1.端到端模型
End to End,不需要做任何的特征工程手段,就可以学到比较好的模型,让模型自动学出这些特征
非端到端模型
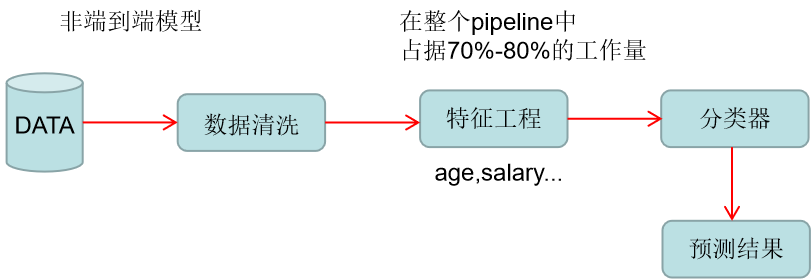
端到端模型
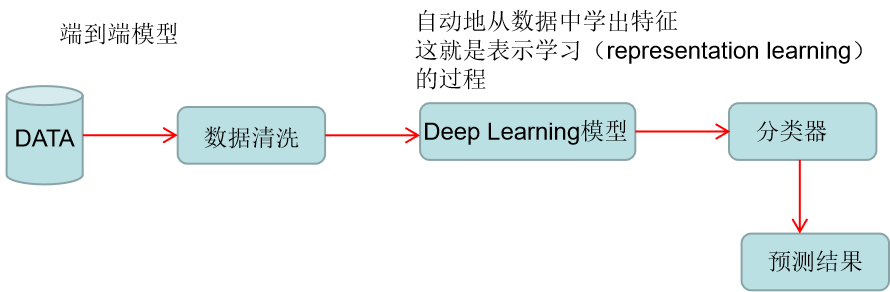
可以看到端到端模型的好处,也是很多大部分深度学习模型的初衷,不需要通过任何特征工程的方式去学习一些特征,设计一些特征,而是通过深度学习模型的方式自动的从里面学出一些有意义的表示方法,再把放到分类器中,就可以做出预测了。
2.Multimodel Learning
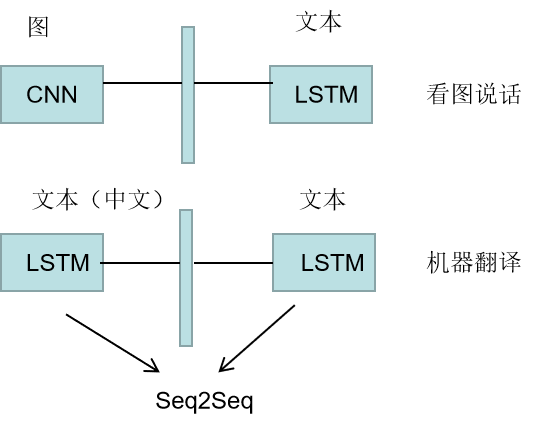
3.Seq2Seq模型
3.1 原理
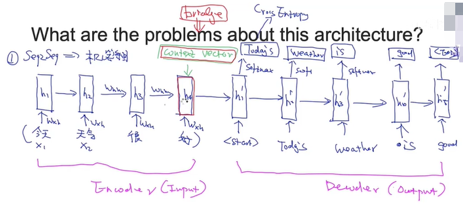
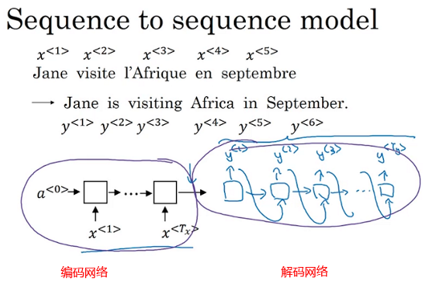
h1代表今天这个单词的含义(semantic meaning)
h2代表今天 天气这两个单词含义,即这两个单词的含义包含在h2向量里面
h3代表今天 天气 很三个单词的含义
h4代表今天 天气 很 好这句话的含义,即这句话的意思包含着了h4这个向量里面了,h4我们一般把它表示成context vector(最核心的)
因此context vector其实是代表这句话的含义也代表着英文的含义,是一个桥梁的作用
这就是RNN应用在文本领域时候,每个时间节点上隐含层的表达方式
接下来,再根据context vector生成英文的单词,完成机器翻译的过程
h1'经过softmax,在分布里面选取概率最大的一个,如Today's
Today's再作为下一个输入,得到h2'再经过softmax得到weather
3.2 缺点
(1)Bottle neck problem
上面那张图所有模型的关键在于context vector,如果这个上下文向量效果不好,那么整个的模型效果也会不好
(2)Gradient problem
4.Attention Mechanism
4.1 早期机器翻译模型RNN-AutoEncoder的原理
早期自然语言处理:RNN autoencoder
Sutskever, Ilya, Oriol Vinyals, and Quoc V. Le. “Sequence to sequence learning with neural networks.” arXiv preprint arXiv:1409.3215 (2014). (google citation 14048)
这里以机器翻译为例子,介绍RNN autoencoder的原理
输入句子经过分词,编码成数字,然后embedding成神经网络可以接受的向量。
在训练过程中,可以使用teacher forcing,即decoder的输入使用真实值,迫使在训练过程中,误差不会累加
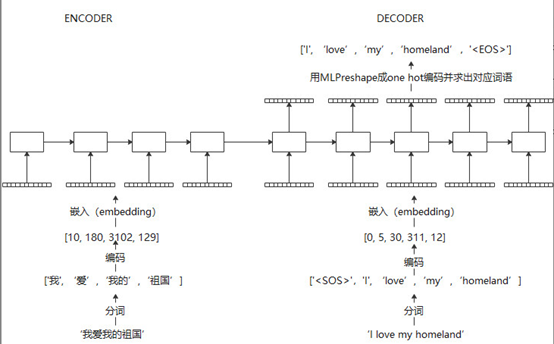
在在线翻译过程中,encoder部分流程相同,decoder部分,目标句子是一个单词一个单词生成的
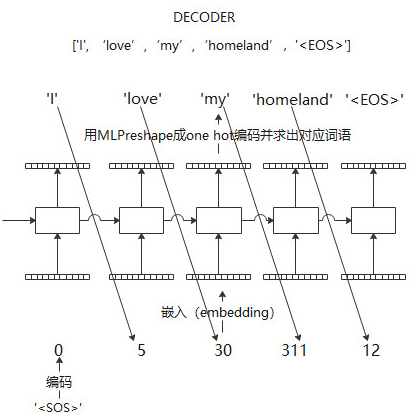
早期RNN auto encoder结构虽然相比于传统模型取得了巨大成功,但encoder,decoder之间的信息传播仅仅时由单一的一个隐层链接完成的,这样势必会造成信息丢失,因此,Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” arXiv preprint arXiv:1409.0473 (2014).(citation 16788)提出在输入和输出之间增加额外的attention链接,增加信息传递的鲁棒性以及体现输出句子中不同单词受输入句子单词影响的差异性。

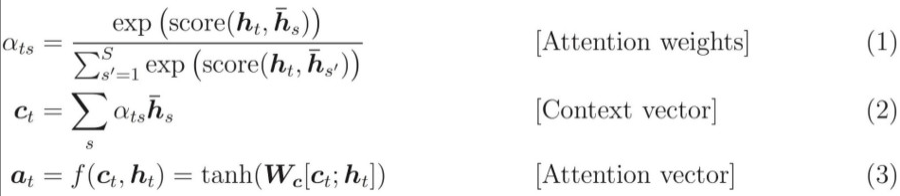
Seq2Seq模型通过编码和解码的RNN模型,我们能够实现较为准确的机器翻译结果。对于短句子来说,其性能十分良好,但是如果是很长的句子,翻译的结果就会变差
对于我们人类进行人工翻译的时候,我们所做的也不是像编码解码RNN模型一样记忆整个输入句子,再进行相应的输出,因为记忆整个长句子是很难的,所以我们是一部分一部分地进行翻译。
我们要得到Today's这个单词,我们希望的注意力是放在“今天”这个单词上
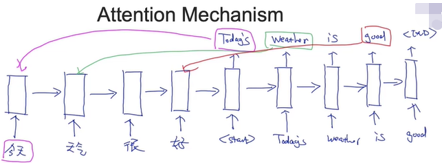
(1)注意力机制的整个流程(the whole working flow)
生成输出之前先计算attention score
为了生成下一个单词,我的注意力是放在h1呢,h2呢还是h3,h4,解决办法,就是在生成第一个单词的时候,把h1,h2,h3,h4每一个权重计算出来
值越高,就把注意力放在那个位置

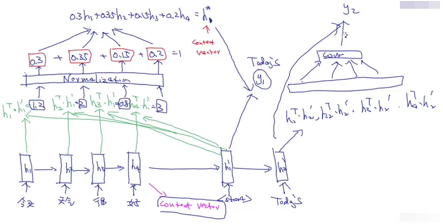
(2)我们每次做预测的时候,分为两步:
首先计算出接下来我要做这个预测,我的注意力需要放在哪。
接下来就要去预测,生成这个单词
(3)使用LSTM+Attention会出现两个问题:
- 因为是sequence model,所以不能并行化。因此一旦我们的时序很长,如T=1000,即便用GPU的资源,也不能并行化,只能一个时间一个时间去计算,才能计算完,是一种串行的计算方式
- 核心的问题:Long-term dependency,原因在于我们使用了LSTM,那LSTM是存在梯度消失/梯度下降的问题的

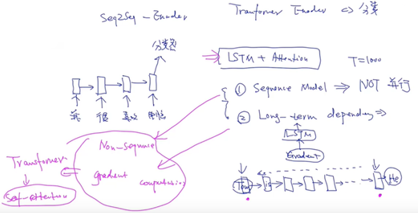
解决以上问题:
- 不使用sequence model,即Non-sequence model
- 避免有 gradient computation,不要有很长的链式求导的过程
但是在拥有这两个特性的基础上,希望这个模型有LSTM的这样的性质,这就引出的Transformer,这个模型既不是时序类的模型,也不需要沿着时间的维度来计算梯度,但是拥有像LSTM模型这样可以捕获时序数据的特点,核心就是在于self-attention,就是自己对自己的attention,而不是像之前那样等到生成之后,才依赖于前面生成的attention
5.在NLP中使用注意力机制
5.1 Encoder-Decoder框架
要了解深度学习中的注意力模型,就必须要知道Encoder-Decoder框架,因为目前大多数注意力机制都附着在Encoder-Decoder框架下。当然,我们也应该明白注意力机制是一种思想,本身并不依赖于任何框架。
Encoder-Decoder是深度学习中非常常见的一个模型框架。例如:在Image Caption的应用中Encoder-Decoder就是CNN-RNN的编码-解码框架;在神经网络机器翻译模型中Encoder-Decoder往往就是LSTM-LSTM的编码-解码框架。特别需要注意的是,在机器翻译中是文本到文本的转换,比如将法语翻译成英语,这样的Encoder-Decoder模型也被叫做Sequence to Sequence learning。
所谓编码,就是将输入序列编码成一个固定长度的向量;解码,就是将之前生成的固定向量再解码成输出序列。
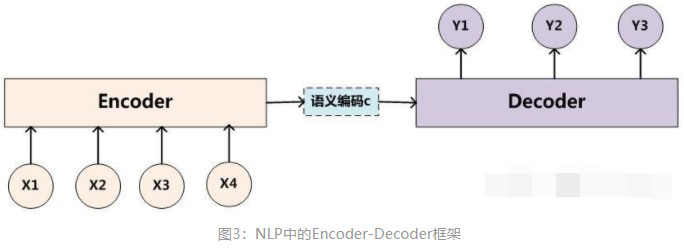
在图3中为了方便阐述,我们选取Encoder和Decoder都是RNN。在RNN中,当前时刻隐藏层状态 是由上一时刻的隐藏层状态
和当前时刻的输入
决定的,如公式(1)所示。
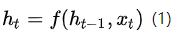
在编码阶段,获得了各个时刻的隐藏层状态后,我们把这些隐藏层的状态进行汇总,生成最后的语义编码向量C,如公式(2)所示,其中q表示某种非线性神经网络,在这里表示多层RNN。
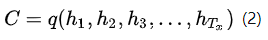
一种简单的方法是将最后的隐藏层状态作为语义编码向量C,即公式(3)所示。
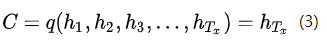
在解码阶段,我们要根据给定的语义向量C和之前已经生成的输出序列 来预测下一个输出的单词
,即公式(4)所示。
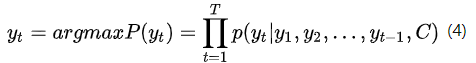
我们的目标就是求yt最大,上面的yt就是目标函数
公式(4)可以简写成公式(5)
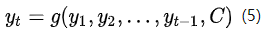
而在RNN中,公式(5)可以表示为公式(6)
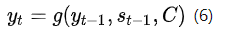
公式(6)中, 表示Decoder中RNN神经元的隐藏层状态,
表示前一时刻的输出,C代表的是语义向量。而g则是一个非线性的多层神经网络,可以输出
的概率。g一般情况下是多层RNN后接softmax层。
Encoder-Decoder框架虽然非常经典,但是局限性也非常大。最大的局限性就在于编码器和解码器之间的唯一联系就是一个固定长度的语义向量C。
也就是说,编码器要将整个序列的信息压缩进一个固定长度的向量中。这样做存在两个弊端,
一是语义向量C可能无法完全表示整个序列的信息,
二是先输入到网络的内容携带的信息会被后输入的信息覆盖掉,输入序列越长,这个现象就越严重。
这两个弊端使得在解码的时候解码器一开始就没有获得输入序列足够多的信息, 那么解码的准确度自然也就不高了。
怎么训练的
训练样本:翻译的句子对(X1, Y1),(X2, Y2),(X3, Y3)
目标函数:
X:我是中国人
Y:I am Chinese
p(Y|X) = p(y1,y2,y3...yT|x1,x2,x3...xT)
p(y1,y2|X)=p(y1|X) x p(y2|X,y1)
p(I am Chinese | 我是中国人) = p(I | 我是中国人) .p(I | 我是中国人,am)...
5.2 Attention机制
为了解决Encoder-Decoder框架中的两个弊端,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》[8]中提出使用Attention机制。在深度学习领域,该论文是非常有影响力且具有开创性的,文中提出的Attention机制不仅应用于机器翻译中,还被推广到了其他应用领域。因此,该论文提出的Attention机制是非常值得深入学习。
参考: