1.ResNet的借鉴点
层间残差跳连,引入前方信息,减少梯度消失,使神经网络层数变身成为可能。
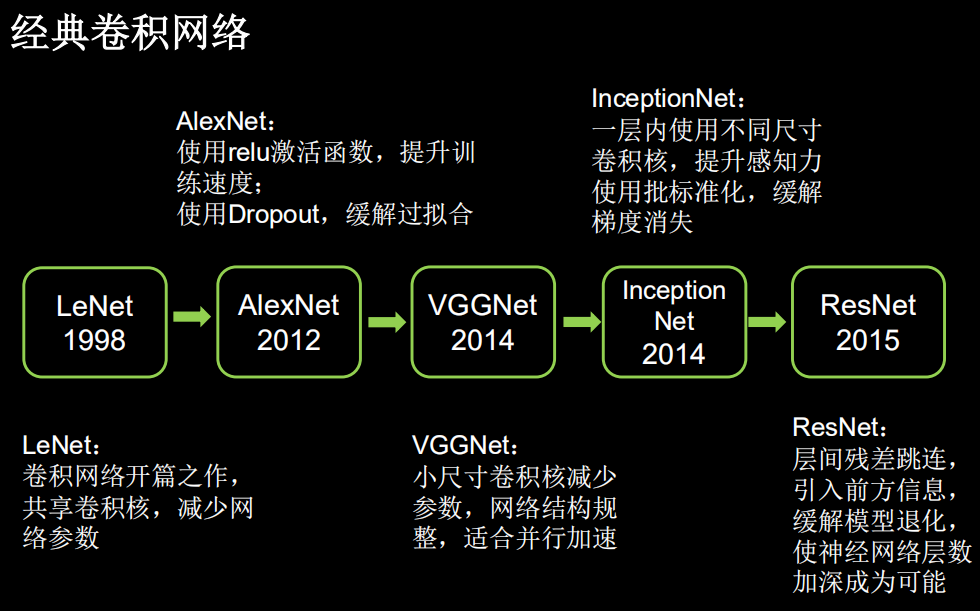
2.介绍
ResNet 即深度残差网络,由何恺明及其团队提出,是深度学习领域又一具有开创性的工作,通过对残差结构的运用, ResNet 使得训练数百层的网络成为了可能,从而具有非常强大的表征能力,其网络结构如图 5-31 所示。
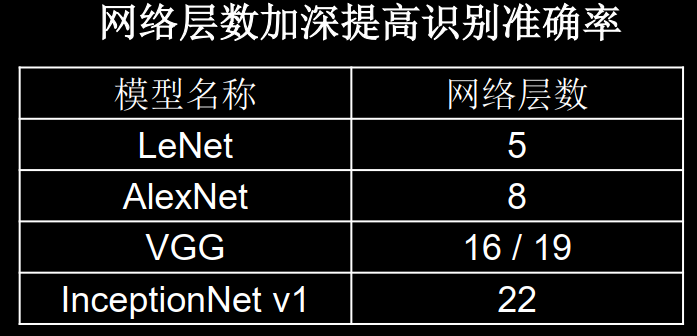
ResNet 引入残差结构最主要的目的是解决网络层数不断加深时导致的梯度消失问题,从之前介绍的 4 种 CNN 经典网络结构我们也可以看出,网络层数的发展趋势是不断加深的。这是由于深度网络本身集成了低层/中层/高层特征和分类器,以多层首尾相连的方式存在,所以可以通过增加堆叠的层数(深度)来丰富特征的层次,以取得更好的效果。
但如果只是简单地堆叠更多层数,就会导致梯度消失(爆炸)问题,它从根源上导致了函数无法收敛。然而,通过标准初始化( normalized initialization)以及中间标准化层(intermediate normalization layer),已经可以较好地解决这个问题了,这使得深度为数十层的网络在反向传播过程中,可以通过随机梯度下降(SGD)的方式开始收敛。
但是,当深度更深的网络也可以开始收敛时,网络退化的问题就显露了出来:随着网络深度的增加,准确率先是达到瓶颈(这是很常见的),然后便开始迅速下降。需要注意的是,这种退化并不是由过拟合引起的。对于一个深度比较合适的网络来说,继续增加层数反而会
导致训练错误率的提升,图 5-33 就是一个例子。
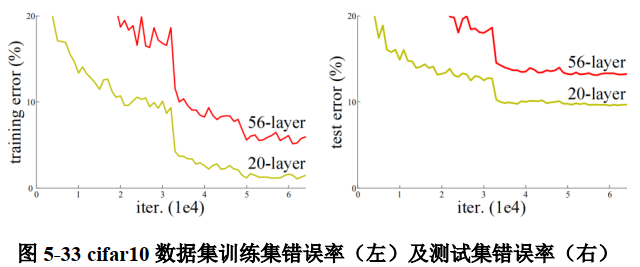
56层的卷积网络错误率要高于20层卷积网络错误率,单纯堆叠网络层数,会使神经网络模型退化,以至于后边的特征丢失前边特征的原本模样。
3.ResNet核心
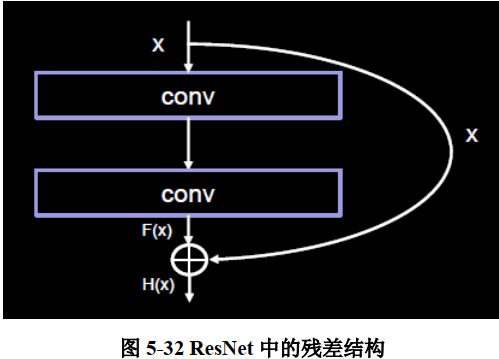
ResNet 的核心是残差结构,如图 5-32 所示。在残差结构中, ResNet 不再让下一层直接拟合我们想得到的底层映射,而是令其对一种残差映射进行拟合。若期望得到的底层映射为H(x), 我们令堆叠的非线性层拟合另一个映射 F(x) := H(x) – x, 则原有映射变为 F(x) + x。对这种新的残差映射进行优化时,要比优化原有的非相关映射更为容易。不妨考虑极限情况,如果一个恒等映射是最优的,那么将残差向零逼近显然会比利用大量非线性层直接进行拟合更容易。
值得一提的是,这里的相加与 InceptionNet 中的相加是有本质区别的, Inception 中的相加是沿深度方向叠加, 像“千层蛋糕”一样, 对层数进行叠加; ResNet 中的相加则是特征图对应元素的数值相加,类似于 python 语法中基本的矩阵相加。

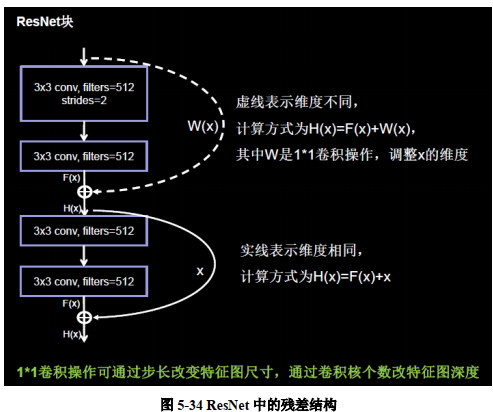
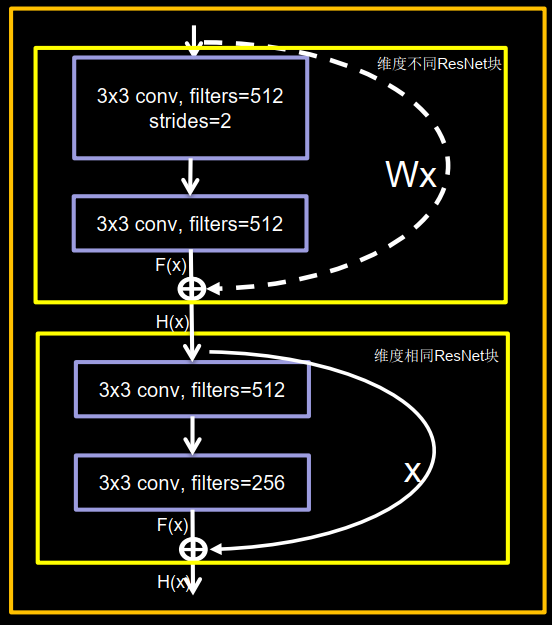
ResNet 解决的正是这个问题,其核心思路为:对一个准确率达到饱和的浅层网络,在它后面加几个恒等映射层(即 y = x,输出等于输入),增加网络深度的同时不增加误差。这使得神经网络的层数可以超越之前的约束,提高准确率。图 5-34 展示了 ResNet 中残差结构的具体用法。
注意:
ResNet块有两种形式:一种是在堆叠卷积前后维度相同,另一种是在堆叠卷积前后维度不同
一种情况用图中实现表示,两层堆叠卷积没有改变特征图维度,也就是他们特征图的个数,高、宽、深度都相同,可以直接将F(x)与相加
另一种情况用图中虚线表示,两层堆叠卷积改变了特征图的维度,需要借助1x1的卷积来调整x(即输入特征inputs)的维度,使w(x)与F(x)的维度一致
细节:

代码:
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
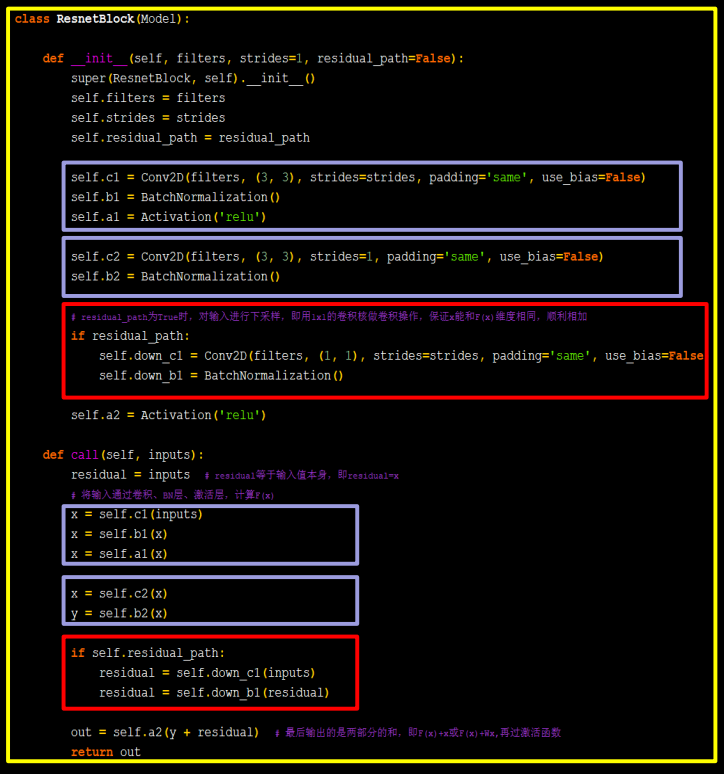
class ResnetBlock(Model):
def __init__(self, filters, strides=1, residual_path=False):
super(ResnetBlock, self).__init__()
self.filters = filters
self.strides = strides
self.residual_path = residual_path
self.c1 = Conv2D(filters, (3, 3), strides=strides, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.c2 = Conv2D(filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b2 = BatchNormalization()
# residual_path为True时,对输入进行下采样,即用1x1的卷积核做卷积操作,保证x能和F(x)维度相同,顺利相加
if residual_path:
self.down_c1 = Conv2D(filters, (1, 1), strides=strides, padding='same', use_bias=False)
self.down_b1 = BatchNormalization()
self.a2 = Activation('relu')
def call(self, inputs):
residual = inputs # residual等于输入值本身,即residual=x
# 将输入通过卷积、BN层、激活层,计算F(x)
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.c2(x)
y = self.b2(x)
if self.residual_path:
residual = self.down_c1(inputs)
residual = self.down_b1(residual)
out = self.a2(y + residual) # 最后输出的是两部分的和,即F(x)+x或F(x)+Wx,再过激活函数
return out
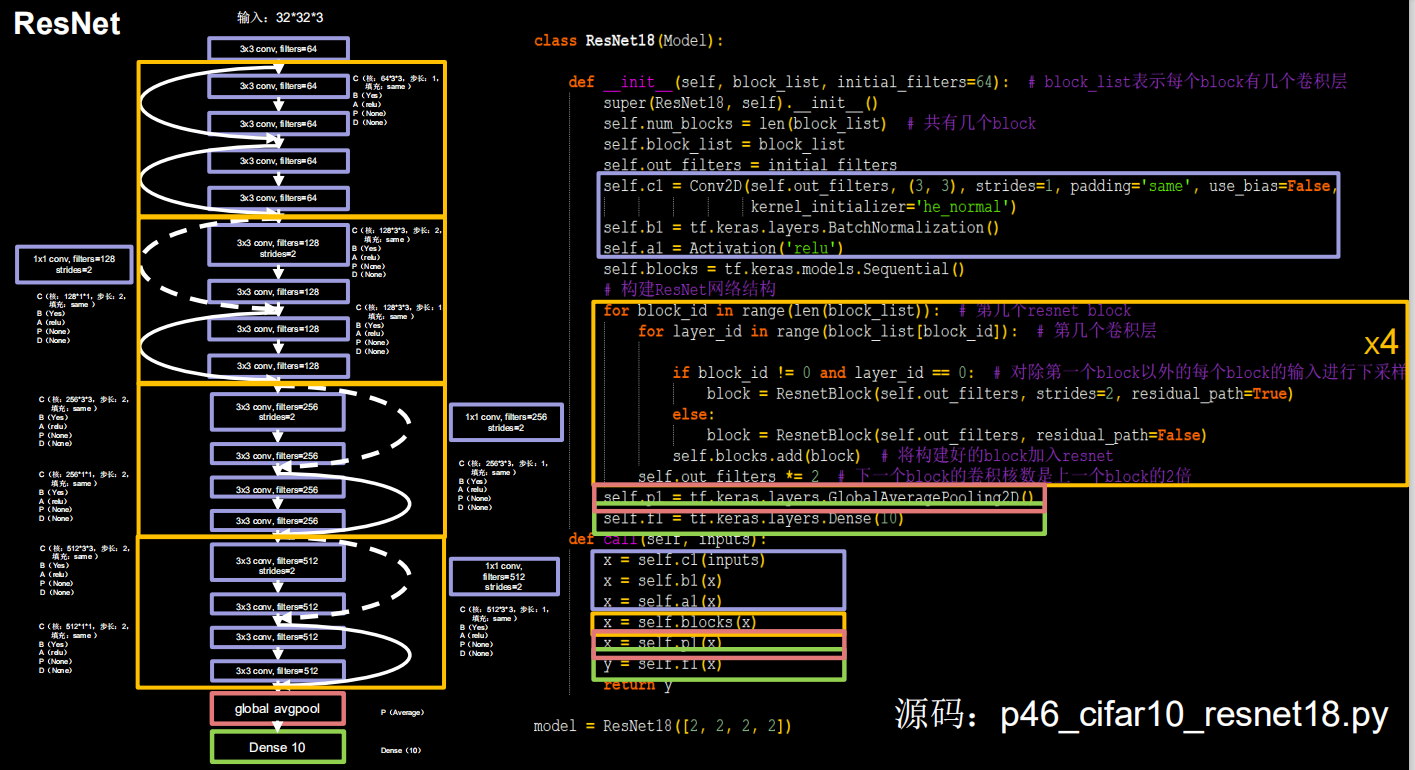
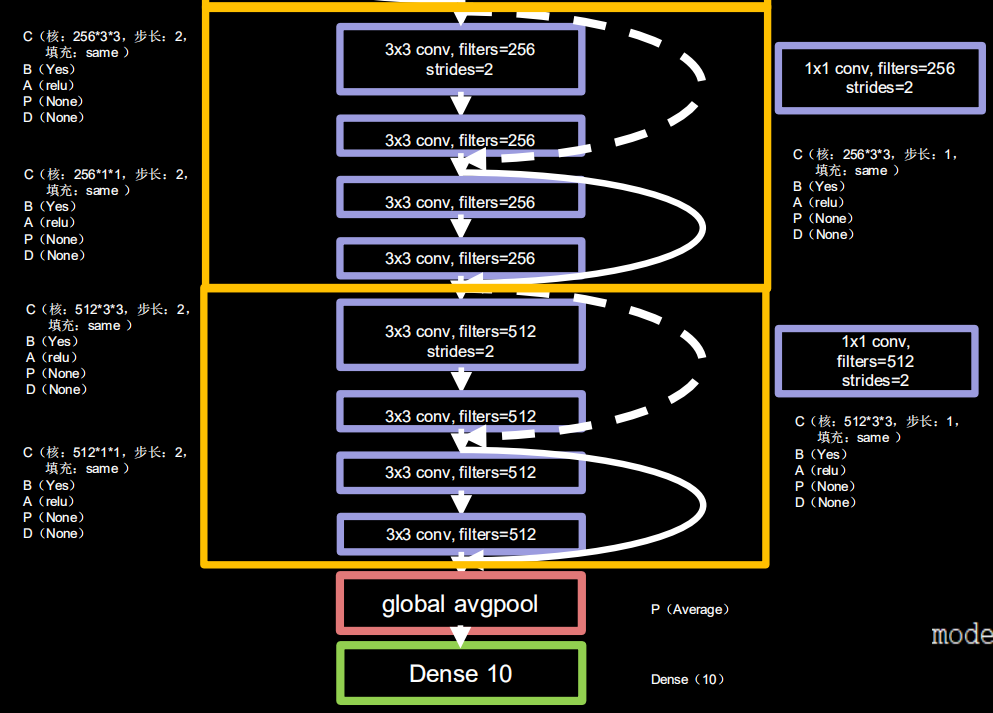
class ResNet18(Model):
def __init__(self, block_list, initial_filters=64): # block_list表示每个block有几个卷积层
super(ResNet18, self).__init__()
self.num_blocks = len(block_list) # 共有几个block
self.block_list = block_list
self.out_filters = initial_filters
self.c1 = Conv2D(self.out_filters, (3, 3), strides=1, padding='same', use_bias=False)
self.b1 = BatchNormalization()
self.a1 = Activation('relu')
self.blocks = tf.keras.models.Sequential()
# 构建ResNet网络结构
for block_id in range(len(block_list)): # 第几个resnet block
for layer_id in range(block_list[block_id]): # 第几个卷积层
if block_id != 0 and layer_id == 0: # 对除第一个block以外的每个block的输入进行下采样
block = ResnetBlock(self.out_filters, strides=2, residual_path=True)
else:
block = ResnetBlock(self.out_filters, residual_path=False)
self.blocks.add(block) # 将构建好的block加入resnet
self.out_filters *= 2 # 下一个block的卷积核数是上一个block的2倍
self.p1 = tf.keras.layers.GlobalAveragePooling2D()
self.f1 = tf.keras.layers.Dense(10, activation='softmax', kernel_regularizer=tf.keras.regularizers.l2())
def call(self, inputs):
x = self.c1(inputs)
x = self.b1(x)
x = self.a1(x)
x = self.blocks(x)
x = self.p1(x)
y = self.f1(x)
return y
model = ResNet18([2, 2, 2, 2])
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/ResNet18.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
# print(model.trainable_variables)
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '
')
file.write(str(v.shape) + '
')
file.write(str(v.numpy()) + '
')
file.close()
############################################### show ###############################################
# 显示训练集和验证集的acc和loss曲线
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()