聚类:就是将一个对象的集合分成几个簇,每个簇之间的对象不相似,但是簇内对象相似。可以认为是“物以类聚”。
从这个简单的描述中,可以看出聚类的关键是如何度量对象间的相似性。较为常见的用于度量对象的相似度的方法有距离、密度等。
1.分层次聚类法
思路:寻找距离最近的两个样本进行结合。
(1)有N个样本集Zn{Z1,Z2......ZN}
(2)聚成K类(事先定好K)
[1] k=1, Ci={Zi}, i=1,2,...,N
[2] if k=K then END
[3] 找到Ci与Cj之间的距离d(Ci, Cj)最小的一对
[4] Ci和Cj合成一个类Ci, 并计算新的Ci的中心
[5] 去除Cj, k=k-1. goto [2]
2.最简单的聚类
相似性尺度(距离)阈值,不需要事先给定K。
有N个样本,Zs={Z1, Z2, ..., ZN}
给定一个阈值T。
任取一个样本,例如Z1,把Z1作为第一个类的中心,Z1=Z1
然后依次取Zi(i=2,3,...,N),计算Z1与Zi的距离D1i
若D1i≤T,则判定 Zi属于 Z1为中心的那个类;
若D1i>T,则把 Zi作为新的类中心 Z2。
然后对剩下的样本 Zi分别计算与 Z1,Z2的距离D1i,D2i
若其中较小者≤T,则判定 Zi属于较小的那一类
否则,就把 Zi作为新的一个类的中心 Z3
如此,继续...,直至对全体样本做完处理。
3.最大距离样本
思路:取尽可能离得远的样本做中心。
有N个样本,Zs={Z1, Z2, ..., ZN}
[1] 任取一个样本,例如Z1,把Z1作为第一个类的中心,Z1=Z1
[2] 从集合Zs中找出到Z1距离最大的样本作为Z2
[3] 对Zs中剩余样本Zi,分别计算到Z1,Z2的距离。令其中较小的那个为 Dzi
[4] 计算 max{Dzi}若其值大于某一计算值或给定阈值,则取此Zi为新的类中心
[5] 重复同样的处理,直到再也找不到符合条件的新的类中心。
[6] 把剩余样本分配到离它最近的那个中心所属的类
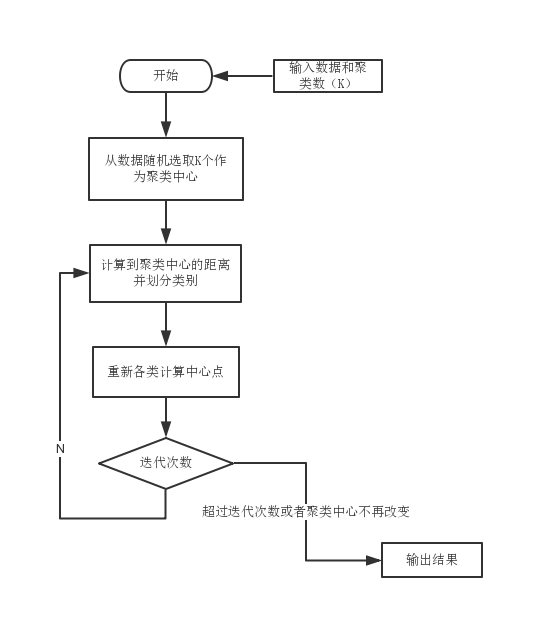
k-Means:
k-Means算法的核心思想是把n个数据对象划分为k个类(这k各类事先未知),使得划分后每个类中的数据点到该类中心的距离最小。即使J最小。
k-means算法流程:
- 输入:分类个数k,包含n个数据对象的数据集
- 输出:k个聚类
- (1)从n个数据对象中任意选取k个对象作为初始的聚类中心;
- (2)分别计算每个对象到各个聚类中心的距离,把对象分配到距离最近的聚类中;
- (3)所有对象分配完成后,重新计算k个聚类的中心; (取各类别的均值)
- (4)与前一次计算得到的k个聚类中心比较(检测是否收敛),如果聚类中心发生变化(未收敛),转(2),否则聚类结束。