1.集成学习
用多个模型来解决一个问题,就是集成
怎么样得到一个好的集成?
需要个体尽可能的精确,而且它们的差异性,多样性尽可能的大
按集成中个体的生成方式来说,可以分为两大方法
- 序列化方法,Adaboost 、GBDT(在这种方法里,每一个新的个体生成和以往的个体都是有联系的)Boosting一族通过将弱学习器提升为强学习器的集成方法来提高预测精度,GBDT也是Boosting的成员
- 并行化方法,Bagging、Random Subspace、Random Forests(所有的个体可以同时来做)Bagging,通过自助采样的方法生成众多并行式的分类器,通过“少数服从多数”的原则来确定最终的结果
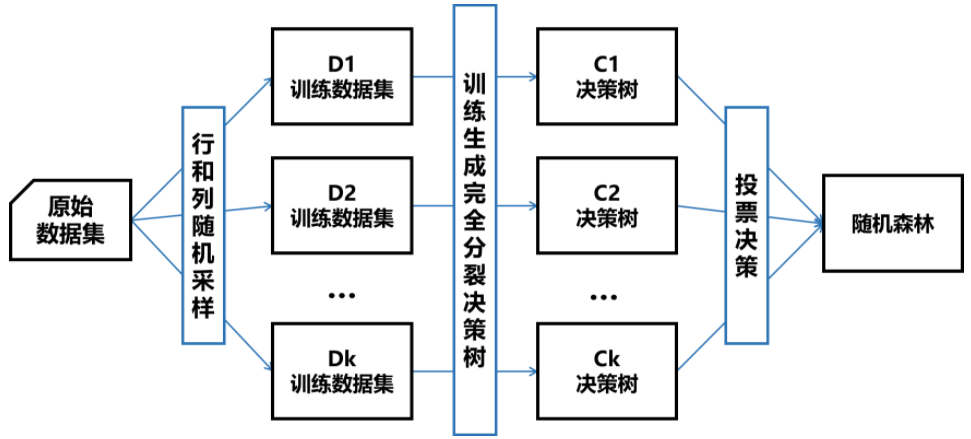
2.随机森林
- bagging思想
一棵树是决策树,多棵树是随机森林,解决了决策树泛化能力弱的缺点。因为决策树是一棵树,它是有一个决策的可能性,如果是多棵树,每棵树都有一个决策权,这样把所有树的结果综合在一起,这样的分类能力会比单棵树的决策能力强很多。
- 随机
随机选择样本
随机选择特征
随机森林中的每棵树是怎么构造的?
每一棵树是从整个训练样本集中,随机选取固定数量的样本集,选取固定数量的特征集,来构建一棵决策树,相当于这个样本数和特征数都是总样本数和总特征集的一个子集,而且是一个有放回的抽取过程。
每一棵决策树都有一个分类结果,有很多决策树,把所有的结果根据少数服从多数的原则综合到一起
- 集成学习
投票选举
随机森林相比于决策树拥有出色的性能主要取决于随机抽取样本、特征和集成算法,前者让它具有更稳定的抗过拟合能力,后者让它有更高的准确率。
想要利用随机森林进行预测,算法首先对森林中的每棵树进行预测。
对于回归问题,我们可以对这些结果去平均值作为最终预测。
对于分类问题,则用到了“软投票”(soft voting)策略。也就是说,每个算法做出“软”预测,给出每个可能的输出标签的概率。对于所有树的预测概率取平均值,然后将概率最大的类别作为预测结果。
例子:
描述:根据已有的训练集已经生成了对应的随机森林,随机森林如何利用某一个人的年龄(Age)、性别(Gender)、教育情况(Highest Educational Qualification)、工作领域(Industry)以及住宅地(Residence)共5个字段来预测他的收入层次。
收入层次 :
Band 1 : Below $40,000
Band 2: $40,000 – 150,000
Band 3: More than $150,000
随机森林中每一棵树都可以看做是一棵CART(分类回归树),这里假设森林中有5棵CART树,总特征个数N=5,我们取m=1(这里假设每个CART树对应一个不同的特征)。

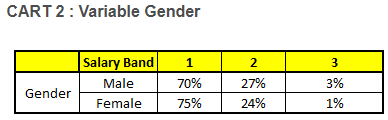
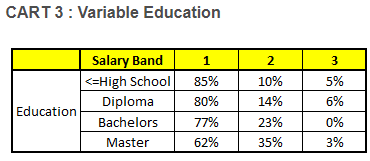

我们要预测的某个人的信息如下:
1. Age : 35 years ; 2. Gender : Male ; 3. Highest Educational Qualification : Diploma holder; 4. Industry : Manufacturing; 5. Residence : Metro.
根据这五棵CART树的分类结果,我们可以针对这个人的信息建立收入层次的分布情况:

Final probability是取每棵树预测概率的均值
最后,我们得出结论,这个人的收入层次70%是一等,大约24%为二等,6%为三等,所以最终认定该人属于一等收入层次(小于$40,000)。
3.随机森林的优缺点
3.1 优点
- 行抽样和列抽样的引入让模型具有抗过拟合和抗噪声的特性
- 对数据的格式要求低:因为有列抽样从而能处理高维数据;能同时处理离散型和连续型;和决策树一样不需要对数据做标准化处理;可以将缺失值单独作为一类处理
- 不同树的生成是并行的,从而训练速度优于一般算法
- 给能出特征重要性排序
- 由于存袋外数据,从而能在不切分训练集和测试集的情况下获得真实误差的无偏估计
3.2 缺点
- 对少量数据集和低维数据集的分类不一定可以得到很好的效果
- 计算速度比单个的决策树慢
- 当我们需要推断超出范围的独立变量或非独立变量,随机森林做得并不好
参考:
https://www.huaweicloud.com/articles/5326563f52e850147f3aba272f33ff37.html
https://blog.csdn.net/yangyin007/article/details/82385967