itemKNN发展史----推荐系统的三篇重要的论文解读
本文用到的符号标识

1、Item-based CF
基本过程:
- 计算相似度矩阵
- Cosine相似度
- 皮尔逊相似系数
- 参数聚合进行推荐
根据用户项目交互矩阵 (A) 计算相似度矩阵 (W):
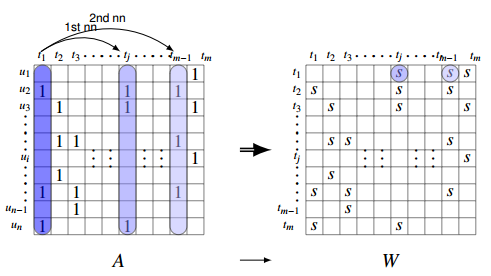
这样,用户对整个项目列表的偏好值可以如下计算:
[{ { ilde a_i}^T}={ a_i^T} imes W
]
例如,对于 j 号物品,用户的偏好值如此计算:
[{ { ilde a_{(u,j)}}}=sum_{iin { a_u^T}}{ { a_{(u,i)}}}W_{(i,j)}
]
由于交互矩阵 (A) 的稀疏性,矩阵 (W) 也应该是稀疏的。
2、SLIM: Sparse Linear Methods for Top-N Recommender Systems
- 现有的两种推荐系统
- 基于邻居的协同过滤(代表,item-based CF)
【特点】:能快速生成推荐,推荐质量不高,没有从数据中学习。 - 基于模型的方法(代表,矩阵分解 MF 模型)
【特点】:模型训练慢,推荐质量高。
- 基于邻居的协同过滤(代表,item-based CF)
相比于以上两种方法,SLIM 既高效,推荐质量又高。
2. SLIM 关键思想
- 保留 item-KNN 的稀疏矩阵 (W) 的特点。
- 通过从 (A) 中自学习矩阵 (W) 来提高推荐性能。
3. 学习过程
[L(cdot) =frac{1}{2} ||A-AW||_F^2+frac{eta}{2} ||W||_F^2+lambda||W||_1 $$$$ {subject to }Wgeq0, {diag}(W)=0
]
其中:
- ({diag} = 0) 约束同一项目与自己的相似度不加入计算。
- (l1) 正则化约束使得矩阵$ W $稀疏
- 弗罗贝尼乌斯范数类似于矩阵的平方,用来防止数据过拟合
可以看到,实际上这个过程是可以并行执行的。
SLIM 的 paper 中使用了坐标下降和软阈值的方法来实现问题的求解。
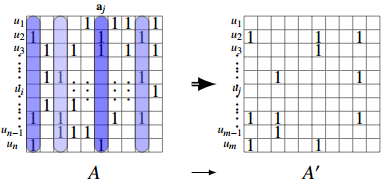
使用特征选择可以减少 SLIM 的计算量。文章中使用了item-KNN 的方式选择了与待估项目相似度靠前的作为特征选择方式。
3、FISM:Factor item Similarity Models for Top-N Recommender Systems
论文主要完成了以下四个工作:
- 将基于项目的隐因子的方法扩展到 top-N 问题,这使得它们能够有效地处理稀疏数据集;
- 使用结构方程建模方法评估基于项目的隐因子方法。
- 同时使用均方误差和排名误差来评估该模型
- 观察各种参数的影响,因为与偏置,邻居协议和引起模型的稀疏性有关。
- 相关工作
- SLIM
- NSVD(rating prediction)[hat r_{ui}=b_u+b_i+sum_{jin mathbb{R}_u^+} {p}_j q_i^T ]扩展了item-kNN,学习item之间的相似度。使用每个项目的隐因子内积作为相似度。
- SVD++
- 动机与模型比较
- 传统的 item-KNN 包括 SLIM 对交互矩阵 (A) 的处理按行或列独立,因此,如果两个 item 都没有评价记录,则这两个处理方法都会将两个 item 的相似度置为 0 ,这是不合理的。
- MF 模型考虑到了这个问题,但是它的效果不如 SLIM。
与 NSVD 和 SVD++ 比较:
- FISM 解决 Top-N;SVD 解决 rating prediction
- FISM 采用基于结构方程建模的回归方法。
- 评估某个 item 时,不使用用户对于该 item 的评分信息。
P.S. 这影响了相似度矩阵对角线元素对评估的影响,FISM评估时去掉了对角线元素,而SVD等保留了,这使得隐因子很大的情况下FISM表现得比 SVD 好