目录结构:
一,集合概述
1.1什么是集合
集合是对一组存储数据类的统称,相关的类都存放在java.util包中。
Collection:
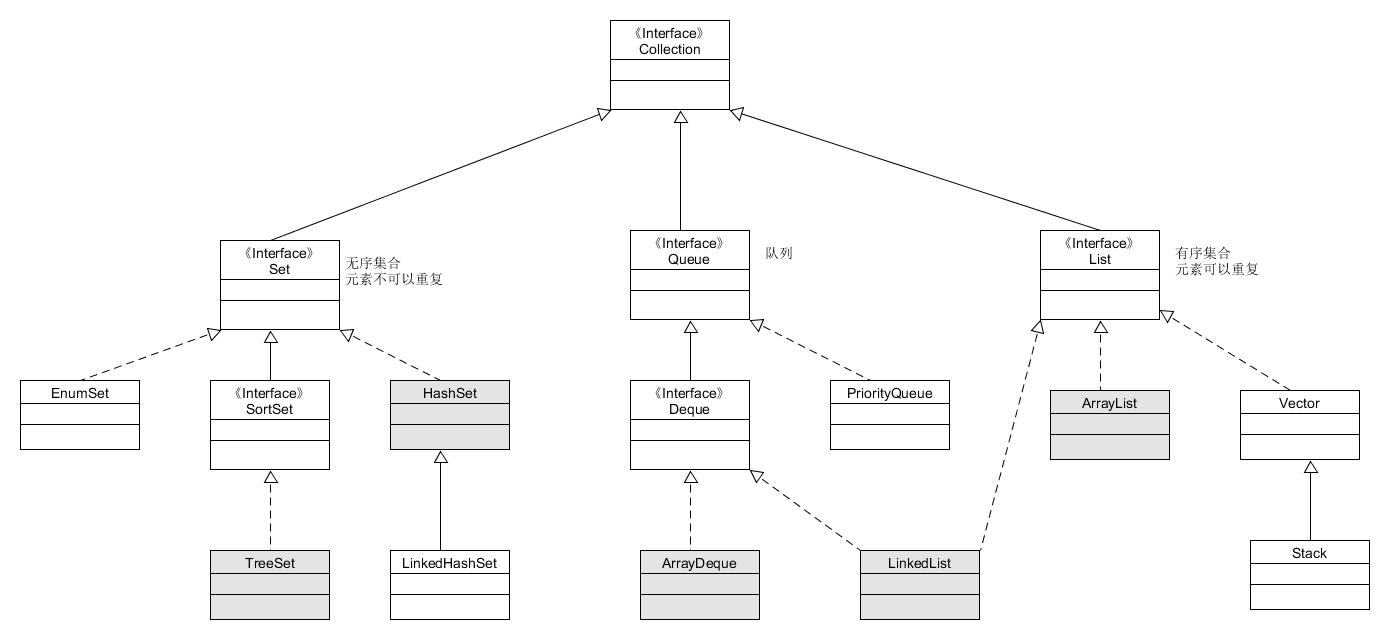
Map:

图中灰底的类是比较常用的类,从上面的图片中我们可以看出,
集合分为两大类:Collection和Map
1.2 Collection和Map的区别
Collection接口中存放的是单个元素
Map接口存放的是单对元素
1.3 List和Set的区别
List接口是有序的,其中的元素可以重复
Set接口是无序的,其中的元素不可以重复
1.4 ArrayList和LinkedList的区别
ArrayList的底层实现是动态数组结构的,查找和修改元素方便,增加和删除元素不方便。
LinkedList的底层实现是链表结构,增加和删除元素方便,查找和修改元素不方便。
1.5 HashSet和TreeSet的区别
HashSet的底层是基于HashCode表进行存储的。
TreeSet的底层是基于平衡有序二叉树(又称红黑树)实现的。
1.6 HashMap和TreeMap的区别
HashMap,TreeMap的底层和Set接口中HashSet,TreeSet底层实现结构类似。Set中只能存放单个元素,Map中只能存储单对元素。
1.7 List,Set,Map的比较
List接口是有序的,存储的是单个元素,元素允许重复。
Set接口是无序的,存储的是单个元素,元素不允许重复。
Map接口是采用(key)键-(value)值进行存储,其中key不允许重复,value允许重复。
二,List接口及其常用实现类
List中的元素是有序的。实现List接口中的常用子类有:ArrayList,LinkedList,Stack,Vector
2.1 ArrayList类
由于数组是内存中一段连续的存储空间,因此可以非常方便地通过下标来访问和修改元素。如果在数组的开始和末尾增加或删除元素还比较容易,但是在数组中间增加或是删除某个元素,那么就需要移动其它的元素位置,若数组长度非常大,那么移动的元素就非常多,效率就比较低。
由于ArrayList的底层实现和数组类似,下面通过一个简单的Demo来看一看:
1 int []arr=new int[10]; 2 /* 3 * 赋值 4 */ 5 for(int i=0;i<arr.length;i++){ 6 arr[i]=i; 7 } 8 /* 9 * 打印 10 */ 11 System.out.print("原数组:"); 12 for(int i:arr){ 13 System.out.print(i+" ");// 0 1 2 3 4 5 6 7 8 9 14 } 15 System.out.println(); 16 /* 17 * 移除数组下表为6的元素 18 */ 19 int index=5; 20 for(int i=index;i<arr.length-1;i++){ 21 arr[i]=arr[i+1]; 22 } 23 /* 24 * 打印 25 */ 26 System.out.print("修改后:"); 27 for(int i:arr){ 28 System.out.print(i+" ");// 0 1 2 3 4 6 7 8 9 9 29 }
上面的代码移除了原数组下标为6的元素,并且移动了数组4次。
ArrayList的底层是采用动态数组实现的,访问和修改方便,增删不方便。
2.2 LinkedList类
附上一张图片来说明LinkedList和ArrayList的区别
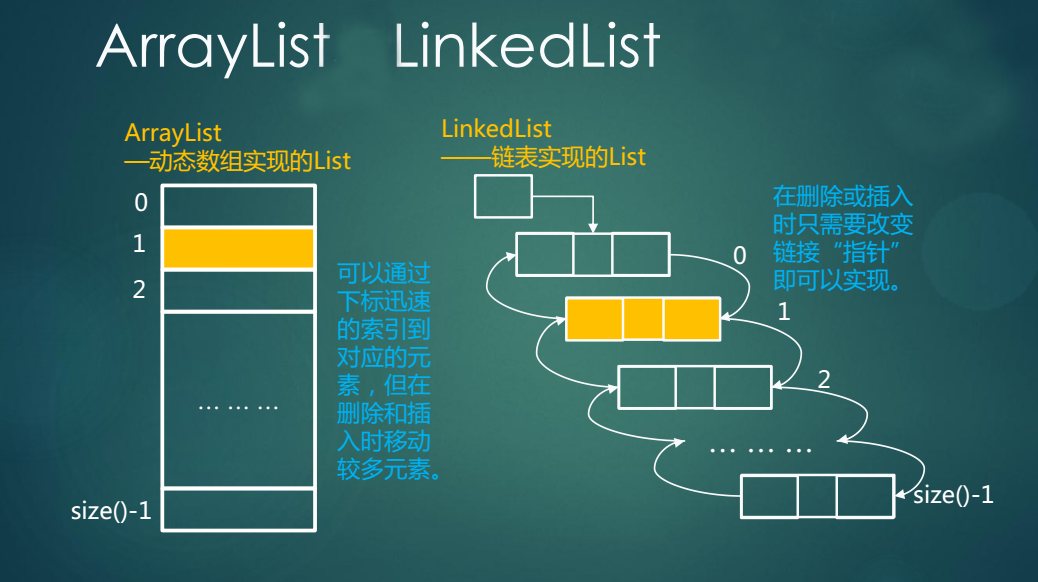
LinkedList类的底层是采用动态链表实现的,增删方便,访问和修改不方便。
2.3 Stack类
该类的数据存储结构同栈类似,也是后进先出。
Stack类是采用动态数组的方式实现的,该类是一种具有后进先出特性的数据结构,简称LIFO(Last Input First Output)。
Stack类是Vector类的一个子类,它模拟了“栈”这种数据存储结构,Stack类是一个古老的类,也是线程安全、效率较低的一个类。不建议使用Stack类,如果需要“栈”这种结构可以考虑使用ArrayDeque代替。
2.4 Vector类
该类是采用动态数组的方式实现的,与ArrayList类相比,支持线程安全,效率比较低,Java官方推荐使用ArrayList。
到这里都知道Vector和ArrayList都是List的实现类,在上面关于ArrayList的介绍中,我们已经知道了ArrayList其实是基于动态数组结构的,其实Vector和ArrayList类似,也是基于动态数组。ArrayList和Vector对象是采用initialCapacity参数来设置数组的长度,当ArrayList对象和Vector对象添加的元素超过了数组的长度,initialCapacity会自动增加。如果在创建ArrayList和Vector对象的时候不指定initialCapacity的值,默认的长度是10。我们已经知道官方推荐使用ArrayList代替Vector,那么如何解决ArrayList不是线程安全的问题呢?其实JDK官方提供一个Collections的工具类,可以使用该类实现ArrayList的线程安全,比如: ArrayList arrayList= Collections.synchronizedList(new ArrayList(...));
2.5 其它
2.5.1 在List集合中存储自定义数据
在List集合中的数据是按照数组结构存储的,因此如果在List集合中存储自定义类数据的时候,不需要在自定义类中继承或是实现某些特殊的接口。
Student类:


1 public class Student { 2 3 private String name;//姓名 4 private int age;//年龄 5 6 public Student() { 7 super(); 8 } 9 10 public Student(String name, int age) { 11 super(); 12 setName(name); 13 setAge(age); 14 } 15 16 public String getName() { 17 return name; 18 } 19 20 public void setName(String name) { 21 this.name = name; 22 } 23 24 public int getAge() { 25 return age; 26 } 27 28 public void setAge(int age) { 29 this.age = age; 30 } 31 }
TestStudent类:
public class TestStudent{ public static void main(String[] args) { /* * 创建一个只能存放Student对象的实现List接口的集合 */ List<Student> lt=new ArrayList<Student>(); /* * 增加数据 */ lt.add(new Student("jame",2001)); lt.add(new Student("john",2002)); lt.add(new Student("Locy",2003)); /* * 打印数据 */ for(Student stu:lt){ System.out.println(stu.getName()+","+stu.getAge()); } } }
上面的代码中Student类并没有继承或是实现某些特殊的类或是接口,依然能够存放到ArrayList集合中,这和ArrayList的底层的数据存储结构是有关的。因为ArrayList对每个元素都有唯一的索引下标,只需要把元素放到指定的下标位置即可,而无需Student类去实现或是继承某些特殊的接口或是类。
2.5.2 互调List集合中的两个数据
互调两个数据,笔者在脑海中最开始闪现出来的算法如下:
temp = i; i=j; j=temp;
但是我们可以使用List集合中set和get方法,其中set(int index,E element)方法的返回值比较特别:
public E set(int index,E element) 功能:将此列表中指定位置的元素替换为指定的元素 返回值:以前在指定位置的元素
set方法的返回值是被替换掉的元素,我们可以通过这个特点,来快速地实现List接口实现类集合中两个元素的互调。
list.set(i, list.set(j, list.get(i)));
上面的模板实现了互调下标为i的元素和下标为j的元素,下面以LinkedList为例:
1 public class TestStudent{ 2 3 public static void main(String[] args) { 4 /* 5 * 创建一个只能存放Student对象的实现List接口的集合 6 */ 7 List<Student> lt=new LinkedList<Student>(); 8 /* 9 * 增加数据 10 */ 11 lt.add(new Student("jame",2001)); 12 lt.add(new Student("john",2002)); 13 lt.add(new Student("Locy",2003)); 14 /* 15 * 打印数据 16 */ 17 for(Student stu:lt){ 18 System.out.println(stu.getName()+","+stu.getAge()); 19 } 20 /* 21 * 互调学生Locy和jame在List集合中位置 22 */ 23 lt.set(0, lt.set(2, lt.get(0))); 24 /* 25 * 再次打印 26 */ 27 System.out.println("-------------------------"); 28 for(Student stu:lt){ 29 System.out.println(stu.getName()+","+stu.getAge()); 30 } 31 } 32 33 }
最后读者需要注意,使用List和Map接口的实现类可以使用这种方式快速互调两个元素,但是有set接口因为本身存储数据的结构问题,并没有提供这样的方法。
三,Queue接口及其常用实现类
队列(Queue)是常用的数据存储结构,可以将队列看成特殊的线性表,队列限制了对线性表的访问方式:只能从线性表的一段访问(OFFER)元素,从另一端取出(POLL)元素。
队列(Queue)遵循先进先出(First Input First Output 简称FIFO)的原则。
Queue接口下面有一个Deque接口,Deque接口是具有双端队列的特性的接口,Deque接口的实现类是既可以作为模拟队列这种数据结构,又可以作为模拟栈的数据结构。Deque的实现类常见有ArrayDequ和LinkedList,
ArrayDeque的底层是基于动态数组的,在创建ArrayDeque的时候可以通过numElements参数指定数组的长度,如果不指定,那么默认大小是16.
3.1 LinkedList类
LinkedList是一个比较特殊类,LinkedList和ArrayDeque都同时实现了Deque接口,实现了Deque接口的实体类既可作为栈使用,也可以作为单/双端队列使用。不过LinkedList不仅仅实现了Deque接口,还实现了List接口,也就是说LinkedList类具有三种特性,栈、单/双端队列、List特性。
在前面已经介绍了LinkedList底层是基于链表结构,所以具有插入、删除数据方便,查询数据不方便的特点。
四,Set接口及其常用实现类
Set中的元素是无序的,不允许有重复的元素,而且set和list都是Collection的子接口因此都只能存储单个元素。主要的实现类包括:HashSet()和TreeSet()方法
4.1 HashSet
附上一张关于哈希表的图片
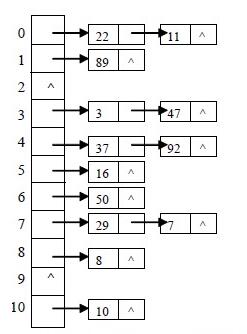
这个里hashCode分配的长度是11,上面的数据对11取余恰好对应其前面的数字。假设目前需要32,那么首先用33对11取余得到0,然后再用33调用equals方法和上面的22,11比是否相等,很显然33不等于22,11,所以33会被分配到11的后面。
HashSet的底层是采用哈希值判断数据在哪个篮子里,然后再用equals方法进行比较看该数据是否存在。
4.1.1 在HashSet中存储自定义数据
在HashSet中存储自定义数据和List接口下的ArrayList(或是LinkedList)不同,因为HashSet的底层是使用HashCode结合equals方法进行管理,因此被存储的数据类必须重写equals和hashCode方法:
下面看一个示例:
1 public class Student { 2 3 private String name; 4 private int id; 5 public Student() { 6 super(); 7 } 8 public Student(String name, int id) { 9 super(); 10 setName(name); 11 setId(id); 12 } 13 14 public String getName() { 15 return name; 16 } 17 public void setName(String name) { 18 this.name = name; 19 } 20 public int getId() { 21 return id; 22 } 23 public void setId(int id) { 24 this.id = id; 25 } 26 /* 27 * 该类继承Object,重写其中的hashCode()和equals()方法,按照学号进行比较 28 */ 29 @Override 30 public int hashCode() { 31 final int prime = 31; 32 int result = 1; 33 result = prime * result + id; 34 return result; 35 } 36 @Override 37 public boolean equals(Object obj) { 38 if (this == obj) 39 return true; 40 if (obj == null) 41 return false; 42 if (getClass() != obj.getClass()) 43 return false; 44 Student other = (Student) obj; 45 if (id != other.id) 46 return false; 47 return true; 48 } 49 }
接下来是一个测试类:
1 public class TestHashSet { 2 3 public static void main(String []args){ 4 /* 5 * 创建一个只能存储Student对象的HashSet对象 6 */ 7 HashSet<Student> hst=new HashSet<Student>(); 8 hst.add(new Student("jame",23)); 9 hst.add(new Student("jame",23)); 10 /* 11 * 打印所有数据,结果只有一个数据,这是因为Set集合不允许存在重复元素 12 */ 13 for(Student st:hst){ 14 System.out.println(st); 15 } 16 } 17 }
学生对象的存储过程和上面的列子类似,当我们存储第一个Student对象的时候,会得到一个HashCode值,通过计算可得出是54。然后在储存第二个对象的时候又会得到一个HashCode值,通过计算也可以得出是54,换句话说,这两个对象在同一个“篮子”里,然后该对象再调用equals(Object obj)方法和“篮子”里以前的对象比较是否相等,如果相等就不存入,如果不相等就存入,显然笔者传入的两个对象是相等的,所以最终只有一个数据。
4.2 TreeSet
TreeSet的底层是基于平衡二叉树(又称为红黑树)的,
由于TreeSet的底层是采用二叉树管理的,被TreeSet存储的元素必须实现java.lang.Comparable接口并且重写compareTo()方法,或在创建集合时传入java.util.Comparator对象并且重写compare()方法
4.2.1 自然排序法
自然排序法就是实现java.lang.Comparable接口,重写compareTo()方法,这是API中大部分类都是实现的,读者可以打开API验证,
1 public class Student implements Comparable<Student> { 2 3 private String name; 4 private int id; 5 public Student() { 6 super(); 7 } 8 public Student(String name, int id) { 9 super(); 10 setName(name); 11 setId(id); 12 } 13 14 public String getName() { 15 return name; 16 } 17 public void setName(String name) { 18 this.name = name; 19 } 20 public int getId() { 21 return id; 22 } 23 public void setId(int id) { 24 this.id = id; 25 } 26 /* 27 * 重写Comparable接口中的compareTo方法 28 * 按照id进行比较 29 */ 30 @Override 31 public int compareTo(Student o) { 32 return getId()-o.getId(); 33 } 34 }
1 public class TestTreeSet { 2 3 public static void main(String[] args) { 4 Set<Student> st=new TreeSet<Student>(); 5 6 st.add(new Student("johe",21)); 7 st.add(new Student("jake",35)); 8 st.add(new Student("brave",12)); 9 10 for(Student s:st){ 11 System.out.println(s.getId()+","+s.getName()); 12 } 13 } 14 15 }
4.2.2 比较器
比较器就是在创建集合时传入java.util.Comparator对象,重写compare()方法,其实现原理和自然排序法类似。
1 public class Student { 2 3 private String name; 4 private int id; 5 public Student() { 6 super(); 7 } 8 public Student(String name, int id) { 9 super(); 10 setName(name); 11 setId(id); 12 } 13 14 public String getName() { 15 return name; 16 } 17 public void setName(String name) { 18 this.name = name; 19 } 20 public int getId() { 21 return id; 22 } 23 public void setId(int id) { 24 this.id = id; 25 } 26 }
1 public class TestTreeSet { 2 3 public static void main(String[] args) { 4 Set<Student> st=new TreeSet<Student>(new Comparator<Student>(){ 5 6 /* 7 * 重写Comparator接口总compare()方法 8 */ 9 @Override 10 public int compare(Student o1, Student o2) { 11 return o1.getName().compareTo(o2.getName()); 12 } 13 }); 14 st.add(new Student("johe",21)); 15 st.add(new Student("jake",35)); 16 st.add(new Student("brave",12)); 17 18 for(Student s:st){ 19 System.out.println(s.getId()+","+s.getName()); 20 } 21 } 22 }
自然排序法可以重复利用,比较器只能使用一次。
4.3 Set集合中迭代器
对Set集合中的数据的遍历、修改和有点不同,List集合既可以调用add或是get等等方法来实现,也可以创建迭代器(Iterator)来实现,但是Set集合是通过迭代器来实现的。
如:
Set<String> st=new HashSet<String>(); st.add("abc"); st.add("ab"); st.add("ac"); //创建迭代器 Iterator<String> it=st.iterator(); while(it.hasNext()){ System.out.print(it.next()+" ");//abc ac ab }
五,Map接口
Map是采用键-值进行数据存储的。相比读者肯定知道Map集合和Set集合非常相似,其实Set集合的实现就是基于Map集合。在Set集合的源码中,将Set集合存储的值放到Map集合的Key上,然后将Value值设置为一个无意义的Object对象,这样就显示了Set集合。
5.1 TreeMap,HashMap
TreesMap的底层实现和TreeSet类似
HashMap的底层实现和HashSet类似
5.2 在Map中互调两个数据
由于Map集合中的“ V put(K key, V value) ”方法和List集合中的“ E set(int index, E element) ”功能类似,并且put方法的返回值是以前与key关联的值。
map.put(i,map.put(j,map.get(i)));
看一个实例:
1 public class TestMap { 2 3 public static void main(String[] args) { 4 /* 5 * create a Map value 6 */ 7 Map<Integer,String> mp=new HashMap<Integer,String>(); 8 /* 9 * put value 10 */ 11 mp.put(1, "a"); 12 mp.put(2, "b"); 13 mp.put(3, "c"); 14 /* 15 * print mp value 16 */ 17 System.out.println("before:"+mp); 18 /* 19 * exchange two value from one to another 20 */ 21 int i=1; 22 int j=3; 23 mp.put(i,mp.put(j,mp.get(i))); 24 /* 25 * print mp value 26 */ 27 System.out.println("after:"+mp); 28 29 } 30 31 }
5.3 Map转化其它集合的方法
Map中提供了三种方法将Map集合转化为其它集合的方法,分别是 Set<Map.Entry<K,V>> entrySet() , Set<K> keySet() , Collection<V> values() 方法
5.3.1 keySet()方法的使用
1 public class TestEntrySet { 2 3 public static void main(String[] args) { 4 /* 5 * 创建一个将Integer和String关联起来的Map对象 6 */ 7 Map<Integer,String> hp=new TreeMap<Integer,String>(); 8 9 hp.put(1, "a"); 10 hp.put(2, "b"); 11 /* 12 * 获得Set视图 13 */ 14 Set<Integer> set=hp.keySet(); 15 /* 16 * 使用增加版For循环打印 17 */ 18 for(Integer i:set){ 19 System.out.println(hp.get(i)); 20 } 21 /* 22 * 使用迭代器再次打印 23 */ 24 Iterator<Integer> it=set.iterator(); 25 while(it.hasNext()){ 26 System.out.println(hp.get(it.next())); 27 } 28 } 29 30 }
5.3.2 entrySet()方法的使用
1 public class TestEntrySet { 2 3 public static void main(String[] args) { 4 /* 5 * 创建一个将Integer和String关联起来的Map对象 6 */ 7 Map<Integer,String> hp=new TreeMap<Integer,String>(); 8 9 hp.put(1, "a"); 10 hp.put(2, "b"); 11 /* 12 * Map.Entry<k,v>对象 13 * 其中有getKey(),getValue(),setValue()等等操作方法 14 */ 15 Set<Map.Entry<Integer, String>> set=hp.entrySet(); 16 /* 17 * 使用增加版For循环打印 18 */ 19 for(Map.Entry<Integer, String> i:set){ 20 System.out.println(i.getKey()+"="+i.getValue()); 21 } 22 } 23 24 }
5.3.3 values()方法的使用
1 public class values{ 2 3 public static void main(String[] args) { 4 /* 5 * 创建一个将Integer和String关联起来的Map对象 6 */ 7 Map<Integer,String> hp=new TreeMap<Integer,String>(); 8 9 hp.put(1, "a"); 10 hp.put(2, "b"); 11 12 /* 13 * 使用values()方法,获得只能是键-值对中的值,也就是所有key对应value的一个集合 14 */ 15 Collection<String> c=hp.values(); 16 /* 17 * 使用增加版For循环打印 18 */ 19 for(String i:c){ 20 System.out.println(i); 21 } 22 } 23 24 }