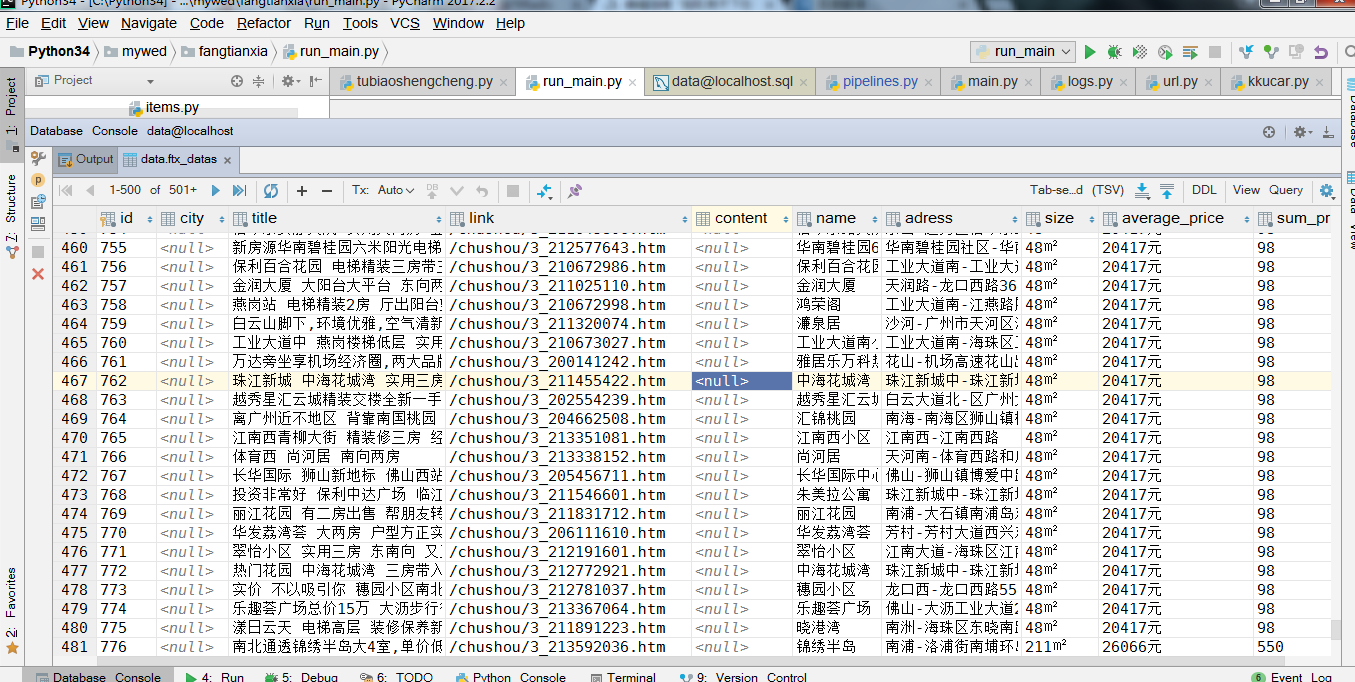
下面是运行代码后爬的的数据,已经保存在mysql了: