小小小小白刚刚开始学机器学习
参考博客吴恩达机器学习ex1 python实现
需要用到的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- 机器学习算法中大部分计算都是用numpy库实现的
numpy库的基础操作参考博客https://blog.csdn.net/codedz/article/details/82869370
numpy用户手册NumPy user guide - pandas库是一个强大的用于分析结构化数据的工具集,基础是numpy
在这里用于处理CSV文件 - matplot是python的绘图库,搭配numpy一起使用
1.简单练习
输出5*5的单位矩阵
A = np.eye(5)
print(A)
np.eye()函数:返回一个对角线上全是1,其他全为0的二维数组。
输出
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
2.单变量的线性回归
根据城市人口数量,预测开小吃店的利润
第一列是城市人口数量,第二列是在该城市开小吃店的利润
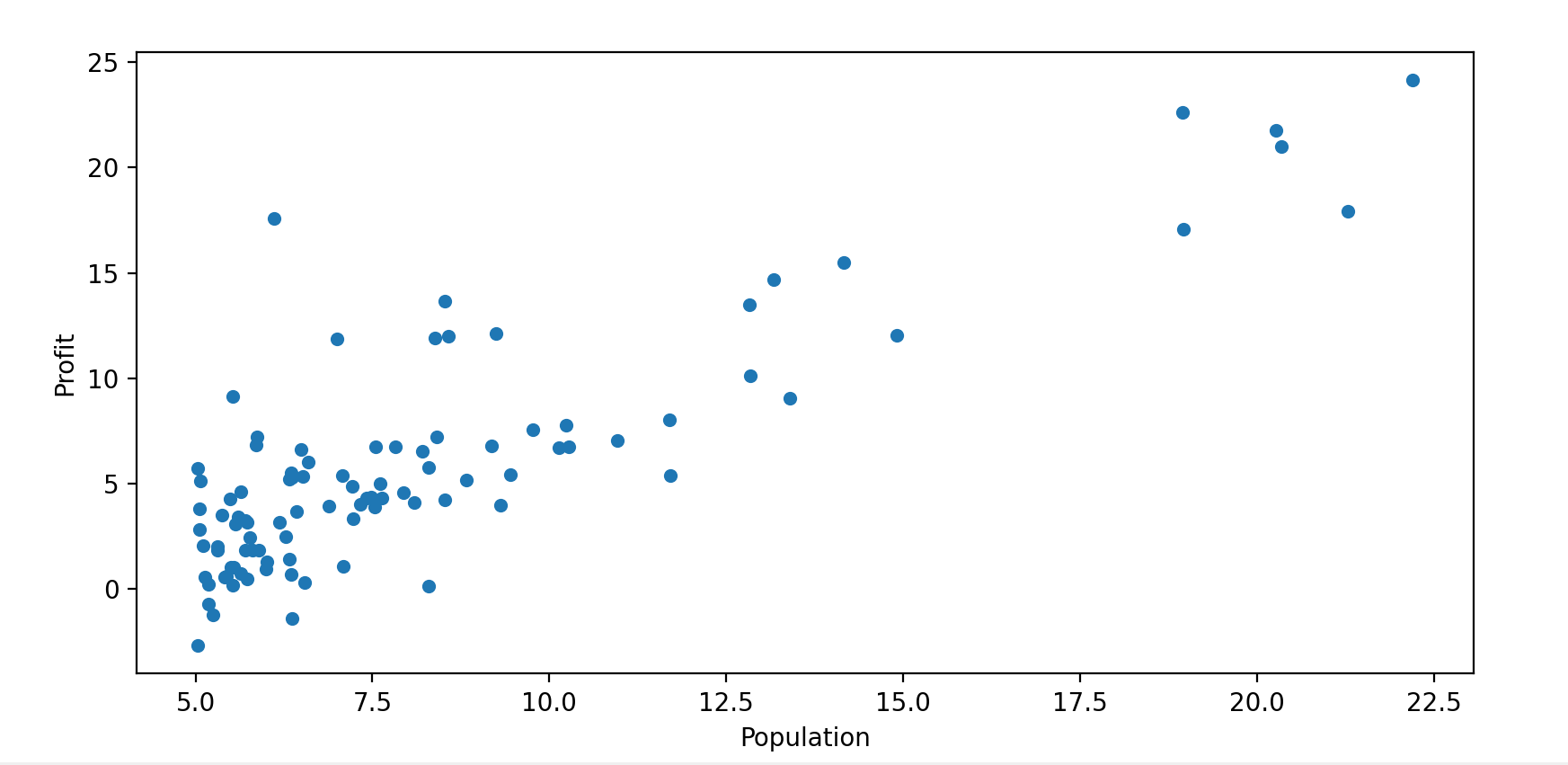
2.1 Plotting the Data
# 用绝对路径有问题,不知道为什么,求解答
# data = pd.read_csv('D:\ML\Machine Learning\ex1data1.csv', header=None, names=['Population', 'Profit'])
data = pd.read_csv('ex1data1.csv', header=None, names=['Population', 'Profit'])
print(data.head()) # 打印前五行
data.plot.scatter('Population', 'Profit') # 绘制散点图
plt.show()
2.2 Gradient Descent
在已有的数据集上,训练线性回归的参数θ
2.2.1 代价函数公式
def costFunc(X, y, theta):
inner = np.power((X @ theta) - y, 2)
return np.sum(inner) / (2*len(X))
python3.5以后@为一个操作符,意为矩阵-向量乘法
2.2.2 准备参数X,y,θ
# 在X矩阵中加一列全为1,方便计算
data.insert(0, 'Ones', 1)
# 初始化X和y
cols = data.shape[1]
X = data.iloc[:, 0:-1] # 获取除最后一列
y = data.iloc[:, cols-1:cols] # 获取最后一列
X = np.array(X.values) # 转化为数组类型
y = np.array(y.values)
print(X.shape) # X和y的维度
y.reshape(len(y), 1)
print(y.shape)
theta = np.zeros((2, 1)) # 初始化θ
print(theta.shape)
firstCost = costFunc(X, y, theta)
print(firstCost)
iloc:即index locate。iloc[行,列] iloc[:,0:-1]是获取前三列的意思(注:左闭右开)
iloc[:,-1]是获取最后一列
np.zeros()返回一个给定形状和类型的用0填充的数组
2.2.3 计算代价函数
firstCost = costFunc(X, y, theta)
print(firstCost)
由于θ初始为0,计算结果为32.07
2.2.4 梯度下降
def gradientDescent(X, y, theta, alpha, iters):
"""
计算梯度下降的参数
:param X:
:param y:
:param theta:
:param alpha: 学习率
:param iters: 迭代次数
:return: theta,costs
"""
costs = []
for i in range(iters):
theta = theta - (alpha / len(X) * X.T @ (X @ theta - y)) # 梯度下降的公式
cost = costFunc(X, y, theta)
costs.append(cost)
if i % 100 == 0:
print(cost)
return theta, costs
alpha = 0.02
iters = 1000
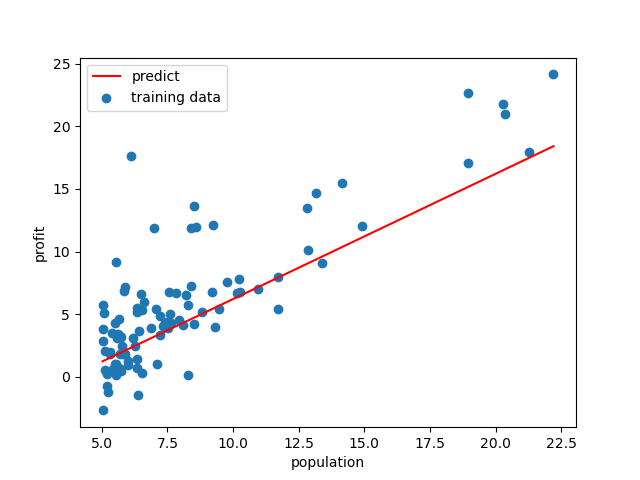
2.3 画出拟合后的直线
x = np.linspace(data.Population.min(), data.Population.max(), 100) # 从最小值到最大值的100个均匀的点
f = theta[0, 0] + x
fig, ax = plt.subplots() # 用来创建画布
ax.scatter(X[:, 1], y, label='training data')
ax.plot(x, f, 'r', label='predict')
ax.legend() # 设置图像位置
ax.set(xlabel='population', ylabel='profit') # 设置横纵坐标
plt.show() # 显示图像
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
返回[start,stop]范围内间隔均匀的num个数
拟合后的图像为
3.多变量线性回归
根据房屋大小和卧室数量预测房价
数据集中第一列是房屋大小,第二列是卧室数量,第三列是房价
3.1 特征归一化
根据观察数据。房屋大小的数值是卧室数量的1000倍,这样会导致梯度下降缓慢。归一化就是让每个样本减去平均值再除以标准差
data2 = pd.read_csv('ex1data2.csv', header=None, names=['Size', 'Bedrooms', 'Price'])
print(data2.head())
data2 = (data2 - data2.mean()) / data2.std()
print(data2.head())
data2.mean()是均值,data2.std()是标准差
3.2梯度下降
data2.insert(0, 'Ones', 1)
col = data2.shape[1] # 获取列的长度
X = data2.iloc[:, 0:-1]
y = data2.iloc[:, col-1:col]
X = np.array(X.values) # 转化为数组类型
y = np.array(y.values)
y = y.reshape(len(y), 1)
theta = np.zeros((3, 1))
alpha = 0.01
iters = 1500
theta, costs = gradientDescent(X, y, theta, alpha, iters)
print(theta)
最终theta结果
[[-1.00034591e-16]
[ 8.84042349e-01]
[-5.24551809e-02]]
3.3正规方程
梯度下降需要选择学习率,进行多次迭代。适用于特征变量很多的数据集。
正规方程不需要选学习率,不需迭代。但当特征变量很多时速度会很慢。
def NormalEq(X, y , theta):
theta = np.linalg.inv(X.T@X) @ X.T @ y
return theta
theta = NormalEq(X, y, theta)
print(theta)
np.linalg.inv()是求逆矩阵
最终结果为:
[[-1.04083409e-16]
[ 8.84765988e-01]
[-5.31788197e-02]]