unspervised learning -> Word Embedding
简单来说,目的就是将文本信息进行编码,变为及其可以识别的向量
单词的表示
人可以理解文字,但是对于机器来说,数字是更好理解的(因为数字可以进行运算),因此,我们需要把文字变成数字。
- 中文句子以“字”为单位。一句中文句子是由一个个字组成的,每个字都分别变成词向量,用一个向量vector来表示一个字的意思。
- 英文句子以“单词”为单位。一句英文句子是由一个个单词组成的,每个单词都分别变成词向量,用一个向量vector来表示一个单词的意思。
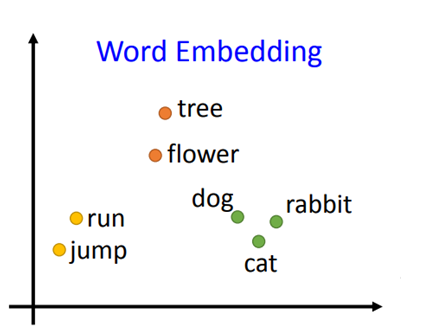
句子的表示
对于一句句子的处理,先建立字典,字典内含有每一个字所对应到的索引。比如:
- “I have a pen.” -> [1, 2, 3, 4]
- “I have an apple.” -> [1, 2, 5, 6]
得到句子的向量有两种方法:
- 直接用 bag of words (BOW) 的方式获得一个代表该句的向量。
- 我们已经用一个向量 vector 来表示一个单词,然后我们就可以用RNN模型来得到一个表示句子向量
1-of-N encoding
一个向量,长度为N,其中有1 11个是1,N − 1 N-1N−1个都是0,也叫one-hot编码,中文翻译成“独热编码”。
现在假设,有一句4个单词组成的英文句子“I have an apple.”,先把它变成一个字典:
“I have an apple.” -> [1, 2, 5, 6]
然后,对每个字进行 1-of-N encoding:
1 -> [1,0,0,0]
2 -> [0,1,0,0]
5 -> [0,0,1,0]
6 -> [0,0,0,1]这里的顺序是人为指定的,可以任意赋值,比如打乱顺序:
5 -> [1,0,0,0]
6 -> [0,1,0,0]
1 -> [0,0,1,0]
2 -> [0,0,0,1]1-of-N encoding非常简单,非常容易理解,但是问题是:
- 缺少字与字之间的关联性 (当然你可以相信 NN 很强大,它会自己想办法)
- 占用内存大:总共有多少个字,向量就有多少维,但是其中很多都是0,只有1个是1.
比如:200000(data)*30(length)*20000(vocab size) *4(Byte) = 4.8 ∗ 1 0 11 4.8*10^{11}4.8∗1011 = 480 GB
Bag of Words (BOW)
BOW 的概念就是将句子里的文字变成一个袋子装着这些词,BOW不考虑文法以及词的顺序。
比如,有两句句子:
1. John likes to watch movies. Mary likes movies too.
2. John also likes to watch football games.有一个字典:[ “John”, “likes”, “to”, “watch”, “movies”, “also”, “football”, “games”, “Mary”, “too” ]
在 BOW 的表示方法下,第一句句子 “John likes to watch movies. Mary likes movies too.” 在该字典中,每个单词的出现次数为:
- John:1次
- likes:2次
- to:1次
- watch:1次
- movies:2次
- also:0次
- football:0次
- games:0次
- Mary:1次
- too:1次
因此,“John likes to watch movies. Mary likes movies too.”的表示向量即为:[1, 2, 1, 1, 2, 0, 0, 0, 1, 1],第二句句子同理,最终两句句子的表示向量如下:
1. John likes to watch movies. Mary likes movies too. -> [1, 2, 1, 1, 2, 0, 0, 0, 1, 1]
2. John also likes to watch football games. -> [1, 1, 1, 1, 0, 1, 1, 1, 0, 0]之后,把句子的BOW输入DNN,得到预测值,与标签进行对比。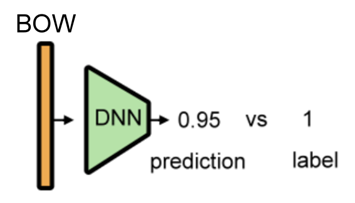
word embedding
词嵌入(word embedding),也叫词的向量化(word to vector),即把单词变成向量(vector)。训练词嵌入的方法有两种:
-
可以用一些方法 (比如 skip-gram, CBOW) 预训练(pretrain)出 word embedding ,在本次RNN作业中只能用已有.txt中的数据进行预训练。
-
可以把它作为模型的一部分(词嵌入层),与模型的其他部分一起训练
