前几天打算一直想找一个时间把字符串匹配算认真弄一下,今天不想看其他的东西,那就想着把字符串匹配算法好好整理梳理一下。
字符串匹配算法有几种相对比较出名的,分别是BF(暴力破解),RK()、BM()、KMP()。下文中 主串为被匹配的串, 模式串为匹配的串。 例如 s = “aabbcc”(主串),a = “aa" (模式串)
BF算法
首先我大概把BF说一下,就是BF(Brute Force)顾名思义就是暴力破解算法,意思就是我们在主串中,检查的起始位置分别是 0、1、2…n-m 且长度为 m 的 n-m+1 个子串(n为主串的长度, m为模式串的长度),看有没有跟模式串匹配的。这种算法的时间复杂度为O(n*m), 空间复杂度为O(1)。
虽然BF算法的时间复杂度高,但是如果在主串和模式串的长度不长时,这种算法的效率也不低,而且时间复杂度O(n*m)是最坏的时间复杂度,大部分情况下都不会出现这种情况。另外这种方法也是最简单和易于理解的。
图示步骤

RK算法
主串的长度为n, 模式串的长度为m,在BF算法中相当于我们将主串分成n-m+1个字串,然后使用模式串依次对这n-m-1个字串进行匹配。而在RK算法的思想就是我们根据模式串的长度求出主串中n-m+1个字串,然后分别对这n-m+1个字串进行hash求值,最后使用模式串的hash值进行比对,如果相等,为了防止hash冲突我们在对两个hash值对应的串进行对比是否相等。从而得出结果。这种算法时间复杂度为O(n),空间复杂度为O(1)。
图示

BM算法
前面两种匹配算法中当遇到不匹配的字符时,BF 算法和 RK 算法的做法都是将模式串往后移动一位,然后从模式串的第一个字符开始重新匹配。一直到最后完成匹配为止。这两种都是从头部开始匹配,但是对于BM算法中他主要考虑和改进了前两种算法的不足,他主要是从模式串的尾部到头部依次对主串进行匹配的。而在匹配的过程中每一次向后移动几位是由两个规则决定出来的。即坏字符规则和好后缀规则。
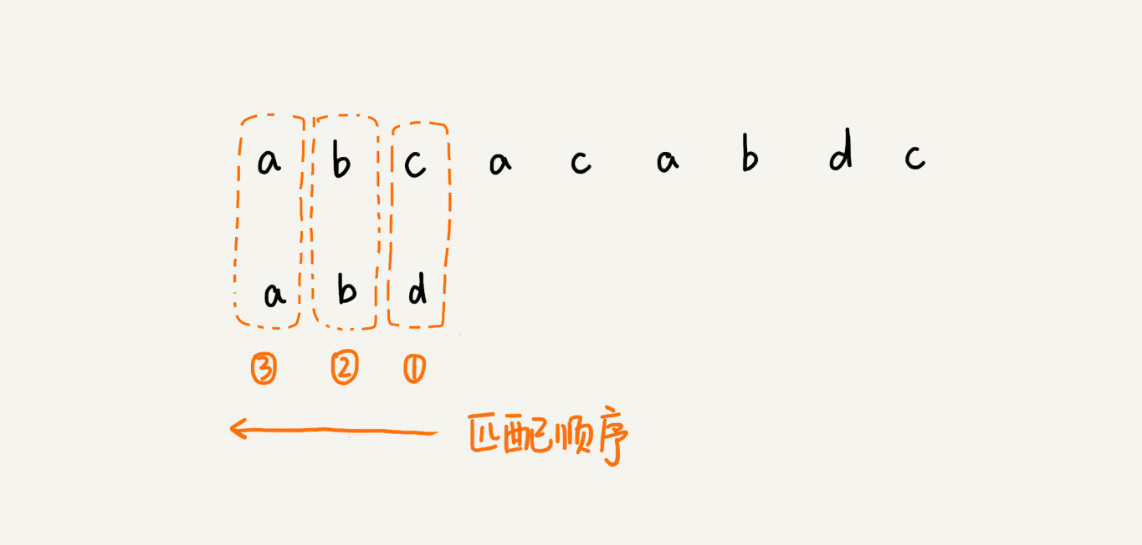
坏字符规则
我们从模式串的末尾往前倒着匹配,当我们发现某个字符没法匹配的时候。我们把这个没有匹配的字符叫作坏字符。
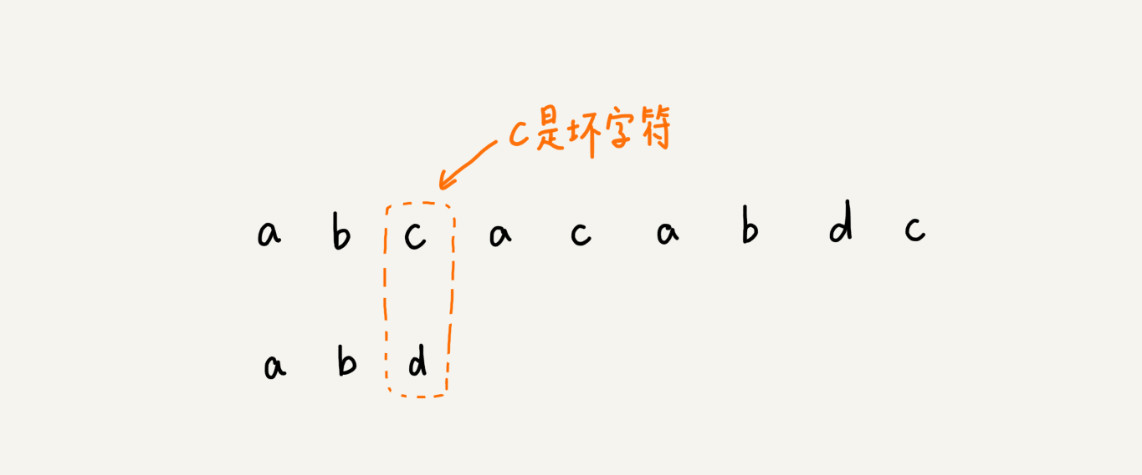
这里的情况分成两种:
(1)如果发现模式串中并不存在这个字符,我们可以将模式串直接往后滑动到坏字符的后面一位,再从模式串的末尾字符开始比较。

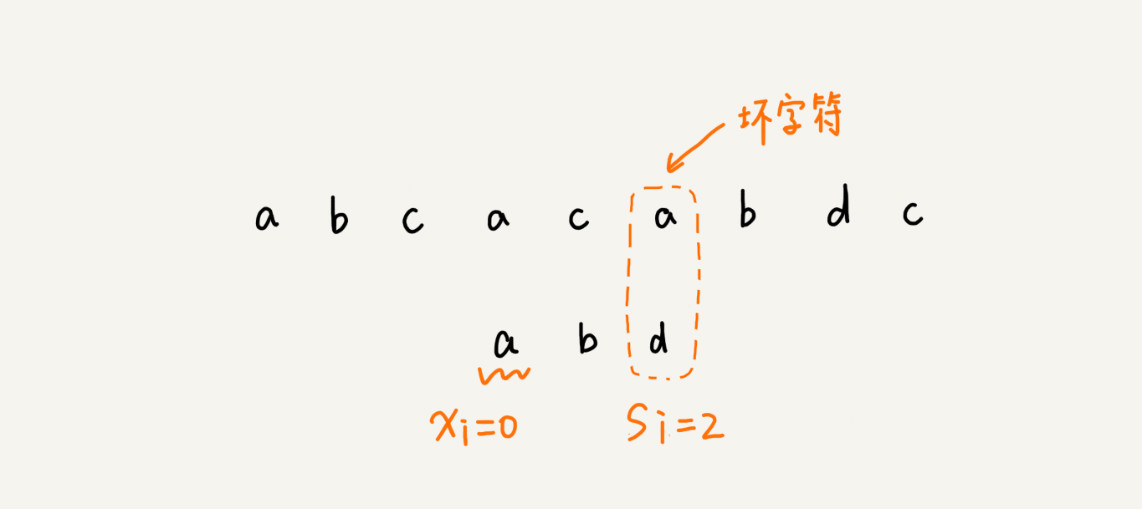
(2)如果发现模式串中存在这个字符,这里我们假定这个坏字符对应于模式串中的下标是x, 而坏字符在模式串出现离下标x前最近的位置是y(防止坏字符在模式串中多次出现,导致滑动过头的情况),这时应该移动x-y位,然后重新开始从尾进行匹配。
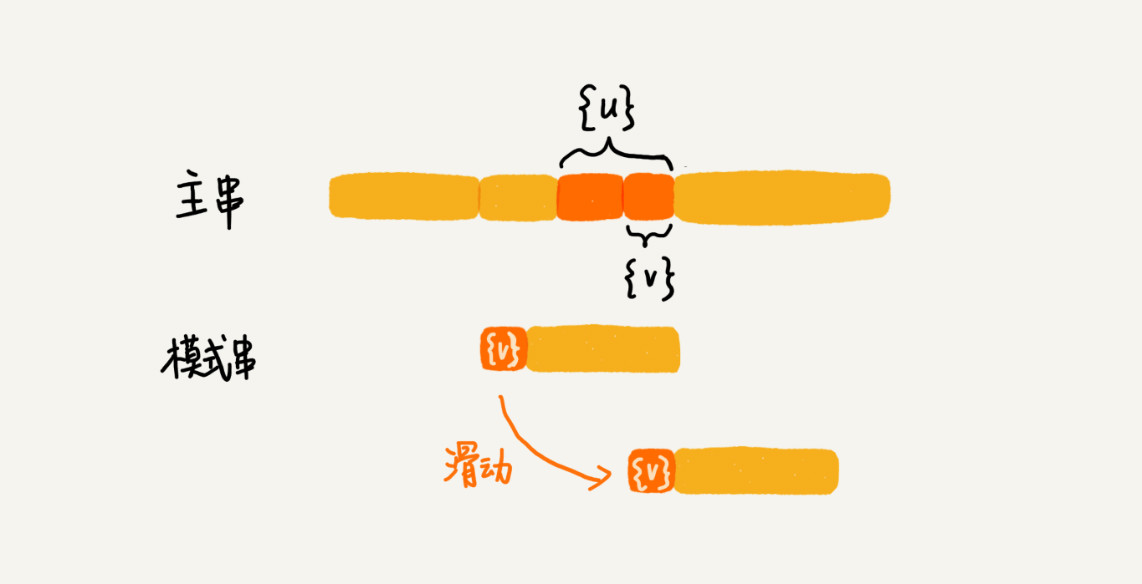
好后缀规则
好后缀规则主要是为了防止x-y的值为负数,例如主串是' aaaaaaaaaaaaaaaa',模式串是' baaa'。这里不但不会向后滑动模式串,还有可能倒退。好后缀意思就是模式串后面已经匹配成功的字符串。

我们把已经匹配的z字符串叫作好后缀,记作{u}。我们拿它在模式串中查找,这里也存在两种情况
(1)如果找到了另一个跟{u}相匹配的子串{u*},那我们就将模式串滑动到子串{u*}与主串中{u}对齐的位置。

(2)如果好后缀在模式串中不存在可匹配的子串{u*},我们就查找{u}中的子串是否存在跟模式串的前缀子串匹配的结果。
坏字符和好后缀进行比较来得出每次移动的位数
我们可以分别计算好后缀和坏字符往后滑动的位数,然后取两个数中最大的,作为模式串往后滑动的位数。这种处理方法还可以避免我们前面提到的,根据坏字符规则,计算得到的往后滑动的位数,有可能是负数的情况。
代码实现
因此坏字符和好后缀两者是独立的,我们可以先实现坏字符部分,当遇到坏字符时,我们需要在得到两个值一个就是主串中坏字符对应模式串的下标x, 然后得到主串中对应的坏字符在模式串中最靠近x的位置下标(如果每次都使用遍历进行查找 这样效率低,我们可以采用空间换时间的办法,设置一个数组来记录出现的位置,如果全是英文字母的话,数组大小为256,小标为asc码,值为模式串的下标)
例如

初始化坏字符的辅助数组的代码
1 NUMS_SIZE = 256
2
3 def generateBC(str_b, bc):
6 for i in range(len(str_b)): # 将字符存储到对应下标的位置
7 bc[ord(str_b[i])] = i
第二个就是后缀子串的问题, 这里我们设置两个辅助数组,一个是suffix数组,下标表示后缀字符的长度,值表示在前缀中出现的位置。另一个是prefix数组,下标表示后缀字符的长度,值表示是否是前缀字串。
例如:

初始化好后缀的辅助数组代码(建议自己画图理解一下,不然代码不好理解)
1 def generateGS(str_b, suffix, prefix): # 针对模式串初始化相应的suffix数组和prefix数组。
2 str_b_length = len(str_b)
7 for i in range(str_b_length-1):
8 j, k = i, 0
9 while i >=0 and str_b[j] == str_b[str_b_length-1-k]:
10 j -= 1
11 k += 1
12 suffix[k] = j+1
13 if j < 0:
14 prefix[k] = True
在写完上面上个规则之后,我们来进行匹配的主体函数
2 def moveByGS(j, m, suffix, prefix): # 找到好后缀对应的移动位数
3 k = m-1-j
4 if suffix[k] != -1:
5 return j - suffix[k]+1
6 for i in range(j+2, m):
7 if prefix[m-i]:
8 return i
9 return m
10
11
12 def BM(str_a, str_b): # BM算法
13 str_a_len, str_b_len = len(str_a), len(str_b)
14 bc = [-1] * NUMS_SIZE
15 generateBC(str_b, bc)
16 suffix, prefix = [-1] * str_b_len, [False] * str_b_len
17 generateGS(str_b, suffix, prefix)
18 i = 0
19 while i <= (str_a - str_b_len): # 从第一个位置开始查找
20 j = str_b_len-1
21 while j >=0:
22 if str_a[i+j] != str_b[j]:
23 break
24 j -= 1
25 if j < 0:
26 return i
27 x, y = j - bc[ord(str_a[i+j])], 0 # x表示坏字符移动的位数
28 if j < str_b-1:
29 y = moveByGS(j, str_b_len, suffix, prefix) # 得到好后缀的移动位数
30 i = i + max(x, y) # 取最大的进行移动
31
32 return -1
KMP算法