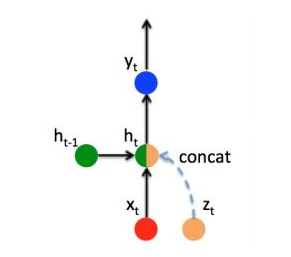
RNN序列编解码器
- 红色---输入,蓝色---输出
- 绿色----编、解码器
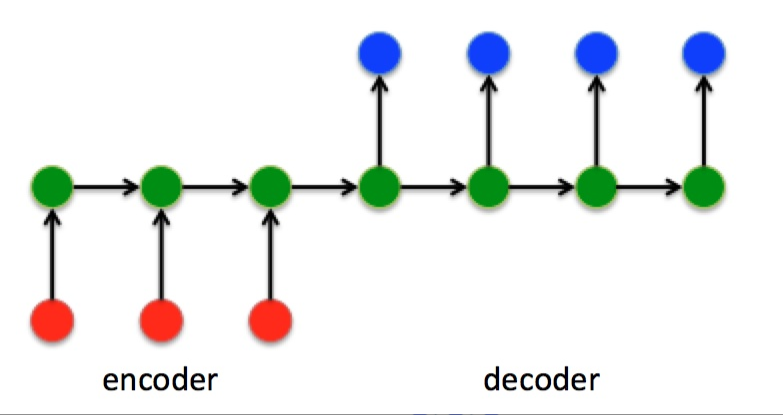
Sequence to Sequence模型
编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中,不断地将前一个时刻 [公式] 的输出作为后一个时刻 [公式] 的输入,循环解码,直到输出停止符为止。
优点:不再要求输出与输入有相同的时间长度
缺点:
- encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由Decoder解码。由于context包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。(如机器翻译问题,当要翻译的句子较长时,一个Context可能存不下那么多信息,就会造成精度的下降。)
- 如果按照上述方式实现,只用到了编码器的最后一个隐藏层状态,信息利用率低下。
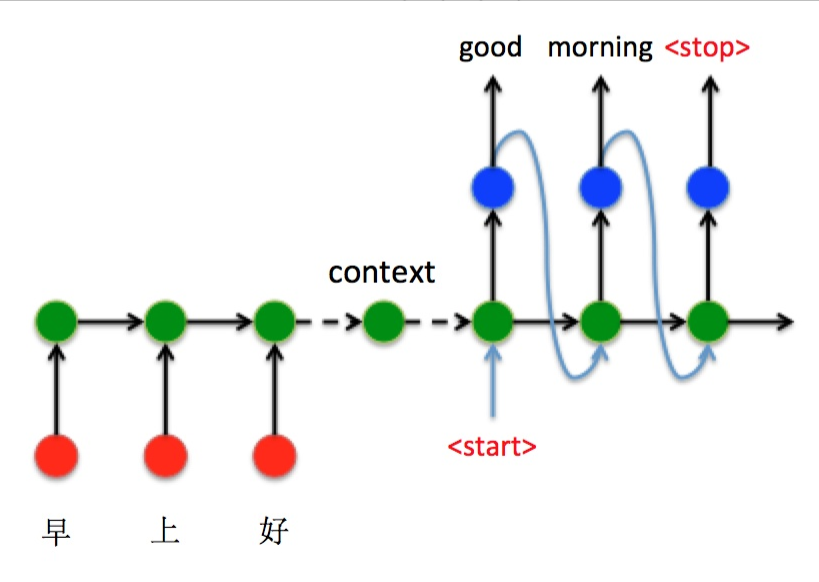
时间片输入的稀疏问题
一般通过嵌入向量(embedding)解决,如one_hot编码,但是可能会产生大量过于稀疏的输入。
解决办法:生成一个随机矩阵R,然后用embedding** * R做空间映射形成新的输入embedding_new
改进Seq2Seq结构(引入attention)
最好的切入角度就是:利用Encoder所有隐藏层状态 解决Context长度限制问题。
即将编码器的所有隐藏状态都作为解码器每个隐藏状态的一个输入。
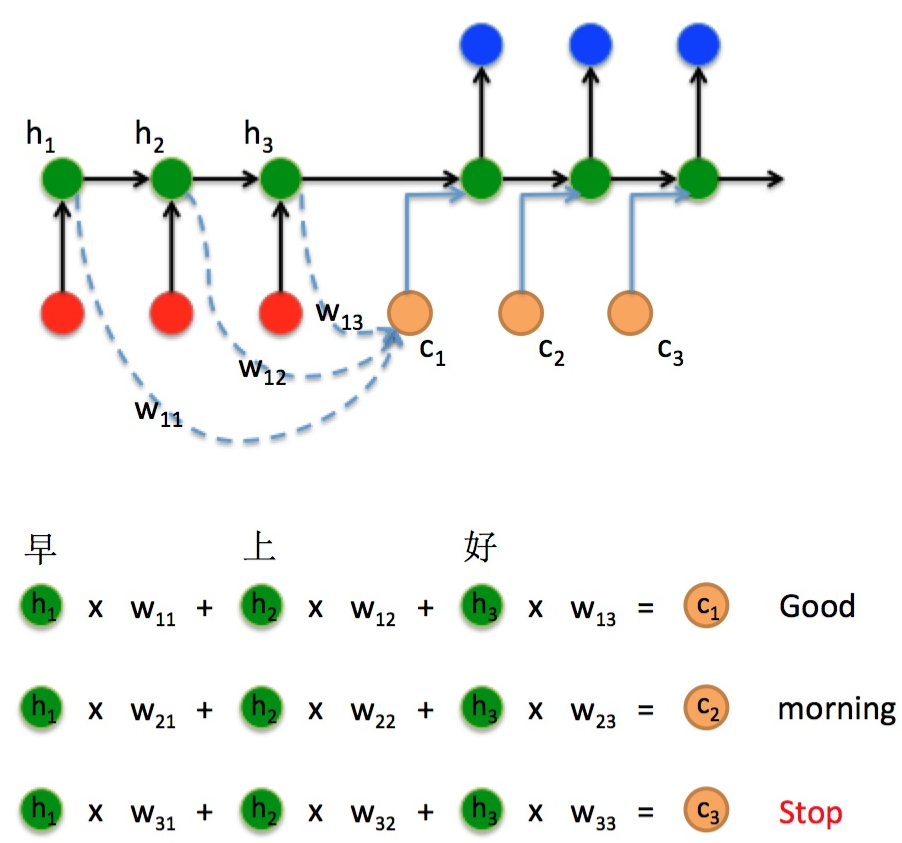
Attention机制本质
将的Encoder RNN隐藏层状态加权后获得权重向量,额外加入到Decoder中,给Decoder RNN网络添加额外信息,使其不再仅仅依赖编码器的最终上下文向量作为单一信息输入,从而使得网络有更完整的信息流。
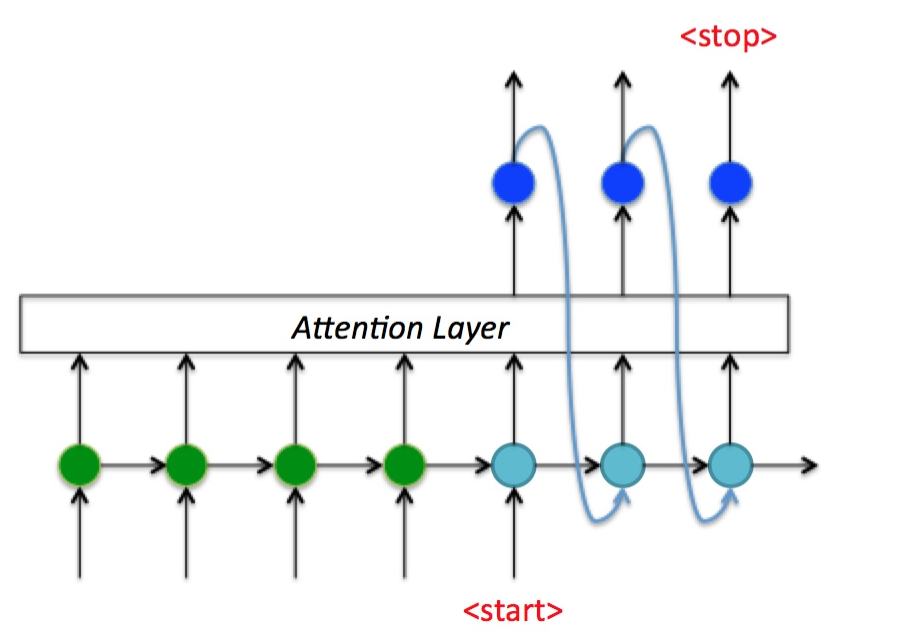
Luong-Attention给RNN网络添加额外信息的方式