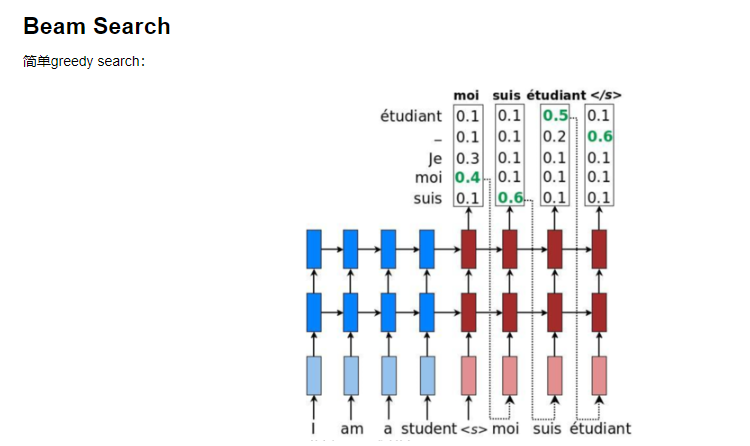
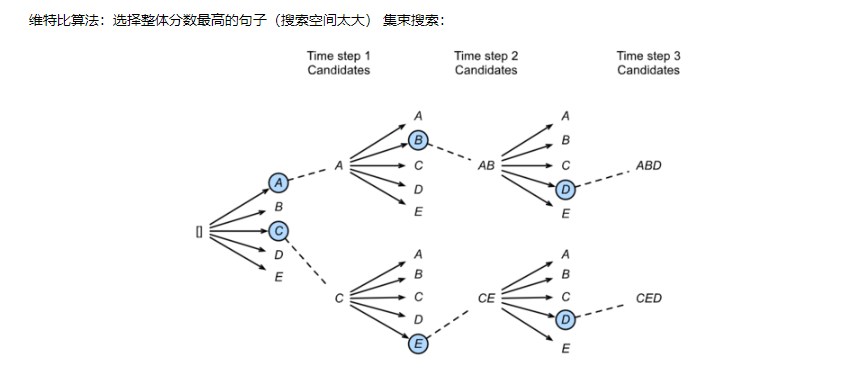
task0401.机器翻译及相关技术






课后习题

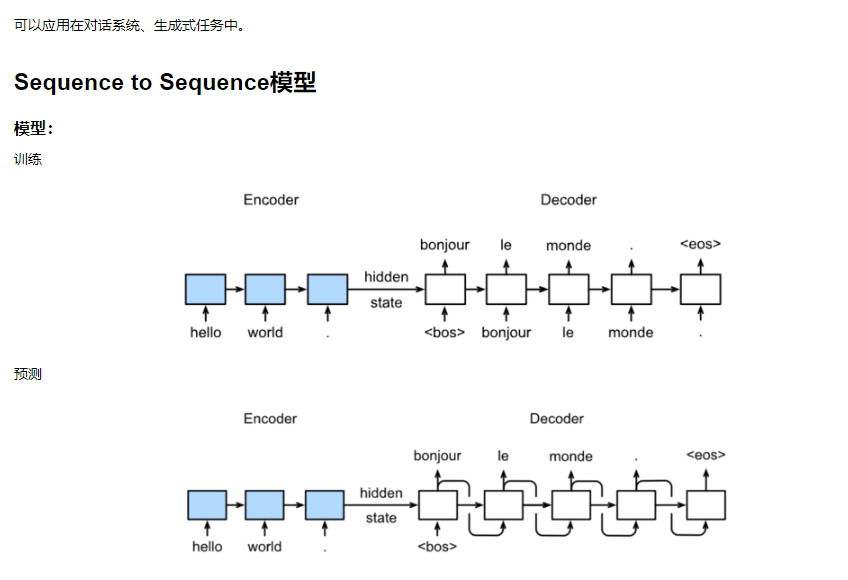
task0402.注意力机制与Seq2seq模型
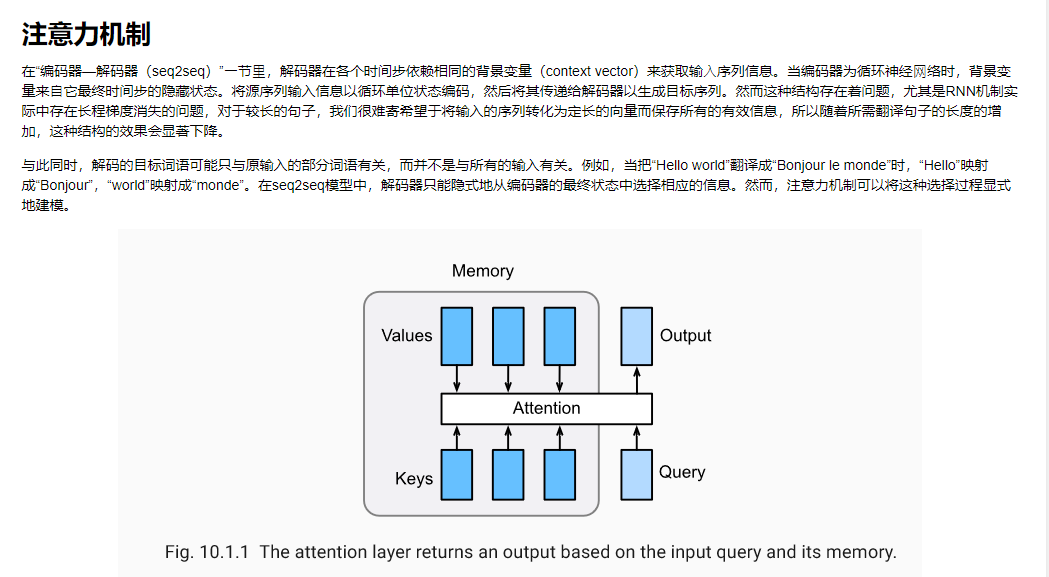

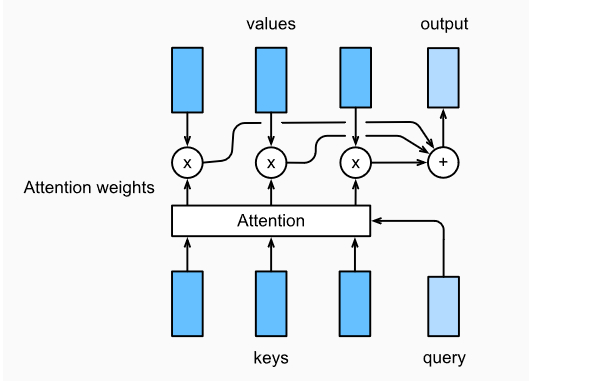
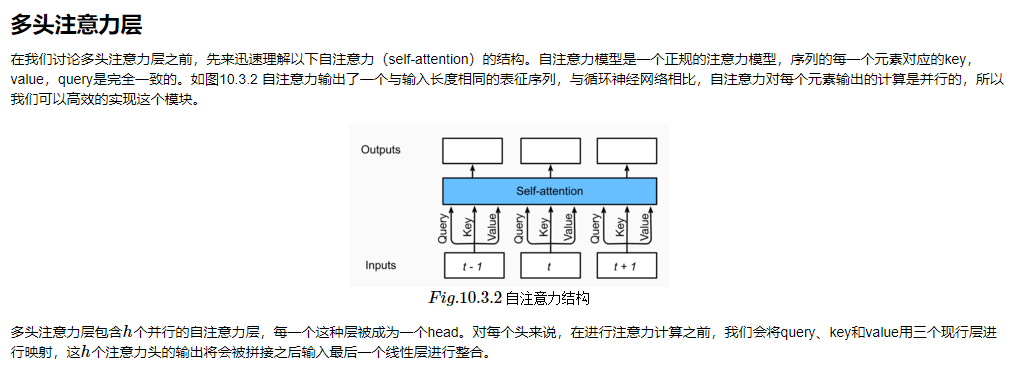
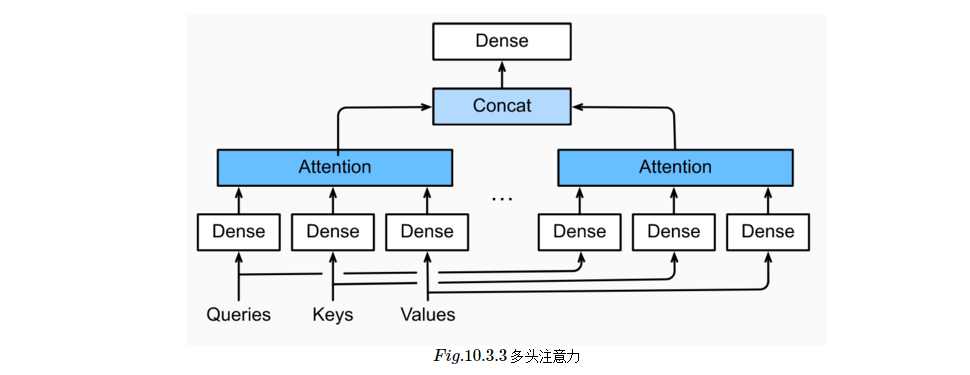
不同的attetion layer的区别在于score函数的选择,在本节的其余部分,我们将讨论两个常用的注意层 Dot-product Attention 和 Multilayer Perceptron Attention;随后我们将实现一个引入attention的seq2seq模型并在英法翻译语料上进行训练与测试。
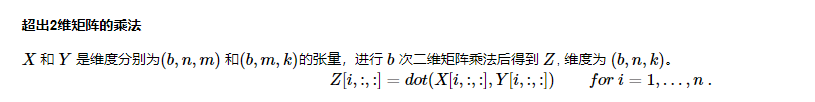

# Save to the d2l package.
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# query: (batch_size, #queries, d)
# key: (batch_size, #kv_pairs, d)
# value: (batch_size, #kv_pairs, dim_v)
# valid_length: either (batch_size, ) or (batch_size, xx)
def forward(self, query, key, value, valid_length=None):
d = query.shape[-1]
# set transpose_b=True to swap the last two dimensions of key
scores = torch.bmm(query, key.transpose(1,2)) / math.sqrt(d)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
print("attention_weight
",attention_weights)
return torch.bmm(attention_weights, value)
- 测试
现在我们创建了两个批,每个批有一个query和10个key-values对。我们通过valid_length指定,对于第一批,我们只关注前2个键-值对,而对于第二批,我们将检查前6个键-值对。因此,尽管这两个批处理具有相同的查询和键值对,但我们获得的输出是不同的。
atten = DotProductAttention(dropout=0)
keys = torch.ones((2,10,2),dtype=torch.float)
values = torch.arange((40), dtype=torch.float).view(1,10,4).repeat(2,1,1)
atten(torch.ones((2,1,2),dtype=torch.float), keys, values, torch.FloatTensor([2, 6]))

# Save to the d2l package.
class MLPAttention(nn.Module):
def __init__(self, units,ipt_dim,dropout, **kwargs):
super(MLPAttention, self).__init__(**kwargs)
# Use flatten=True to keep query's and key's 3-D shapes.
self.W_k = nn.Linear(ipt_dim, units, bias=False)
self.W_q = nn.Linear(ipt_dim, units, bias=False)
self.v = nn.Linear(units, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, query, key, value, valid_length):
query, key = self.W_k(query), self.W_q(key)
#print("size",query.size(),key.size())
# expand query to (batch_size, #querys, 1, units), and key to
# (batch_size, 1, #kv_pairs, units). Then plus them with broadcast.
features = query.unsqueeze(2) + key.unsqueeze(1)
#print("features:",features.size()) #--------------开启
scores = self.v(features).squeeze(-1)
attention_weights = self.dropout(masked_softmax(scores, valid_length))
return torch.bmm(attention_weights, value)
- 测试
尽管MLPAttention包含一个额外的MLP模型,但如果给定相同的输入和相同的键,我们将获得与DotProductAttention相同的输出
atten = MLPAttention(ipt_dim=2,units = 8, dropout=0)
atten(torch.ones((2,1,2), dtype = torch.float), keys, values, torch.FloatTensor([2, 6]))



课后习题


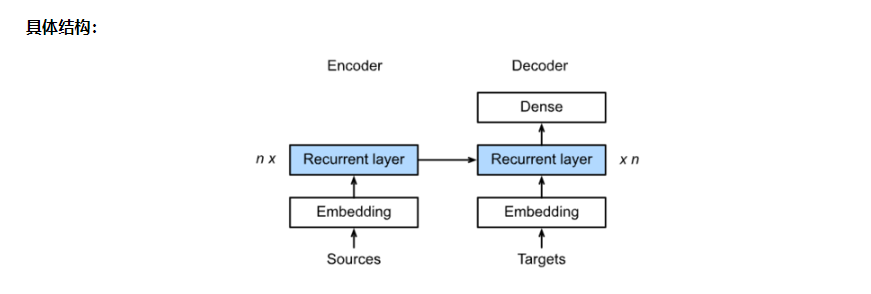
task0403.Transformer




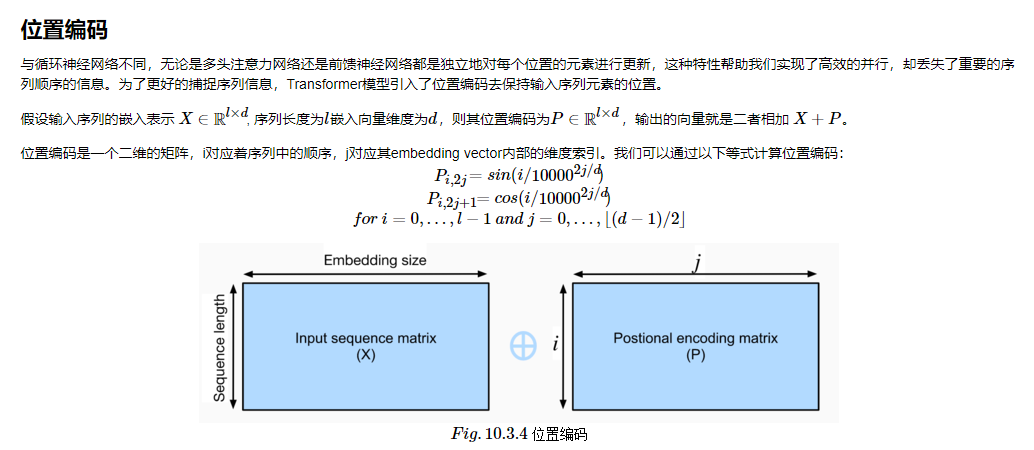
class PositionalEncoding(nn.Module):
def __init__(self, embedding_size, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
self.P = np.zeros((1, max_len, embedding_size))
X = np.arange(0, max_len).reshape(-1, 1) / np.power(
10000, np.arange(0, embedding_size, 2)/embedding_size)
self.P[:, :, 0::2] = np.sin(X)
self.P[:, :, 1::2] = np.cos(X)
self.P = torch.FloatTensor(self.P)
def forward(self, X):
if X.is_cuda and not self.P.is_cuda:
self.P = self.P.cuda()
X = X + self.P[:, :X.shape[1], :]
return self.dropout(X)

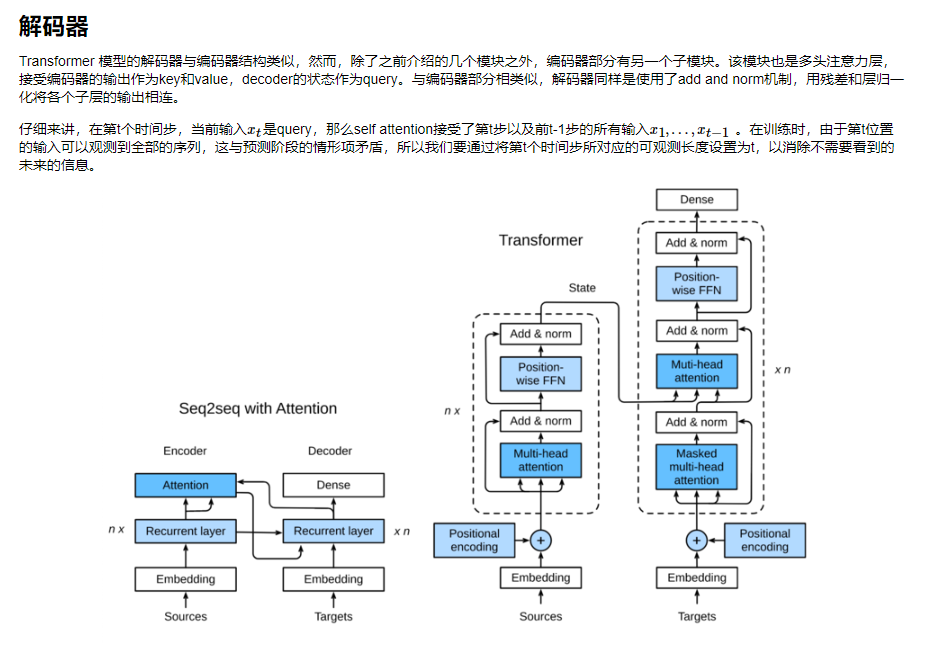
课后习题