HBase表模式的设计
对于HBase表,在设计表结构之前,我们需要先考虑的几个问题:
- 这个表应该有多少个列族?
- 列族使用的是什么数据?
- 每个列族应该有多少列?
- 列名应该是什么?尽管列名不必在建表的时候定义,但是后期读写数据时是需要知道的。
- 单元存放什么数据?
- 每个单元存储多少个时间版本?
- 行健结构是什么?应该包含什么信息?
模式影响到表结构和如何读写表,所以说把这些放到宽泛的模式设计中变得尤为重要。
一、HBase的存储方式
HBase底层物理存储是基于HDFS,在HDFS上是以HFile的形式进行存储的:
- 表中的列族在HDFS上是以HFile的形式存在,一个HFile对应一个列族,但是一个列族可能会对应多个HFile。
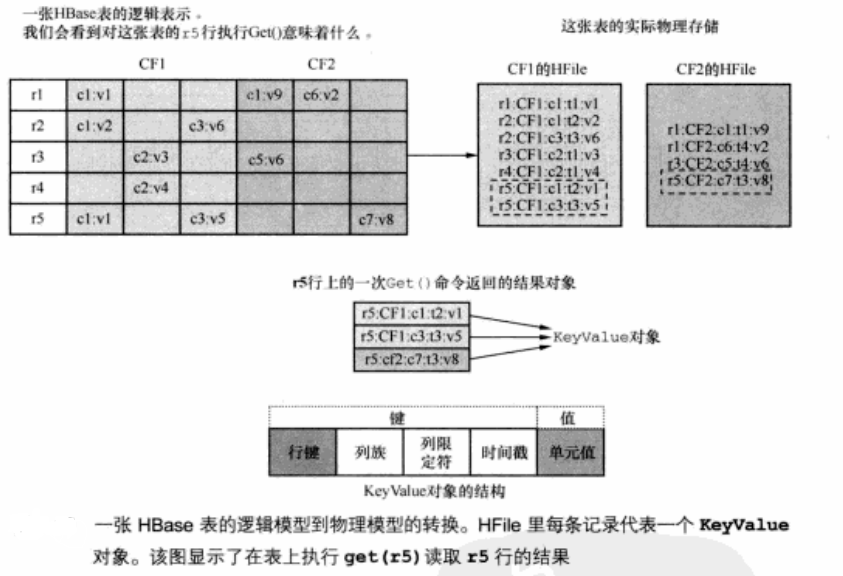
一个特定的列族的所有数据在HDFS上会有一个物理存储,这个物理存储区可能会有多个HFile组成,理论上可以通过合并来得到一个HFile,一个列族的所有列在硬盘上是存放在一起的,使用这个特性,可以把不同模式的列放在不同的列族,以便隔离他们。这也是HBase面相列族存储的原因。
二、宽表与高表
- 宽表:
HBase中所谓的宽表,指的是表中行少而列多,也就是说一行当中包含有很多的列,但是表整体行很少,比如一张表中行健一共有100个,但是每个行健所包含的列有1000个,这种就是所谓的宽表。
- 高表
HBase中所谓的高表,恰好与宽表相反,行多,列少。比如一张表中行有100万条,而每行对应的列却又10个,这既是所谓的高表。
三、HBase的访问时间复杂度
为了便于描述,先定义以下变量:
- n = 表中KeyValue条目数量(包括Put的结果和Delete留下的墓碑标记)
- b = HFile中数据块的数量(HFile Block)
- e = 平均一个HFile中一个KeyValue条目的数量(如果知道行的大小,可以进行计算出来)
- c = 每行中列的平均数量
先定义针对指定行健查找相关HFile数据块需要的时间。无论是在单行上执行get(),还是为一次扫描查找起始键,都会有这个动作。
第一步、客户端需要先找到正确的HRegionServer和region。需要花费3次固定运算找到正确的region,1、查找zk,2、查找-ROOT-,3、查找.META.这是一次O(1)的运算。
在指定region上,行在读的过程中可能存在于两个地方,如果还没有刷写到磁盘就位于memStore,如果已经刷鞋,则位于一个HFile中。假定只有一个HFile,这一行要么在文件中,要么还没刷写,在MemStore中。
如果用e代表在任意合理的时间在MemStore的条目数量。
如果一行在MemStore中,因为MemStore是用跳表实现的。所以查找行的时间复杂度是O(log e)。
如果一行已经刷到磁盘上了,那么就需要先找到正确的HFile数据块。数据块索引是排过序的,所以查找正确的数据块是一次时间复杂度为O(log b)的运算。查找行里的KeyValue对象是在数据块里的一次线性扫描操作。在找到第一个KeyValue对象之后,随后查找剩下的对象就是一次线性扫描。
假设行里的单元都在同一个数据块中,扫描的时间复杂度是O(e/b)。
如果行里的单元不在同一个数据块中,这种扫描需要访问多个连续的数据块里的数据,所以这时的运算有读取的行数决定,时间复杂度是O(c)。
也就是说这种扫描的时间复杂度是O(Max(c,e/b))
所以在访问HBase中的数据时,决定性因素是扫描HFile数据块找到相关KeyValue对象所花费的时间。如果是宽行的话,扫描过程中会增加处理整行的开销。以上的这些分析都是基于在知道行健的情况下。
如果不知道行健的话,就需要扫描整个区间(有可能是整张表)来查找你关心的行,而这个时间复杂度是O(n)
这里没有讨论关于硬盘寻道的开销。如果需要从HFile里读取的数据已经被加载进数据缓存中,前面的分析是正确的。因为行健是所有这些索引的决定性因素,所以结论是:访问宽行要比访问窄行开销大。
四、rowkey的散列
HBase的rowkey在设计的时候我们一般都要对其进行散列处理,这样做有以下几个好处:
- 可以得到定长的行健,即行健的长度是同一的,可以更好的预测读写性能
- 可以在扫描表的时候可以方便的设置起始域停止键
- 有助于数据更均匀的分部在region上。减轻或避免发生热点问题
热点:负载极度集中在一小部分的region上。因为负载没有分散的整个集群上,这是不合理的。服务这些region的几台机器承担了绝大部分的工作,将成为整体性能的拼劲。
对rowkey散列,虽然在所有region上实现了一个均匀的分部,但是这样的话就会失去数据的顺序。换句话说,就是不能在扫描一个小的时间范围。要么扫描整个表(scan),要么获取指定的行(get()或get(List))
散列和MD5:
散列函数是把编程的巨长数值映射到定长的小数值上的一种函数。散列算法有很多种,MD5就是其中的一种,也是比较常用的一种。MD5对任何数据进行散列运算生成一个128位(16字节)的散列值。这是一种流行的散列函数,通常生产中,我是对rowkey进行16位的MD5操作。
五、目标数据的访问(重点:索引)
之前谈到关于HBase的高表与宽表,高表有利于快速得到正确的行。而宽表则有利于进行批量写操作。
对于HBase中的索引来说,只有键才可以建立索引(KeyValue对象的key部分,包括行健,列限定符和时间戳),可以将其看作是关系型数据库的主键,但是不能够改变构成主键的列,这里的键是由3个元素复合而成的(行健,列限定符和时间戳)。
在列限定符和时间戳上建立索引,可以在一行上不用扫描前面所有的列而直接跳到正确的列。取回的KeyValue对象基本上来自于HFile的一行。
从表中获取数据的方式有两种,get和scan。如果只是需要获取指定的某行或这个某几行,也就是说在明确知道行健的情况下,建议使用get或get<List>的方式进行获取。
如果知道起始键和停止键,则可以使用scan的方式来限制扫描器扫描的的行数进行获取数据。
在get对象中,可以指定列族和列限定符。当指定列族之后,可以限制客户端只访问指定列族的HFile;当时指定列限定符之后不会限制从硬盘中读出的HFile,只是可以限制网络上传回给客户端的东西。如果给定的region上一个列族存在多个HFile。要查找get()调用里指定的行的内容,不管有多少个HFile包含与请求有关的数据,都要访问所有的HFile。但是get里尽可能的明确查找内容是有必要的,因为不必在网络上传回客户端不需要的数据。唯一的开销也就是RegionServer上可能的硬盘IO,同样,如果get中指定时间戳的话,可以避免读取早于时间戳的HFile。
六、小结
- HBase表很灵活,可以用字符数组形式存储任何东西
- 同一列族中存储相似访问模式的东西
- 索引是建立在KeyValue对象的Key部分上,Key是由行健,列限定符合时间戳按次序组成
- 高表可能支持将运算复杂度降到O(1),但是要在原子性上付出代价
- 设计HBase模式的时候进行范规范化处理是一种可行的办法
- HBase不支持跨行事务,要避免在代码中维护这种复杂的逻辑
- 散列支持定长键和更均匀的数据分部,但是失去了排序的好处
- 列限定符可以用来存储数据,就像单元一样
- 可以将数据放入到列限定符中,所以它的长度会影响到存储空间,当访问数据时,也影响了硬盘和网络IO的开销,所以尽量简练
- 列族名字的长度会影响通过网络传回客户端的数据大小,所以,也尽量简练