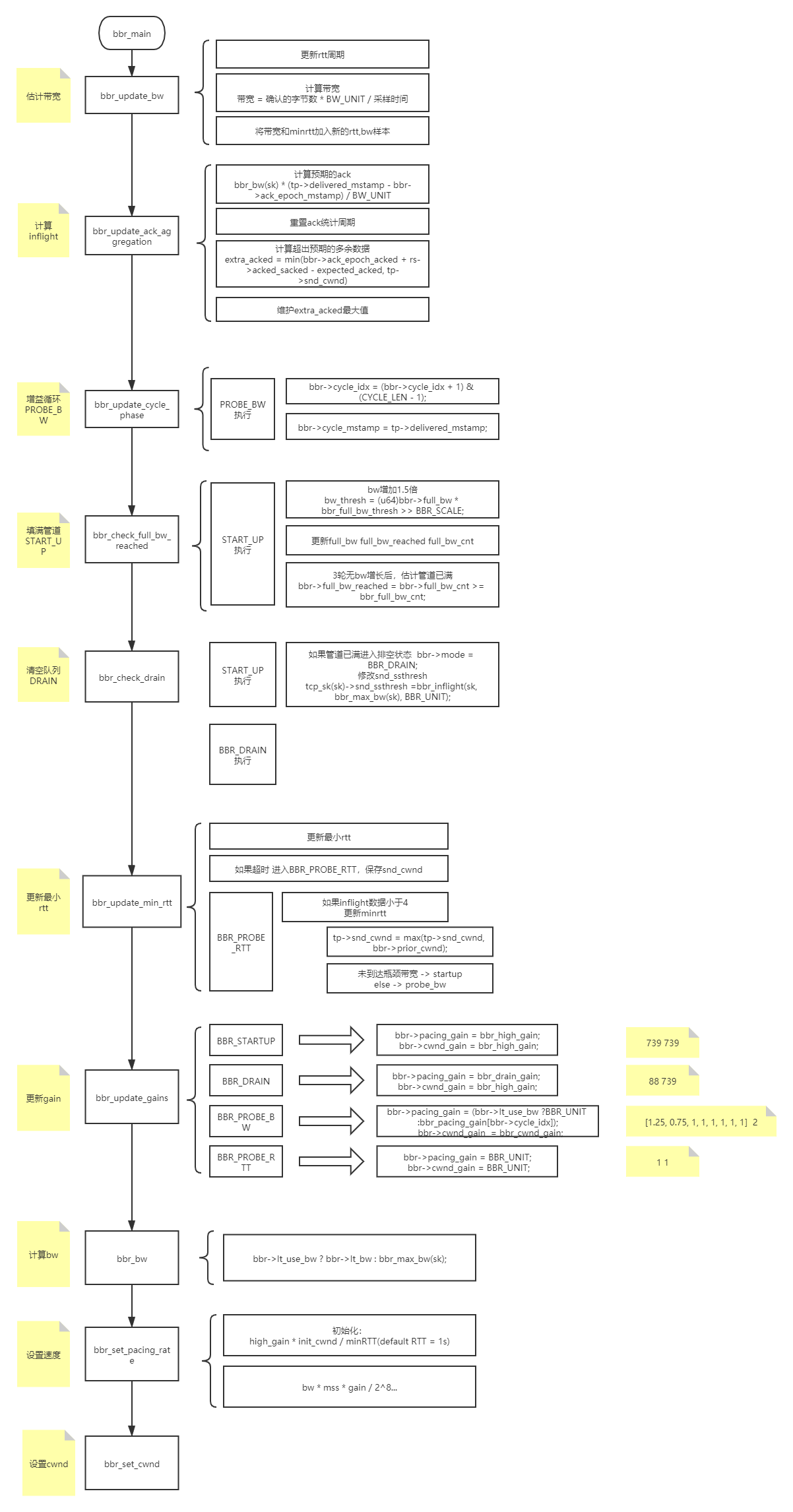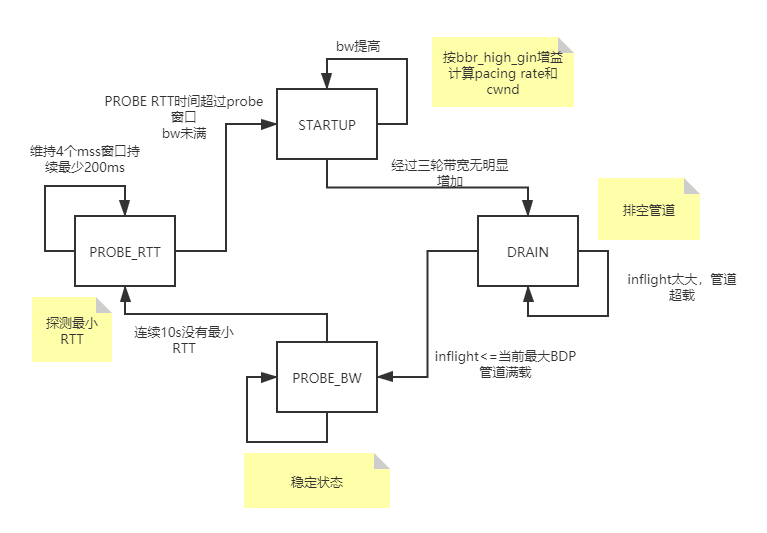
1 /* Bottleneck Bandwidth and RTT (BBR) congestion control 2 * 3 * BBR congestion control computes the sending rate based on the delivery 4 * rate (throughput) estimated from ACKs. In a nutshell: 5 * 6 * On each ACK, update our model of the network path: 7 * bottleneck_bandwidth = windowed_max(delivered / elapsed, 10 round trips) 8 * min_rtt = windowed_min(rtt, 10 seconds) 9 * pacing_rate = pacing_gain * bottleneck_bandwidth 10 * cwnd = max(cwnd_gain * bottleneck_bandwidth * min_rtt, 4) 11 * 12 * The core algorithm does not react directly to packet losses or delays, 13 * although BBR may adjust the size of next send per ACK when loss is 14 * observed, or adjust the sending rate if it estimates there is a 15 * traffic policer, in order to keep the drop rate reasonable. 16 * 17 * Here is a state transition diagram for BBR: 18 * 19 * | 20 * V 21 * +---> STARTUP ----+ 22 * | | | 23 * | V | 24 * | DRAIN ----+ 25 * | | | 26 * | V | 27 * +---> PROBE_BW ----+ 28 * | ^ | | 29 * | | | | 30 * | +----+ | 31 * | | 32 * +---- PROBE_RTT <--+ 33 * 34 * A BBR flow starts in STARTUP, and ramps up its sending rate quickly. 35 * When it estimates the pipe is full, it enters DRAIN to drain the queue. 36 * In steady state a BBR flow only uses PROBE_BW and PROBE_RTT. 37 * A long-lived BBR flow spends the vast majority of its time remaining 38 * (repeatedly) in PROBE_BW, fully probing and utilizing the pipe's bandwidth 39 * in a fair manner, with a small, bounded queue. *If* a flow has been 40 * continuously sending for the entire min_rtt window, and hasn't seen an RTT 41 * sample that matches or decreases its min_rtt estimate for 10 seconds, then 42 * it briefly enters PROBE_RTT to cut inflight to a minimum value to re-probe 43 * the path's two-way propagation delay (min_rtt). When exiting PROBE_RTT, if 44 * we estimated that we reached the full bw of the pipe then we enter PROBE_BW; 45 * otherwise we enter STARTUP to try to fill the pipe. 46 * 47 * BBR is described in detail in: 48 * "BBR: Congestion-Based Congestion Control", 49 * Neal Cardwell, Yuchung Cheng, C. Stephen Gunn, Soheil Hassas Yeganeh, 50 * Van Jacobson. ACM Queue, Vol. 14 No. 5, September-October 2016. 51 * 52 * There is a public e-mail list for discussing BBR development and testing: 53 * https://groups.google.com/forum/#!forum/bbr-dev 54 * 55 * NOTE: BBR might be used with the fq qdisc ("man tc-fq") with pacing enabled, 56 * otherwise TCP stack falls back to an internal pacing using one high 57 * resolution timer per TCP socket and may use more resources. 58 */ 59 #include <linux/module.h> 60 #include <net/tcp.h> 61 #include <linux/inet_diag.h> 62 #include <linux/inet.h> 63 #include <linux/random.h> 64 #include <linux/win_minmax.h> 65 66 /* Scale factor for rate in pkt/uSec unit to avoid truncation in bandwidth 67 * estimation. The rate unit ~= (1500 bytes / 1 usec / 2^24) ~= 715 bps. 68 * This handles bandwidths from 0.06pps (715bps) to 256Mpps (3Tbps) in a u32. 69 * Since the minimum window is >=4 packets, the lower bound isn't 70 * an issue. The upper bound isn't an issue with existing technologies. 71 */ 72 #define BW_SCALE 24 73 #define BW_UNIT (1 << BW_SCALE) 74 75 #define BBR_SCALE 8 /* scaling factor for fractions in BBR (e.g. gains) */ 76 #define BBR_UNIT (1 << BBR_SCALE) 77 78 /* BBR has the following modes for deciding how fast to send: */ 79 /* 80 BBR 四种模式: 81 STARTUP:快速开始抢占带宽 82 DRAIN:清空启动期间创建的任何队列 83 PROBE_BW: 周期测试最佳带宽 84 PROBE_RTT:清空发出的包计算minRTT 85 */ 86 enum bbr_mode { 87 BBR_STARTUP, /* ramp up sending rate rapidly to fill pipe */ 88 BBR_DRAIN, /* drain any queue created during startup */ 89 BBR_PROBE_BW, /* discover, share bw: pace around estimated bw */ 90 BBR_PROBE_RTT, /* cut inflight to min to probe min_rtt */ 91 }; 92 93 /* BBR congestion control block */ 94 struct bbr { 95 u32 min_rtt_us; /* min RTT in min_rtt_win_sec window */ 96 u32 min_rtt_stamp; /* timestamp of min_rtt_us */ 97 u32 probe_rtt_done_stamp; /* end time for BBR_PROBE_RTT mode */ 98 struct minmax bw; /* Max recent delivery rate in pkts/uS << 24 */ 99 u32 rtt_cnt; /* count of packet-timed rounds elapsed */ 100 u32 next_rtt_delivered; /* scb->tx.delivered at end of round */ 101 u64 cycle_mstamp; /* 周期阶段的开始 */ 102 u32 mode:3, /* 当前的bbr mode */ 103 prev_ca_state:3, /* CA state on previous ACK */ 104 packet_conservation:1, /* 使用包保护吗? */ 105 round_start:1, /* start of packet-timed tx->ack round? */ 106 idle_restart:1, /* restarting after idle? */ 107 probe_rtt_round_done:1, /* a BBR_PROBE_RTT round at 4 pkts? */ 108 unused:13, 109 lt_is_sampling:1, /* taking long-term ("LT") samples now? */ 110 lt_rtt_cnt:7, /* round trips in long-term interval */ 111 lt_use_bw:1; /* use lt_bw as our bw estimate? */ 112 u32 lt_bw; /* LT est delivery rate in pkts/uS << 24 */ 113 u32 lt_last_delivered; /* LT intvl start: tp->delivered */ 114 u32 lt_last_stamp; /* LT intvl start: tp->delivered_mstamp */ 115 u32 lt_last_lost; /* LT intvl start: tp->lost */ 116 u32 pacing_gain:10, /* current gain for setting pacing rate */ 117 cwnd_gain:10, /* cnwd当前增益 */ 118 full_bw_reached:1, /* reached full bw in Startup? */ 119 full_bw_cnt:2, /* number of rounds without large bw gains */ 120 cycle_idx:3, /* current index in pacing_gain cycle array */ 121 has_seen_rtt:1, /* have we seen an RTT sample yet? */ 122 unused_b:5; 123 u32 prior_cwnd; /* 之前的cwnd */ 124 u32 full_bw; /* 最近bw,估计管道是否满 */ 125 126 /* For tracking ACK aggregation: */ 127 u64 ack_epoch_mstamp; /* start of ACK sampling epoch */ 128 u16 extra_acked[2]; /* max excess data ACKed in epoch */ 129 u32 ack_epoch_acked:20, /* packets (S)ACKed in sampling epoch */ 130 extra_acked_win_rtts:5, /* age of extra_acked, in round trips */ 131 extra_acked_win_idx:1, /* current index in extra_acked array */ 132 unused_c:6; 133 }; 134 135 #define CYCLE_LEN 8 /* number of phases in a pacing gain cycle */ 136 137 /* Window length of bw filter (in rounds): */ 138 static const int bbr_bw_rtts = CYCLE_LEN + 2; 139 /* Window length of min_rtt filter (in sec): */ 140 //10s未更新最小rtt则进入PROBE_RTT 141 static const u32 bbr_min_rtt_win_sec = 10; 142 /* Minimum time (in ms) spent at bbr_cwnd_min_target in BBR_PROBE_RTT mode: */ 143 //BR_PROBE_RTT 在bbr_cwnd_min_target上花费的最小时间 144 static const u32 bbr_probe_rtt_mode_ms = 200; 145 // 146 /* Skip TSO below the following bandwidth (bits/sec): */ 147 static const int bbr_min_tso_rate = 1200000; 148 149 /* Pace at ~1% below estimated bw, on average, to reduce queue at bottleneck. 150 * In order to help drive the network toward lower queues and low latency while 151 * maintaining high utilization, the average pacing rate aims to be slightly 152 * lower than the estimated bandwidth. This is an important aspect of the 153 * design. 154 */ 155 static const int bbr_pacing_margin_percent = 1; 156 157 /* We use a high_gain value of 2/ln(2) because it's the smallest pacing gain 158 * that will allow a smoothly increasing pacing rate that will double each RTT 159 * and send the same number of packets per RTT that an un-paced, slow-starting 160 * Reno or CUBIC flow would: 161 */ 162 static const int bbr_high_gain = BBR_UNIT * 2885 / 1000 + 1; 163 /* The pacing gain of 1/high_gain in BBR_DRAIN is calculated to typically drain 164 * the queue created in BBR_STARTUP in a single round: 165 */ 166 static const int bbr_drain_gain = BBR_UNIT * 1000 / 2885; 167 /* The gain for deriving steady-state cwnd tolerates delayed/stretched ACKs: */ 168 static const int bbr_cwnd_gain = BBR_UNIT * 2; 169 /* The pacing_gain values for the PROBE_BW gain cycle, to discover/share bw: */ 170 static const int bbr_pacing_gain[] = { 171 BBR_UNIT * 5 / 4, /* probe for more available bw */ 172 BBR_UNIT * 3 / 4, /* drain queue and/or yield bw to other flows */ 173 BBR_UNIT, BBR_UNIT, BBR_UNIT, /* cruise at 1.0*bw to utilize pipe, */ 174 BBR_UNIT, BBR_UNIT, BBR_UNIT /* without creating excess queue... */ 175 }; 176 /* Randomize the starting gain cycling phase over N phases: */ 177 static const u32 bbr_cycle_rand = 7; 178 179 /* Try to keep at least this many packets in flight, if things go smoothly. For 180 * smooth functioning, a sliding window protocol ACKing every other packet 181 * needs at least 4 packets in flight: 182 */ 183 static const u32 bbr_cwnd_min_target = 4; 184 185 /* To estimate if BBR_STARTUP mode (i.e. high_gain) has filled pipe... */ 186 /* If bw has increased significantly (1.25x), there may be more bw available: */ 187 static const u32 bbr_full_bw_thresh = BBR_UNIT * 5 / 4; 188 /* But after 3 rounds w/o significant bw growth, estimate pipe is full: */ 189 static const u32 bbr_full_bw_cnt = 3; 190 191 /* "long-term" ("LT") bandwidth estimator parameters... */ 192 /* The minimum number of rounds in an LT bw sampling interval: */ 193 static const u32 bbr_lt_intvl_min_rtts = 4; 194 /* If lost/delivered ratio > 20%, interval is "lossy" and we may be policed: */ 195 static const u32 bbr_lt_loss_thresh = 50; 196 /* If 2 intervals have a bw ratio <= 1/8, their bw is "consistent": */ 197 static const u32 bbr_lt_bw_ratio = BBR_UNIT / 8; 198 /* If 2 intervals have a bw diff <= 4 Kbit/sec their bw is "consistent": */ 199 static const u32 bbr_lt_bw_diff = 4000 / 8; 200 /* If we estimate we're policed, use lt_bw for this many round trips: */ 201 static const u32 bbr_lt_bw_max_rtts = 48; 202 203 /* Gain factor for adding extra_acked to target cwnd: */ 204 static const int bbr_extra_acked_gain = BBR_UNIT; 205 /* Window length of extra_acked window. */ 206 static const u32 bbr_extra_acked_win_rtts = 5; 207 /* Max allowed val for ack_epoch_acked, after which sampling epoch is reset */ 208 static const u32 bbr_ack_epoch_acked_reset_thresh = 1U << 20; 209 /* Time period for clamping cwnd increment due to ack aggregation */ 210 static const u32 bbr_extra_acked_max_us = 100 * 1000; 211 212 static void bbr_check_probe_rtt_done(struct sock *sk); 213 214 /* Do we estimate that STARTUP filled the pipe? */ 215 static bool bbr_full_bw_reached(const struct sock *sk) 216 { 217 const struct bbr *bbr = inet_csk_ca(sk); 218 219 return bbr->full_bw_reached; 220 } 221 222 /* Return the windowed max recent bandwidth sample, in pkts/uS << BW_SCALE. */ 223 //TODO 返回窗口的最大最近带宽样本 224 static u32 bbr_max_bw(const struct sock *sk) 225 { 226 struct bbr *bbr = inet_csk_ca(sk); 227 228 return minmax_get(&bbr->bw); 229 } 230 231 /* Return the estimated bandwidth of the path, in pkts/uS << BW_SCALE. */ 232 //TODO 返回预估的带宽的路径 bbr->lt_use_bw == BBR_DRAIN ? bbr->lt_bw : bbr_max_bw(sk) 233 static u32 bbr_bw(const struct sock *sk) 234 { 235 struct bbr *bbr = inet_csk_ca(sk); 236 237 return bbr->lt_use_bw ? bbr->lt_bw : bbr_max_bw(sk); 238 } 239 240 /* Return maximum extra acked in past k-2k round trips, 241 * where k = bbr_extra_acked_win_rtts. 242 */ 243 static u16 bbr_extra_acked(const struct sock *sk) 244 { 245 struct bbr *bbr = inet_csk_ca(sk); 246 247 return max(bbr->extra_acked[0], bbr->extra_acked[1]); 248 } 249 250 /* Return rate in bytes per second, optionally with a gain. 251 * The order here is chosen carefully to avoid overflow of u64. This should 252 * work for input rates of up to 2.9Tbit/sec and gain of 2.89x. 253 */ 254 static u64 bbr_rate_bytes_per_sec(struct sock *sk, u64 rate, int gain) 255 { 256 unsigned int mss = tcp_sk(sk)->mss_cache; 257 258 rate *= mss; 259 rate *= gain; 260 rate >>= BBR_SCALE; 261 rate *= USEC_PER_SEC / 100 * (100 - bbr_pacing_margin_percent); 262 return rate >> BW_SCALE; 263 } 264 265 /* Convert a BBR bw and gain factor to a pacing rate in bytes per second. */ 266 static unsigned long bbr_bw_to_pacing_rate(struct sock *sk, u32 bw, int gain) 267 { 268 u64 rate = bw; 269 270 rate = bbr_rate_bytes_per_sec(sk, rate, gain); 271 rate = min_t(u64, rate, sk->sk_max_pacing_rate); 272 return rate; 273 } 274 275 /* Initialize pacing rate to: high_gain * init_cwnd / RTT. */ 276 static void bbr_init_pacing_rate_from_rtt(struct sock *sk) 277 { 278 struct tcp_sock *tp = tcp_sk(sk); 279 struct bbr *bbr = inet_csk_ca(sk); 280 u64 bw; 281 u32 rtt_us; 282 283 if (tp->srtt_us) { /* any RTT sample yet? */ 284 rtt_us = max(tp->srtt_us >> 3, 1U); 285 bbr->has_seen_rtt = 1; 286 } else { /* no RTT sample yet */ 287 rtt_us = USEC_PER_MSEC; /* use nominal default RTT */ 288 } 289 bw = (u64)tp->snd_cwnd * BW_UNIT; 290 do_div(bw, rtt_us); 291 sk->sk_pacing_rate = bbr_bw_to_pacing_rate(sk, bw, bbr_high_gain); 292 } 293 294 /* Pace using current bw estimate and a gain factor. */ 295 static void bbr_set_pacing_rate(struct sock *sk, u32 bw, int gain) 296 { 297 struct tcp_sock *tp = tcp_sk(sk); 298 struct bbr *bbr = inet_csk_ca(sk); 299 unsigned long rate = bbr_bw_to_pacing_rate(sk, bw, gain); 300 301 if (unlikely(!bbr->has_seen_rtt && tp->srtt_us)) 302 bbr_init_pacing_rate_from_rtt(sk); 303 if (bbr_full_bw_reached(sk) || rate > sk->sk_pacing_rate) 304 sk->sk_pacing_rate = rate; 305 } 306 307 /* override sysctl_tcp_min_tso_segs */ 308 //TODO 覆盖 sysctl_tcp_min_tso_segs sk->sk_pacing_rate < (bbr_min_tso_rate >> 3) ? 1 : 2 309 static u32 bbr_min_tso_segs(struct sock *sk) 310 { 311 return sk->sk_pacing_rate < (bbr_min_tso_rate >> 3) ? 1 : 2; 312 } 313 314 static u32 bbr_tso_segs_goal(struct sock *sk) 315 { 316 struct tcp_sock *tp = tcp_sk(sk); 317 u32 segs, bytes; 318 319 /* Sort of tcp_tso_autosize() but ignoring 320 * driver provided sk_gso_max_size. 321 */ 322 bytes = min_t(unsigned long, 323 sk->sk_pacing_rate >> READ_ONCE(sk->sk_pacing_shift), 324 GSO_MAX_SIZE - 1 - MAX_TCP_HEADER); 325 segs = max_t(u32, bytes / tp->mss_cache, bbr_min_tso_segs(sk)); 326 327 return min(segs, 0x7FU); 328 } 329 330 /* Save "last known good" cwnd so we can restore it after losses or PROBE_RTT */ 331 static void bbr_save_cwnd(struct sock *sk) 332 { 333 struct tcp_sock *tp = tcp_sk(sk); 334 struct bbr *bbr = inet_csk_ca(sk); 335 336 if (bbr->prev_ca_state < TCP_CA_Recovery && bbr->mode != BBR_PROBE_RTT) 337 bbr->prior_cwnd = tp->snd_cwnd; /* this cwnd is good enough */ 338 else /* loss recovery or BBR_PROBE_RTT have temporarily cut cwnd */ 339 bbr->prior_cwnd = max(bbr->prior_cwnd, tp->snd_cwnd); 340 } 341 342 static void bbr_cwnd_event(struct sock *sk, enum tcp_ca_event event) 343 { 344 struct tcp_sock *tp = tcp_sk(sk); 345 struct bbr *bbr = inet_csk_ca(sk); 346 347 if (event == CA_EVENT_TX_START && tp->app_limited) { 348 bbr->idle_restart = 1; 349 bbr->ack_epoch_mstamp = tp->tcp_mstamp; 350 bbr->ack_epoch_acked = 0; 351 /* Avoid pointless buffer overflows: pace at est. bw if we don't 352 * need more speed (we're restarting from idle and app-limited). 353 */ 354 if (bbr->mode == BBR_PROBE_BW) 355 bbr_set_pacing_rate(sk, bbr_bw(sk), BBR_UNIT); 356 else if (bbr->mode == BBR_PROBE_RTT) 357 bbr_check_probe_rtt_done(sk); 358 } 359 } 360 361 /* Calculate bdp based on min RTT and the estimated bottleneck band 362 * 363 * bdp = ceil(bw * min_rtt * gain) 364 * 365 * The key factor, gain, controls the amount of queue. While a small gain 366 * builds a smaller queue, it becomes more vulnerable to noise in RTT 367 * measurements (e.g., delayed ACKs or other ACK compression effects). This 368 * noise may cause BBR to under-estimate the rate. 369 */ 370 //return bdp = ((((u64)bw * bbr->min_rtt_us * gain) >> BBR_SCALE) + BW_UNIT - 1) / BW_UNIT 371 static u32 bbr_bdp(struct sock *sk, u32 bw, int gain) 372 { 373 struct bbr *bbr = inet_csk_ca(sk); 374 u32 bdp; 375 u64 w; 376 377 /* If we've never had a valid RTT sample, cap cwnd at the initial 378 * default. This should only happen when the connection is not using TCP 379 * timestamps and has retransmitted all of the SYN/SYNACK/data packets 380 * ACKed so far. In this case, an RTO can cut cwnd to 1, in which 381 * case we need to slow-start up toward something safe: TCP_INIT_CWND. 382 */ 383 if (unlikely(bbr->min_rtt_us == ~0U)) /* no valid RTT samples yet? */ 384 return TCP_INIT_CWND; /* be safe: cap at default initial cwnd*/ 385 386 w = (u64)bw * bbr->min_rtt_us; 387 388 /* Apply a gain to the given value, remove the BW_SCALE shift, and 389 * round the value up to avoid a negative feedback loop. 390 */ 391 bdp = (((w * gain) >> BBR_SCALE) + BW_UNIT - 1) / BW_UNIT; 392 393 return bdp; 394 } 395 396 /* To achieve full performance in high-speed paths, we budget enough cwnd to 397 * fit full-sized skbs in-flight on both end hosts to fully utilize the path: 398 * - one skb in sending host Qdisc, 399 * - one skb in sending host TSO/GSO engine 400 * - one skb being received by receiver host LRO/GRO/delayed-ACK engine 401 * Don't worry, at low rates (bbr_min_tso_rate) this won't bloat cwnd because 402 * in such cases tso_segs_goal is 1. The minimum cwnd is 4 packets, 403 * which allows 2 outstanding 2-packet sequences, to try to keep pipe 404 * full even with ACK-every-other-packet delayed ACKs. 405 */ 406 static u32 bbr_quantization_budget(struct sock *sk, u32 cwnd) 407 { 408 struct bbr *bbr = inet_csk_ca(sk); 409 410 /* Allow enough full-sized skbs in flight to utilize end systems. */ 411 cwnd += 3 * bbr_tso_segs_goal(sk); 412 413 /* Reduce delayed ACKs by rounding up cwnd to the next even number. */ 414 cwnd = (cwnd + 1) & ~1U; 415 416 /* Ensure gain cycling gets inflight above BDP even for small BDPs. */ 417 if (bbr->mode == BBR_PROBE_BW && bbr->cycle_idx == 0) 418 cwnd += 2; 419 420 return cwnd; 421 } 422 423 /* Find inflight based on min RTT and the estimated bottleneck bandwidth. */ 424 static u32 bbr_inflight(struct sock *sk, u32 bw, int gain) 425 { 426 u32 inflight; 427 428 inflight = bbr_bdp(sk, bw, gain); 429 inflight = bbr_quantization_budget(sk, inflight); 430 431 return inflight; 432 } 433 434 /* With pacing at lower layers, there's often less data "in the network" than 435 * "in flight". With TSQ and departure time pacing at lower layers (e.g. fq), 436 * we often have several skbs queued in the pacing layer with a pre-scheduled 437 * earliest departure time (EDT). BBR adapts its pacing rate based on the 438 * inflight level that it estimates has already been "baked in" by previous 439 * departure time decisions. We calculate a rough estimate of the number of our 440 * packets that might be in the network at the earliest departure time for the 441 * next skb scheduled: 442 * in_network_at_edt = inflight_at_edt - (EDT - now) * bw 443 * If we're increasing inflight, then we want to know if the transmit of the 444 * EDT skb will push inflight above the target, so inflight_at_edt includes 445 * bbr_tso_segs_goal() from the skb departing at EDT. If decreasing inflight, 446 * then estimate if inflight will sink too low just before the EDT transmit. 447 */ 448 static u32 bbr_packets_in_net_at_edt(struct sock *sk, u32 inflight_now) 449 { 450 struct tcp_sock *tp = tcp_sk(sk); 451 struct bbr *bbr = inet_csk_ca(sk); 452 u64 now_ns, edt_ns, interval_us; 453 u32 interval_delivered, inflight_at_edt; 454 455 now_ns = tp->tcp_clock_cache; 456 edt_ns = max(tp->tcp_wstamp_ns, now_ns); 457 interval_us = div_u64(edt_ns - now_ns, NSEC_PER_USEC); 458 interval_delivered = (u64)bbr_bw(sk) * interval_us >> BW_SCALE; 459 inflight_at_edt = inflight_now; 460 if (bbr->pacing_gain > BBR_UNIT) /* increasing inflight */ 461 inflight_at_edt += bbr_tso_segs_goal(sk); /* include EDT skb */ 462 if (interval_delivered >= inflight_at_edt) 463 return 0; 464 return inflight_at_edt - interval_delivered; 465 } 466 467 /* Find the cwnd increment based on estimate of ack aggregation */ 468 static u32 bbr_ack_aggregation_cwnd(struct sock *sk) 469 { 470 u32 max_aggr_cwnd, aggr_cwnd = 0; 471 472 if (bbr_extra_acked_gain && bbr_full_bw_reached(sk)) { 473 max_aggr_cwnd = ((u64)bbr_bw(sk) * bbr_extra_acked_max_us) 474 / BW_UNIT; 475 aggr_cwnd = (bbr_extra_acked_gain * bbr_extra_acked(sk)) 476 >> BBR_SCALE; 477 aggr_cwnd = min(aggr_cwnd, max_aggr_cwnd); 478 } 479 480 return aggr_cwnd; 481 } 482 483 /* An optimization in BBR to reduce losses: On the first round of recovery, we 484 * follow the packet conservation principle: send P packets per P packets acked. 485 * After that, we slow-start and send at most 2*P packets per P packets acked. 486 * After recovery finishes, or upon undo, we restore the cwnd we had when 487 * recovery started (capped by the target cwnd based on estimated BDP). 488 * 489 * TODO(ycheng/ncardwell): implement a rate-based approach. 490 */ 491 static bool bbr_set_cwnd_to_recover_or_restore( 492 struct sock *sk, const struct rate_sample *rs, u32 acked, u32 *new_cwnd) 493 { 494 struct tcp_sock *tp = tcp_sk(sk); 495 struct bbr *bbr = inet_csk_ca(sk); 496 u8 prev_state = bbr->prev_ca_state, state = inet_csk(sk)->icsk_ca_state; 497 u32 cwnd = tp->snd_cwnd; 498 499 /* An ACK for P pkts should release at most 2*P packets. We do this 500 * in two steps. First, here we deduct the number of lost packets. 501 * Then, in bbr_set_cwnd() we slow start up toward the target cwnd. 502 */ 503 if (rs->losses > 0) 504 cwnd = max_t(s32, cwnd - rs->losses, 1); 505 506 if (state == TCP_CA_Recovery && prev_state != TCP_CA_Recovery) { 507 /* Starting 1st round of Recovery, so do packet conservation. */ 508 bbr->packet_conservation = 1; 509 bbr->next_rtt_delivered = tp->delivered; /* start round now */ 510 /* Cut unused cwnd from app behavior, TSQ, or TSO deferral: */ 511 cwnd = tcp_packets_in_flight(tp) + acked; 512 } else if (prev_state >= TCP_CA_Recovery && state < TCP_CA_Recovery) { 513 /* Exiting loss recovery; restore cwnd saved before recovery. */ 514 cwnd = max(cwnd, bbr->prior_cwnd); 515 bbr->packet_conservation = 0; 516 } 517 bbr->prev_ca_state = state; 518 519 if (bbr->packet_conservation) { 520 *new_cwnd = max(cwnd, tcp_packets_in_flight(tp) + acked); 521 return true; /* yes, using packet conservation */ 522 } 523 *new_cwnd = cwnd; 524 return false; 525 } 526 527 /* Slow-start up toward target cwnd (if bw estimate is growing, or packet loss 528 * has drawn us down below target), or snap down to target if we're above it. 529 */ 530 static void bbr_set_cwnd(struct sock *sk, const struct rate_sample *rs, 531 u32 acked, u32 bw, int gain) 532 { 533 struct tcp_sock *tp = tcp_sk(sk); 534 struct bbr *bbr = inet_csk_ca(sk); 535 u32 cwnd = tp->snd_cwnd, target_cwnd = 0; 536 537 if (!acked) 538 goto done; /* no packet fully ACKed; just apply caps */ 539 540 if (bbr_set_cwnd_to_recover_or_restore(sk, rs, acked, &cwnd)) 541 goto done; 542 543 target_cwnd = bbr_bdp(sk, bw, gain); 544 545 /* Increment the cwnd to account for excess ACKed data that seems 546 * due to aggregation (of data and/or ACKs) visible in the ACK stream. 547 */ 548 target_cwnd += bbr_ack_aggregation_cwnd(sk); 549 target_cwnd = bbr_quantization_budget(sk, target_cwnd); 550 551 /* If we're below target cwnd, slow start cwnd toward target cwnd. */ 552 if (bbr_full_bw_reached(sk)) /* only cut cwnd if we filled the pipe */ 553 cwnd = min(cwnd + acked, target_cwnd); 554 else if (cwnd < target_cwnd || tp->delivered < TCP_INIT_CWND) 555 cwnd = cwnd + acked; 556 cwnd = max(cwnd, bbr_cwnd_min_target); 557 558 done: 559 tp->snd_cwnd = min(cwnd, tp->snd_cwnd_clamp); /* apply global cap */ 560 if (bbr->mode == BBR_PROBE_RTT) /* drain queue, refresh min_rtt */ 561 tp->snd_cwnd = min(tp->snd_cwnd, bbr_cwnd_min_target); 562 } 563 564 /* End cycle phase if it's time and/or we hit the phase's in-flight target. */ 565 static bool bbr_is_next_cycle_phase(struct sock *sk, 566 const struct rate_sample *rs) 567 { 568 struct tcp_sock *tp = tcp_sk(sk); 569 struct bbr *bbr = inet_csk_ca(sk); 570 bool is_full_length = 571 tcp_stamp_us_delta(tp->delivered_mstamp, bbr->cycle_mstamp) > 572 bbr->min_rtt_us; 573 u32 inflight, bw; 574 575 /* The pacing_gain of 1.0 paces at the estimated bw to try to fully 576 * use the pipe without increasing the queue. 577 */ 578 if (bbr->pacing_gain == BBR_UNIT) 579 return is_full_length; /* just use wall clock time */ 580 581 inflight = bbr_packets_in_net_at_edt(sk, rs->prior_in_flight); 582 bw = bbr_max_bw(sk); 583 584 /* A pacing_gain > 1.0 probes for bw by trying to raise inflight to at 585 * least pacing_gain*BDP; this may take more than min_rtt if min_rtt is 586 * small (e.g. on a LAN). We do not persist if packets are lost, since 587 * a path with small buffers may not hold that much. 588 */ 589 if (bbr->pacing_gain > BBR_UNIT) 590 return is_full_length && 591 (rs->losses || /* perhaps pacing_gain*BDP won't fit */ 592 inflight >= bbr_inflight(sk, bw, bbr->pacing_gain)); 593 594 /* A pacing_gain < 1.0 tries to drain extra queue we added if bw 595 * probing didn't find more bw. If inflight falls to match BDP then we 596 * estimate queue is drained; persisting would underutilize the pipe. 597 */ 598 return is_full_length || 599 inflight <= bbr_inflight(sk, bw, BBR_UNIT); 600 } 601 602 static void bbr_advance_cycle_phase(struct sock *sk) 603 { 604 struct tcp_sock *tp = tcp_sk(sk); 605 struct bbr *bbr = inet_csk_ca(sk); 606 607 bbr->cycle_idx = (bbr->cycle_idx + 1) & (CYCLE_LEN - 1); 608 bbr->cycle_mstamp = tp->delivered_mstamp; 609 } 610 611 /* Gain cycling: cycle pacing gain to converge to fair share of available bw. */ 612 //TODO 增益循环 循环速度增益收敛到可用bw的公平份额 613 static void bbr_update_cycle_phase(struct sock *sk, 614 const struct rate_sample *rs) 615 { 616 struct bbr *bbr = inet_csk_ca(sk); 617 618 if (bbr->mode == BBR_PROBE_BW && bbr_is_next_cycle_phase(sk, rs)) 619 bbr_advance_cycle_phase(sk); 620 } 621 622 static void bbr_reset_startup_mode(struct sock *sk) 623 { 624 struct bbr *bbr = inet_csk_ca(sk); 625 626 bbr->mode = BBR_STARTUP; 627 } 628 629 //TODO 进入PROBE_BW状态 630 static void bbr_reset_probe_bw_mode(struct sock *sk) 631 { 632 struct bbr *bbr = inet_csk_ca(sk); 633 634 bbr->mode = BBR_PROBE_BW; 635 bbr->cycle_idx = CYCLE_LEN - 1 - prandom_u32_max(bbr_cycle_rand); 636 bbr_advance_cycle_phase(sk); /* flip to next phase of gain cycle */ 637 } 638 639 static void bbr_reset_mode(struct sock *sk) 640 { 641 if (!bbr_full_bw_reached(sk)) 642 bbr_reset_startup_mode(sk); 643 else 644 bbr_reset_probe_bw_mode(sk); 645 } 646 647 /* Start a new long-term sampling interval. */ 648 static void bbr_reset_lt_bw_sampling_interval(struct sock *sk) 649 { 650 struct tcp_sock *tp = tcp_sk(sk); 651 struct bbr *bbr = inet_csk_ca(sk); 652 653 bbr->lt_last_stamp = div_u64(tp->delivered_mstamp, USEC_PER_MSEC); 654 bbr->lt_last_delivered = tp->delivered; 655 bbr->lt_last_lost = tp->lost; 656 bbr->lt_rtt_cnt = 0; 657 } 658 659 /* Completely reset long-term bandwidth sampling. */ 660 static void bbr_reset_lt_bw_sampling(struct sock *sk) 661 { 662 struct bbr *bbr = inet_csk_ca(sk); 663 664 bbr->lt_bw = 0; 665 bbr->lt_use_bw = 0; 666 bbr->lt_is_sampling = false; 667 bbr_reset_lt_bw_sampling_interval(sk); 668 } 669 670 /* Long-term bw sampling interval is done. Estimate whether we're policed. */ 671 static void bbr_lt_bw_interval_done(struct sock *sk, u32 bw) 672 { 673 struct bbr *bbr = inet_csk_ca(sk); 674 u32 diff; 675 676 if (bbr->lt_bw) { /* do we have bw from a previous interval? */ 677 /* Is new bw close to the lt_bw from the previous interval? */ 678 diff = abs(bw - bbr->lt_bw); 679 if ((diff * BBR_UNIT <= bbr_lt_bw_ratio * bbr->lt_bw) || 680 (bbr_rate_bytes_per_sec(sk, diff, BBR_UNIT) <= 681 bbr_lt_bw_diff)) { 682 /* All criteria are met; estimate we're policed. */ 683 bbr->lt_bw = (bw + bbr->lt_bw) >> 1; /* avg 2 intvls */ 684 bbr->lt_use_bw = 1; 685 bbr->pacing_gain = BBR_UNIT; /* try to avoid drops */ 686 bbr->lt_rtt_cnt = 0; 687 return; 688 } 689 } 690 bbr->lt_bw = bw; 691 bbr_reset_lt_bw_sampling_interval(sk); 692 } 693 694 /* Token-bucket traffic policers are common (see "An Internet-Wide Analysis of 695 * Traffic Policing", SIGCOMM 2016). BBR detects token-bucket policers and 696 * explicitly models their policed rate, to reduce unnecessary losses. We 697 * estimate that we're policed if we see 2 consecutive sampling intervals with 698 * consistent throughput and high packet loss. If we think we're being policed, 699 * set lt_bw to the "long-term" average delivery rate from those 2 intervals. 700 */ 701 static void bbr_lt_bw_sampling(struct sock *sk, const struct rate_sample *rs) 702 { 703 struct tcp_sock *tp = tcp_sk(sk); 704 struct bbr *bbr = inet_csk_ca(sk); 705 u32 lost, delivered; 706 u64 bw; 707 u32 t; 708 709 if (bbr->lt_use_bw) { /* already using long-term rate, lt_bw? */ 710 if (bbr->mode == BBR_PROBE_BW && bbr->round_start && 711 ++bbr->lt_rtt_cnt >= bbr_lt_bw_max_rtts) { 712 bbr_reset_lt_bw_sampling(sk); /* stop using lt_bw */ 713 bbr_reset_probe_bw_mode(sk); /* restart gain cycling */ 714 } 715 return; 716 } 717 718 /* Wait for the first loss before sampling, to let the policer exhaust 719 * its tokens and estimate the steady-state rate allowed by the policer. 720 * Starting samples earlier includes bursts that over-estimate the bw. 721 */ 722 if (!bbr->lt_is_sampling) { 723 if (!rs->losses) 724 return; 725 bbr_reset_lt_bw_sampling_interval(sk); 726 bbr->lt_is_sampling = true; 727 } 728 729 /* To avoid underestimates, reset sampling if we run out of data. */ 730 if (rs->is_app_limited) { 731 bbr_reset_lt_bw_sampling(sk); 732 return; 733 } 734 735 if (bbr->round_start) 736 bbr->lt_rtt_cnt++; /* count round trips in this interval */ 737 if (bbr->lt_rtt_cnt < bbr_lt_intvl_min_rtts) 738 return; /* sampling interval needs to be longer */ 739 if (bbr->lt_rtt_cnt > 4 * bbr_lt_intvl_min_rtts) { 740 bbr_reset_lt_bw_sampling(sk); /* interval is too long */ 741 return; 742 } 743 744 /* End sampling interval when a packet is lost, so we estimate the 745 * policer tokens were exhausted. Stopping the sampling before the 746 * tokens are exhausted under-estimates the policed rate. 747 */ 748 if (!rs->losses) 749 return; 750 751 /* Calculate packets lost and delivered in sampling interval. */ 752 lost = tp->lost - bbr->lt_last_lost; 753 delivered = tp->delivered - bbr->lt_last_delivered; 754 /* Is loss rate (lost/delivered) >= lt_loss_thresh? If not, wait. */ 755 if (!delivered || (lost << BBR_SCALE) < bbr_lt_loss_thresh * delivered) 756 return; 757 758 /* Find average delivery rate in this sampling interval. */ 759 t = div_u64(tp->delivered_mstamp, USEC_PER_MSEC) - bbr->lt_last_stamp; 760 if ((s32)t < 1) 761 return; /* interval is less than one ms, so wait */ 762 /* Check if can multiply without overflow */ 763 if (t >= ~0U / USEC_PER_MSEC) { 764 bbr_reset_lt_bw_sampling(sk); /* interval too long; reset */ 765 return; 766 } 767 t *= USEC_PER_MSEC; 768 bw = (u64)delivered * BW_UNIT; 769 do_div(bw, t); 770 bbr_lt_bw_interval_done(sk, bw); 771 } 772 773 /* Estimate the bandwidth based on how fast packets are delivered */ 774 //TODO 根据发送数据包的速度估计带宽 775 static void bbr_update_bw(struct sock *sk, const struct rate_sample *rs) 776 { 777 struct tcp_sock *tp = tcp_sk(sk); 778 struct bbr *bbr = inet_csk_ca(sk); 779 u64 bw; 780 781 bbr->round_start = 0; 782 783 //无效数据 784 if (rs->delivered < 0 || rs->interval_us <= 0) 785 return; /* Not a valid observation */ 786 787 /* See if we've reached the next RTT */ 788 // 判断是否到达下一个rtt 789 if (!before(rs->prior_delivered, bbr->next_rtt_delivered)) { 790 //更新rtt 791 bbr->next_rtt_delivered = tp->delivered; 792 bbr->rtt_cnt++; 793 bbr->round_start = 1; 794 bbr->packet_conservation = 0; 795 } 796 797 //令牌桶监管 798 bbr_lt_bw_sampling(sk, rs); 799 800 /* Divide delivered by the interval to find a (lower bound) bottleneck 801 * bandwidth sample. Delivered is in packets and interval_us in uS and 802 * ratio will be <<1 for most connections. So delivered is first scaled. 803 */ 804 //rs->delivered: 采样期间已确认的字节数 805 //rs->interval_us: 采样时间 806 //带宽 = 确认的字节数 * BW_UNIT / 采样时间 807 bw = div64_long((u64)rs->delivered * BW_UNIT, rs->interval_us); 808 809 /* 810 * static inline s64 div64_s64(s64 dividend, s64 divisor) 811 * { 812 * return dividend / divisor; 813 * } 814 */ 815 816 /* If this sample is application-limited, it is likely to have a very 817 * low delivered count that represents application behavior rather than 818 * the available network rate. Such a sample could drag down estimated 819 * bw, causing needless slow-down. Thus, to continue to send at the 820 * last measured network rate, we filter out app-limited samples unless 821 * they describe the path bw at least as well as our bw model. 822 * 823 * So the goal during app-limited phase is to proceed with the best 824 * network rate no matter how long. We automatically leave this 825 * phase when app writes faster than the network can deliver :) 826 */ 827 // 828 //加入新的样本 829 if (!rs->is_app_limited || bw >= bbr_max_bw(sk)) { 830 /* Incorporate new sample into our max bw filter. */ 831 minmax_running_max(&bbr->bw, bbr_bw_rtts, bbr->rtt_cnt, bw); 832 } 833 } 834 835 /* Estimates the windowed max degree of ack aggregation. 836 * This is used to provision extra in-flight data to keep sending during 837 * inter-ACK silences. 838 * 839 * Degree of ack aggregation is estimated as extra data acked beyond expected. 840 * 841 * max_extra_acked = "maximum recent excess data ACKed beyond max_bw * interval" 842 * cwnd += max_extra_acked 843 * 844 * Max extra_acked is clamped by cwnd and bw * bbr_extra_acked_max_us (100 ms). 845 * Max filter is an approximate sliding window of 5-10 (packet timed) round 846 * trips. 847 */ 848 //TODO ack静默期间,提供额外的inflight数据 849 static void bbr_update_ack_aggregation(struct sock *sk, 850 const struct rate_sample *rs) 851 { 852 u32 epoch_us, expected_acked, extra_acked; 853 struct bbr *bbr = inet_csk_ca(sk); 854 struct tcp_sock *tp = tcp_sk(sk); 855 856 if (!bbr_extra_acked_gain || rs->acked_sacked <= 0 || 857 rs->delivered < 0 || rs->interval_us <= 0) 858 return; 859 860 // bbr->round_start不可能为1 ? 861 if (bbr->round_start) { 862 bbr->extra_acked_win_rtts = min(0x1F, 863 bbr->extra_acked_win_rtts + 1); 864 if (bbr->extra_acked_win_rtts >= bbr_extra_acked_win_rtts) { 865 bbr->extra_acked_win_rtts = 0; 866 bbr->extra_acked_win_idx = bbr->extra_acked_win_idx ? 867 0 : 1; 868 bbr->extra_acked[bbr->extra_acked_win_idx] = 0; 869 } 870 } 871 872 /* Compute how many packets we expected to be delivered over epoch. */ 873 //计算期望发出的包 874 //预期的ack = bbr_bw(sk) * (tp->delivered_mstamp - bbr->ack_epoch_mstamp) / BW_UNIT 875 //static inline u32 tcp_stamp_us_delta(u64 t1, u64 t0) 876 //{ 877 // return max_t(s64, t1 - t0, 0); 878 //} 879 // bbr_bw(sk) : bbr->lt_use_bw == BBR_DRAIN ? bbr->lt_bw : bbr_max_bw(sk) 880 epoch_us = tcp_stamp_us_delta(tp->delivered_mstamp, 881 bbr->ack_epoch_mstamp); //epoch_us : 交付时间 - 采样开始的时间 882 expected_acked = ((u64)bbr_bw(sk) * epoch_us) / BW_UNIT; //预计的ack 883 884 /* Reset the aggregation epoch if ACK rate is below expected rate or 885 * significantly large no. of ack received since epoch (potentially 886 * quite old epoch). 887 */ 888 //重置周期 889 if (bbr->ack_epoch_acked <= expected_acked || 890 (bbr->ack_epoch_acked + rs->acked_sacked >= 891 bbr_ack_epoch_acked_reset_thresh)) { 892 bbr->ack_epoch_acked = 0; 893 bbr->ack_epoch_mstamp = tp->delivered_mstamp; 894 expected_acked = 0; 895 } 896 897 /* Compute excess data delivered, beyond what was expected. */ 898 //计算超出预期的多余数据 899 // extra_acked = min(bbr->ack_epoch_acked + rs->acked_sacked - expected_acked, tp->snd_cwnd) 900 bbr->ack_epoch_acked = min_t(u32, 0xFFFFF, //防止溢出(ack_epoch_acked:20) 901 bbr->ack_epoch_acked + rs->acked_sacked); //ack + sack 902 extra_acked = bbr->ack_epoch_acked - expected_acked; 903 extra_acked = min(extra_acked, tp->snd_cwnd); 904 if (extra_acked > bbr->extra_acked[bbr->extra_acked_win_idx]) //维护extra_acked最大值 905 bbr->extra_acked[bbr->extra_acked_win_idx] = extra_acked; 906 } 907 908 /* Estimate when the pipe is full, using the change in delivery rate: BBR 909 * estimates that STARTUP filled the pipe if the estimated bw hasn't changed by 910 * at least bbr_full_bw_thresh (25%) after bbr_full_bw_cnt (3) non-app-limited 911 * rounds. Why 3 rounds: 1: rwin autotuning grows the rwin, 2: we fill the 912 * higher rwin, 3: we get higher delivery rate samples. Or transient 913 * cross-traffic or radio noise can go away. CUBIC Hystart shares a similar 914 * design goal, but uses delay and inter-ACK spacing instead of bandwidth. 915 */ 916 //TODO 估计管道满时的情况 917 static void bbr_check_full_bw_reached(struct sock *sk, 918 const struct rate_sample *rs) 919 { 920 struct bbr *bbr = inet_csk_ca(sk); 921 u32 bw_thresh; 922 // bbr_full_bw_reached : bbr->full_bw_reached 923 if (bbr_full_bw_reached(sk) || !bbr->round_start || rs->is_app_limited) 924 return; 925 926 bw_thresh = (u64)bbr->full_bw * bbr_full_bw_thresh >> BBR_SCALE; 927 //更新full_bw full_bw_reached full_bw_cnt 928 if (bbr_max_bw(sk) >= bw_thresh) { 929 bbr->full_bw = bbr_max_bw(sk); 930 bbr->full_bw_cnt = 0; 931 return; 932 } 933 ++bbr->full_bw_cnt; 934 bbr->full_bw_reached = bbr->full_bw_cnt >= bbr_full_bw_cnt; 935 } 936 937 /* If pipe is probably full, drain the queue and then enter steady-state. */ 938 //TODO 如果管道可能已满,则排空队列,然后进入稳定状态 939 static void bbr_check_drain(struct sock *sk, const struct rate_sample *rs) 940 { 941 struct bbr *bbr = inet_csk_ca(sk); 942 943 if (bbr->mode == BBR_STARTUP && bbr_full_bw_reached(sk)) { 944 bbr->mode = BBR_DRAIN; /* drain queue we created */ 945 tcp_sk(sk)->snd_ssthresh = 946 bbr_inflight(sk, bbr_max_bw(sk), BBR_UNIT); 947 } /* fall through to check if in-flight is already small: */ 948 if (bbr->mode == BBR_DRAIN && 949 bbr_packets_in_net_at_edt(sk, tcp_packets_in_flight(tcp_sk(sk))) <= 950 bbr_inflight(sk, bbr_max_bw(sk), BBR_UNIT)) 951 bbr_reset_probe_bw_mode(sk); /* we estimate queue is drained */ 952 } 953 954 static void bbr_check_probe_rtt_done(struct sock *sk) 955 { 956 struct tcp_sock *tp = tcp_sk(sk); 957 struct bbr *bbr = inet_csk_ca(sk); 958 959 if (!(bbr->probe_rtt_done_stamp && 960 after(tcp_jiffies32, bbr->probe_rtt_done_stamp))) 961 return; 962 963 bbr->min_rtt_stamp = tcp_jiffies32; /* wait a while until PROBE_RTT */ 964 tp->snd_cwnd = max(tp->snd_cwnd, bbr->prior_cwnd); 965 bbr_reset_mode(sk); 966 } 967 968 /* The goal of PROBE_RTT mode is to have BBR flows cooperatively and 969 * periodically drain the bottleneck queue, to converge to measure the true 970 * min_rtt (unloaded propagation delay). This allows the flows to keep queues 971 * small (reducing queuing delay and packet loss) and achieve fairness among 972 * BBR flows. 973 * 974 * The min_rtt filter window is 10 seconds. When the min_rtt estimate expires, 975 * we enter PROBE_RTT mode and cap the cwnd at bbr_cwnd_min_target=4 packets. 976 * After at least bbr_probe_rtt_mode_ms=200ms and at least one packet-timed 977 * round trip elapsed with that flight size <= 4, we leave PROBE_RTT mode and 978 * re-enter the previous mode. BBR uses 200ms to approximately bound the 979 * performance penalty of PROBE_RTT's cwnd capping to roughly 2% (200ms/10s). 980 * 981 * Note that flows need only pay 2% if they are busy sending over the last 10 982 * seconds. Interactive applications (e.g., Web, RPCs, video chunks) often have 983 * natural silences or low-rate periods within 10 seconds where the rate is low 984 * enough for long enough to drain its queue in the bottleneck. We pick up 985 * these min RTT measurements opportunistically with our min_rtt filter. :-) 986 */ 987 //TODO 更新最小RTT 988 static void bbr_update_min_rtt(struct sock *sk, const struct rate_sample *rs) 989 { 990 struct tcp_sock *tp = tcp_sk(sk); 991 struct bbr *bbr = inet_csk_ca(sk); 992 bool filter_expired; 993 994 /* Track min RTT seen in the min_rtt_win_sec filter window: */ 995 filter_expired = after(tcp_jiffies32, 996 bbr->min_rtt_stamp + bbr_min_rtt_win_sec * HZ); 997 if (rs->rtt_us >= 0 && 998 (rs->rtt_us <= bbr->min_rtt_us || 999 (filter_expired && !rs->is_ack_delayed))) { 1000 bbr->min_rtt_us = rs->rtt_us; 1001 bbr->min_rtt_stamp = tcp_jiffies32; 1002 } 1003 1004 if (bbr_probe_rtt_mode_ms > 0 && filter_expired && 1005 !bbr->idle_restart && bbr->mode != BBR_PROBE_RTT) { 1006 bbr->mode = BBR_PROBE_RTT; /* dip, drain queue */ 1007 bbr_save_cwnd(sk); /* note cwnd so we can restore it */ 1008 bbr->probe_rtt_done_stamp = 0; 1009 } 1010 1011 if (bbr->mode == BBR_PROBE_RTT) { 1012 /* Ignore low rate samples during this mode. */ 1013 tp->app_limited = 1014 (tp->delivered + tcp_packets_in_flight(tp)) ? : 1; 1015 /* Maintain min packets in flight for max(200 ms, 1 round). */ 1016 if (!bbr->probe_rtt_done_stamp && 1017 tcp_packets_in_flight(tp) <= bbr_cwnd_min_target) { 1018 bbr->probe_rtt_done_stamp = tcp_jiffies32 + 1019 msecs_to_jiffies(bbr_probe_rtt_mode_ms); 1020 bbr->probe_rtt_round_done = 0; 1021 bbr->next_rtt_delivered = tp->delivered; 1022 } else if (bbr->probe_rtt_done_stamp) { 1023 if (bbr->round_start) 1024 bbr->probe_rtt_round_done = 1; 1025 if (bbr->probe_rtt_round_done) 1026 bbr_check_probe_rtt_done(sk); 1027 } 1028 } 1029 /* Restart after idle ends only once we process a new S/ACK for data */ 1030 if (rs->delivered > 0) 1031 bbr->idle_restart = 0; 1032 } 1033 1034 //TODO 根据所处阶段更新gains 1035 static void bbr_update_gains(struct sock *sk) 1036 { 1037 struct bbr *bbr = inet_csk_ca(sk); 1038 1039 switch (bbr->mode) { 1040 case BBR_STARTUP: 1041 // 739 739 1042 bbr->pacing_gain = bbr_high_gain; 1043 bbr->cwnd_gain = bbr_high_gain; 1044 break; 1045 case BBR_DRAIN: 1046 //88 739 1047 bbr->pacing_gain = bbr_drain_gain; /* slow, to drain */ 1048 bbr->cwnd_gain = bbr_high_gain; /* keep cwnd */ 1049 break; 1050 case BBR_PROBE_BW: 1051 // 1052 bbr->pacing_gain = (bbr->lt_use_bw ? 1053 BBR_UNIT : 1054 bbr_pacing_gain[bbr->cycle_idx]); 1055 bbr->cwnd_gain = bbr_cwnd_gain; 1056 break; 1057 case BBR_PROBE_RTT: 1058 // UNIT UNIT 1059 bbr->pacing_gain = BBR_UNIT; 1060 bbr->cwnd_gain = BBR_UNIT; 1061 break; 1062 default: 1063 WARN_ONCE(1, "BBR bad mode: %u ", bbr->mode); 1064 break; 1065 } 1066 } 1067 1068 static void bbr_update_model(struct sock *sk, const struct rate_sample *rs) 1069 { 1070 bbr_update_bw(sk, rs); //估计带宽 1071 bbr_update_ack_aggregation(sk, rs); //ack静默期间计算额外的inflight 1072 bbr_update_cycle_phase(sk, rs); //增益循环 1073 bbr_check_full_bw_reached(sk, rs); //估计管道满的情况 1074 bbr_check_drain(sk, rs); //如果管道可能已满,则排空队列,然后进入稳定状态 1075 bbr_update_min_rtt(sk, rs); //更新最小rtt 1076 bbr_update_gains(sk); //更新gains 1077 } 1078 1079 //TODO main 1080 static void bbr_main(struct sock *sk, const struct rate_sample *rs) 1081 { 1082 struct bbr *bbr = inet_csk_ca(sk); 1083 u32 bw; 1084 1085 bbr_update_model(sk, rs); 1086 1087 bw = bbr_bw(sk); 1088 bbr_set_pacing_rate(sk, bw, bbr->pacing_gain); //设置速度 1089 bbr_set_cwnd(sk, rs, rs->acked_sacked, bw, bbr->cwnd_gain); //设置cwnd 1090 } 1091 1092 //TODO: 初始化 1093 static void bbr_init(struct sock *sk) 1094 { 1095 struct tcp_sock *tp = tcp_sk(sk); 1096 struct bbr *bbr = inet_csk_ca(sk); 1097 1098 bbr->prior_cwnd = 0; 1099 tp->snd_ssthresh = TCP_INFINITE_SSTHRESH; 1100 bbr->rtt_cnt = 0; 1101 bbr->next_rtt_delivered = 0; 1102 bbr->prev_ca_state = TCP_CA_Open; 1103 bbr->packet_conservation = 0; 1104 1105 bbr->probe_rtt_done_stamp = 0; 1106 bbr->probe_rtt_round_done = 0; 1107 bbr->min_rtt_us = tcp_min_rtt(tp); 1108 bbr->min_rtt_stamp = tcp_jiffies32; 1109 1110 minmax_reset(&bbr->bw, bbr->rtt_cnt, 0); /* init max bw to 0 */ 1111 1112 bbr->has_seen_rtt = 0; 1113 bbr_init_pacing_rate_from_rtt(sk); 1114 1115 bbr->round_start = 0; 1116 bbr->idle_restart = 0; 1117 bbr->full_bw_reached = 0; 1118 bbr->full_bw = 0; 1119 bbr->full_bw_cnt = 0; 1120 bbr->cycle_mstamp = 0; 1121 bbr->cycle_idx = 0; 1122 bbr_reset_lt_bw_sampling(sk); 1123 bbr_reset_startup_mode(sk); 1124 1125 bbr->ack_epoch_mstamp = tp->tcp_mstamp; 1126 bbr->ack_epoch_acked = 0; 1127 bbr->extra_acked_win_rtts = 0; 1128 bbr->extra_acked_win_idx = 0; 1129 bbr->extra_acked[0] = 0; 1130 bbr->extra_acked[1] = 0; 1131 1132 cmpxchg(&sk->sk_pacing_status, SK_PACING_NONE, SK_PACING_NEEDED); 1133 } 1134 1135 static u32 bbr_sndbuf_expand(struct sock *sk) 1136 { 1137 /* Provision 3 * cwnd since BBR may slow-start even during recovery. */ 1138 return 3; 1139 } 1140 1141 /* In theory BBR does not need to undo the cwnd since it does not 1142 * always reduce cwnd on losses (see bbr_main()). Keep it for now. 1143 */ 1144 static u32 bbr_undo_cwnd(struct sock *sk) 1145 { 1146 struct bbr *bbr = inet_csk_ca(sk); 1147 1148 bbr->full_bw = 0; /* spurious slow-down; reset full pipe detection */ 1149 bbr->full_bw_cnt = 0; 1150 bbr_reset_lt_bw_sampling(sk); 1151 return tcp_sk(sk)->snd_cwnd; 1152 } 1153 1154 /* Entering loss recovery, so save cwnd for when we exit or undo recovery. */ 1155 static u32 bbr_ssthresh(struct sock *sk) 1156 { 1157 bbr_save_cwnd(sk); 1158 return tcp_sk(sk)->snd_ssthresh; 1159 } 1160 1161 static size_t bbr_get_info(struct sock *sk, u32 ext, int *attr, 1162 union tcp_cc_info *info) 1163 { 1164 if (ext & (1 << (INET_DIAG_BBRINFO - 1)) || 1165 ext & (1 << (INET_DIAG_VEGASINFO - 1))) { 1166 struct tcp_sock *tp = tcp_sk(sk); 1167 struct bbr *bbr = inet_csk_ca(sk); 1168 u64 bw = bbr_bw(sk); 1169 1170 bw = bw * tp->mss_cache * USEC_PER_SEC >> BW_SCALE; 1171 memset(&info->bbr, 0, sizeof(info->bbr)); 1172 info->bbr.bbr_bw_lo = (u32)bw; 1173 info->bbr.bbr_bw_hi = (u32)(bw >> 32); 1174 info->bbr.bbr_min_rtt = bbr->min_rtt_us; 1175 info->bbr.bbr_pacing_gain = bbr->pacing_gain; 1176 info->bbr.bbr_cwnd_gain = bbr->cwnd_gain; 1177 *attr = INET_DIAG_BBRINFO; 1178 return sizeof(info->bbr); 1179 } 1180 return 0; 1181 } 1182 1183 static void bbr_set_state(struct sock *sk, u8 new_state) 1184 { 1185 struct bbr *bbr = inet_csk_ca(sk); 1186 1187 if (new_state == TCP_CA_Loss) { 1188 struct rate_sample rs = { .losses = 1 }; 1189 1190 bbr->prev_ca_state = TCP_CA_Loss; 1191 bbr->full_bw = 0; 1192 bbr->round_start = 1; /* treat RTO like end of a round */ 1193 bbr_lt_bw_sampling(sk, &rs); 1194 } 1195 } 1196 1197 static struct tcp_congestion_ops tcp_bbr_cong_ops __read_mostly = { 1198 .flags = TCP_CONG_NON_RESTRICTED, 1199 .name = "bbr", 1200 .owner = THIS_MODULE, 1201 .init = bbr_init, //初始化 1202 .cong_control = bbr_main, //main函数 1203 .sndbuf_expand = bbr_sndbuf_expand, //send缓冲区变化 1204 .undo_cwnd = bbr_undo_cwnd, //撤销cwnd(不需要) 1205 .cwnd_event = bbr_cwnd_event, //保存cwnd的值防止丢失 1206 .ssthresh = bbr_ssthresh, //设置拥塞阚值 1207 .min_tso_segs = bbr_min_tso_segs, //覆盖sysctl的tcp_min_tso_segs 1208 .get_info = bbr_get_info, //获取info 1209 .set_state = bbr_set_state, //设置状态,只有状态为TCP_CA_Loss时起作用 1210 }; 1211 1212 static int __init bbr_register(void) 1213 { 1214 BUILD_BUG_ON(sizeof(struct bbr) > ICSK_CA_PRIV_SIZE); 1215 return tcp_register_congestion_control(&tcp_bbr_cong_ops); 1216 } 1217 1218 static void __exit bbr_unregister(void) 1219 { 1220 tcp_unregister_congestion_control(&tcp_bbr_cong_ops); 1221 } 1222 1223 module_init(bbr_register); 1224 module_exit(bbr_unregister);