1、什么是哨兵
哨兵是对Redis的系统的运行情况的监控,它是一个独立进程,功能有二个:
监控主数据库和从数据库是否运行正常;
主数据出现故障后自动将从数据库转化为主数据库;
2、原理
单个哨兵的架构:
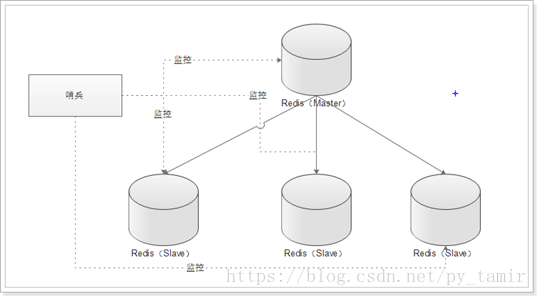
多个哨兵的架构:

多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控。
多个哨兵,防止哨兵单点故障。
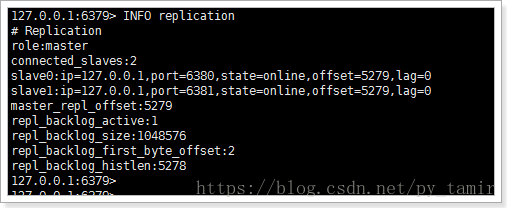
3、环境
当前处于一主多从的环境中:
4、设置哨兵
启动哨兵进程首先需要创建哨兵配置文件:
vim sentinel.conf
输入内容:
sentinel monitor taotaoMaster 127.0.0.1 6379 1
说明:
taotaoMaster:监控主数据的名称,自定义即可,可以使用大小写字母和“.-_”符号
127.0.0.1:监控的主数据库的IP
6379:监控的主数据库的端口
1:最低通过票数
启动哨兵进程:
redis-sentinel ./sentinel.conf

由上图可以看到:
哨兵已经启动,它的id为9059917216012421e8e89a4aa02f15b75346d2b7
为master数据库添加了一个监控
发现了2个slave(由此可以看出,哨兵无需配置slave,只需要指定master,哨兵会自动发现slave)
5、从宕机及恢复
kill掉2826进程后,30秒后哨兵的控制台输出:
2989:X 05 Jun 20:09:33.509 # +sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
说明已经监控到slave宕机了,那么,如果我们将3380端口的redis实例启动后,会自动加入到主从复制吗?
2989:X 05 Jun 20:13:22.716 * +reboot slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
2989:X 05 Jun 20:13:22.788 # -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
可以看出,slave从新加入到了主从复制中。-sdown:说明是恢复服务。
6、主宕机及恢复
哨兵控制台打印出如下信息:
2989:X 05 Jun 20:16:50.300 # +sdown master taotaoMaster 127.0.0.1 6379 说明master服务已经宕机
2989:X 05 Jun 20:16:50.300 # +odown master taotaoMaster 127.0.0.1 6379 #quorum 1/1
2989:X 05 Jun 20:16:50.300 # +new-epoch 1
2989:X 05 Jun 20:16:50.300 # +try-failover master taotaoMaster 127.0.0.1 6379 开始恢复故障
2989:X 05 Jun 20:16:50.304 # +vote-for-leader 9059917216012421e8e89a4aa02f15b75346d2b7 1 投票选举哨兵leader,现在就一个哨兵所以leader就自己
2989:X 05 Jun 20:16:50.304 # +elected-leader master taotaoMaster 127.0.0.1 6379 选中leader
2989:X 05 Jun 20:16:50.304 # +failover-state-select-slave master taotaoMaster 127.0.0.1 6379 选中其中的一个slave当做master
2989:X 05 Jun 20:16:50.357 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 选中6381
2989:X 05 Jun 20:16:50.357 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 发送slaveof no one命令
2989:X 05 Jun 20:16:50.420 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 等待升级master
2989:X 05 Jun 20:16:50.515 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ taotaoMaster 127.0.0.1 6379 升级6381为master
2989:X 05 Jun 20:16:50.515 # +failover-state-reconf-slaves master taotaoMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:50.566 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:51.333 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:52.382 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6379
2989:X 05 Jun 20:16:52.438 # +failover-end master taotaoMaster 127.0.0.1 6379 故障恢复完成
2989:X 05 Jun 20:16:52.438 # +switch-master taotaoMaster 127.0.0.1 6379 127.0.0.1 6381 主数据库从6379转变为6381
2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ taotaoMaster 127.0.0.1 6381 添加6380为6381的从库
2989:X 05 Jun 20:16:52.438 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 添加6379为6381的从库
2989:X 05 Jun 20:17:22.463 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 发现6379已经宕机,等待6379的恢复
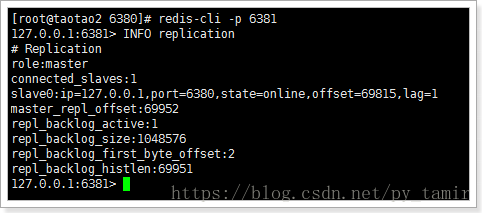
可以看出,目前,6381位master,拥有一个slave为6380.
接下来,我们恢复6379查看状态:
2989:X 05 Jun 20:35:32.172 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 6379已经恢复服务
2989:X 05 Jun 20:35:42.137 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ taotaoMaster 127.0.0.1 6381 将6379设置为6381的slave

7、配置多个哨兵
vim sentinel.conf
输入内容:
sentinel monitor taotaoMaster1 127.0.0.1 6381 1
sentinel monitor taotaoMaster2 127.0.0.1 6381 2

8、为什么哨兵至少3个节点
哨兵集群必须部署2个以上节点。如果哨兵集群仅仅部署了个2个哨兵实例,那么它的majority就是2(2的majority=2,3的majority=2,5的majority=3,4的majority=2),如果其中一个哨兵宕机了,就无法满足majority>=2这个条件,那么在master发生故障的时候也就无法进行主从切换。
9、脑裂以及redis数据丢失
主备切换的过程,可能会导致数据丢失
(1)异步复制导致的数据丢失
因为master -> slave的复制是异步的,所以可能有部分数据还没复制到slave,master就宕机了,此时这些部分数据就丢失了
(2)脑裂导致的数据丢失
脑裂,也就是说,某个master所在机器突然脱离了正常的网络,跟其他slave机器不能连接,但是实际上master还运行着
此时哨兵可能就会认为master宕机了,然后开启选举,将其他slave切换成了master,这个时候,集群里就会有两个master,也就是所谓的脑裂。
此时虽然某个slave被切换成了master,但是可能client还没来得及切换到新的master,还继续写向旧master的数据可能也丢失了,因此旧master再次恢复的时候,会被作为一个slave挂到新的master上去,自己的数据会清空,重新从新的master复制数据
10、如何尽可能减少数据丢失
下面两个配置可以减少异步复制和脑裂导致的数据丢失:
|
1
2
|
min-slaves-to-write 1min-slaves-max-lag 10 |
解释:要求至少有1个slave,数据复制和同步的延迟不能超过10秒,如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了
(1)减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低的可控范围内
(2)减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保说,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求,这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失
上面的配置就确保了,如果跟任何一个slave丢了连接,在10秒后发现没有slave给自己ack,那么就拒绝新的写请求。
因此在脑裂场景下,最多就丢失10秒的数据
11、哨兵集群的自动发现机制
哨兵互相之间的发现,是通过redis的pub/sub系统实现的,每个哨兵都会往sentinel:hello这个channel里发送一个消息,这时候所有其他哨兵都可以消费到这个消息,并感知到其他的哨兵的存在
每隔两秒钟,每个哨兵都会往自己监控的某个master+slaves对应的sentinel:hello channel里发送一个消息,内容是自己的host、ip和runid还有对这个master的监控配置
每个哨兵也会去监听自己监控的每个master+slaves对应的sentinel:hello channel,然后去感知到同样在监听这个master+slaves的其他哨兵的存在
每个哨兵还会跟其他哨兵交换对master的监控配置,互相进行监控配置的同步