前面提到的几种排序最优的时间复杂度为O(nlog n),但在排序算法中还不是最优的,有几种算法的时间复杂度为O(n),因为时间复杂度是线性的,所以又称线性排序。他们有桶排序、计数排序、基数排序,之所以能够达到线性的时间复杂度,是因为他们都不涉及元素之间的比较操作,这就意味着他们的使用条件都比较苛刻。
桶排序
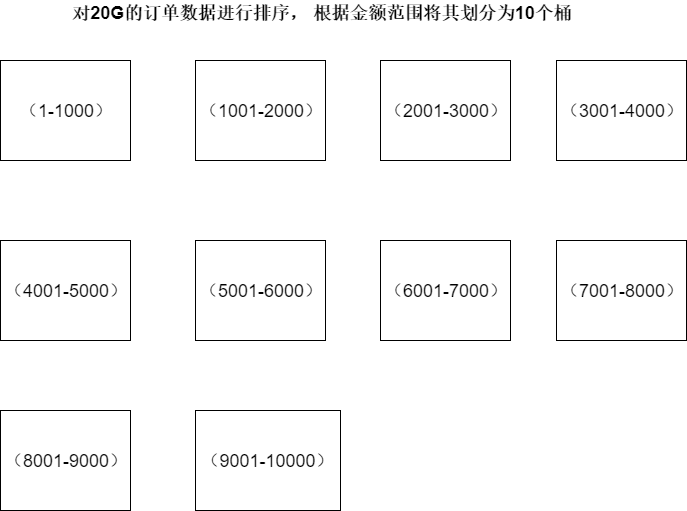
桶排序主要原理就是将要排序的数据分别分到几个桶里面,然后每个桶里面的数据再单独排序。排序完毕之后再依此取出,组成的序列就是有序数组了。比如我们有20G的订单数据,但是内存只有500M,希望按照金额进行排序,利用桶排序的话,我们可以先从头到尾扫描一遍文件,知道订单金额的范围,假设扫描一遍之后,最小的是1元,最大的是1万元,然后我们可以将金额范围划分成10个桶,(1,1000),(1001, 2000),....等,然后单独堆每个桶中的顺序进行排序,最后新建一个文件将数据依此存入,最后得到一个有序的文件。但是这里会存在一个问题,那就是十个桶之间的数据假如分布不均匀怎么办?我们可以选择继续划分的办法,尽量将划分之后的区域数据能够一次性的存于内存。
复杂度:假设待排序的数据为 n 个,我们把它们均匀地划分到 m 个桶内,每个桶里就有 k=n/m 个元素。每个桶内部使用快速排序,时间复杂度为 O(k * logk)。m 个桶排序的时间复杂度就是 O(m * k * logk),因为 k=n/m,所以整个桶排序的时间复杂度就是 O(n*log(n/m))。当桶的个数 m 接近数据个数 n 时,log(n/m) 就是一个非常小的常量,这个时候桶排序的时间复杂度接近 O(n)。
计数排序
计数排序我们可以看成桶排序的特殊情况,桶排序中每一个桶都是一个范围,而在计数排序中,待排序的数据范围不是很大假如为K,我们可以将其分成K个桶,例如你对员工年龄排序,假设员工年龄最大就为100岁,因此我们可以将其分成100个桶,然后将相应年龄装入相应桶,最后结果进行排序。
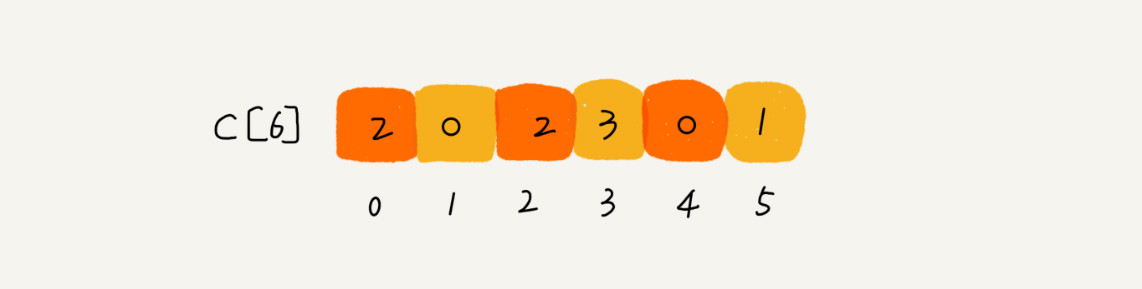
举个例子:假设只有 8 个考生,分数在 0 到 5 分之间。这 8 个考生的成绩我们放在一个数组 A[8] 中,它们分别是:A[8] = [2,5,3,0,2,3,0,3],考生的成绩从 0 到 5 分,我们使用大小为 6 的数组 C[6] 表示桶,其中下标对应分数。不过,C[6] 内存储的并不是考生,而是对应的考生个数。我们只需要遍历一遍考生分数,就可以得到 C[6] 的值 C6 = [2,0,2,3,0,1]
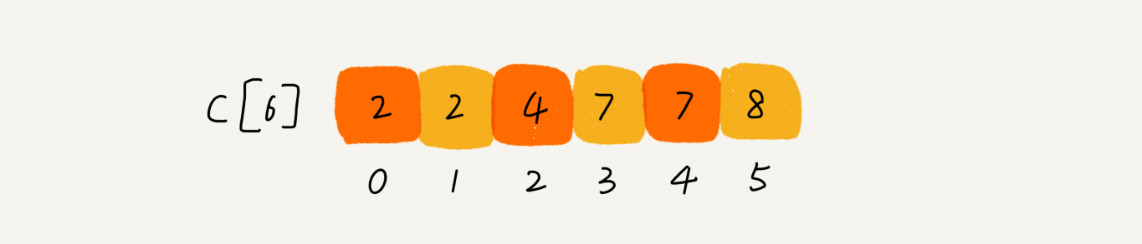
然后对C数组进行顺序求和,得到
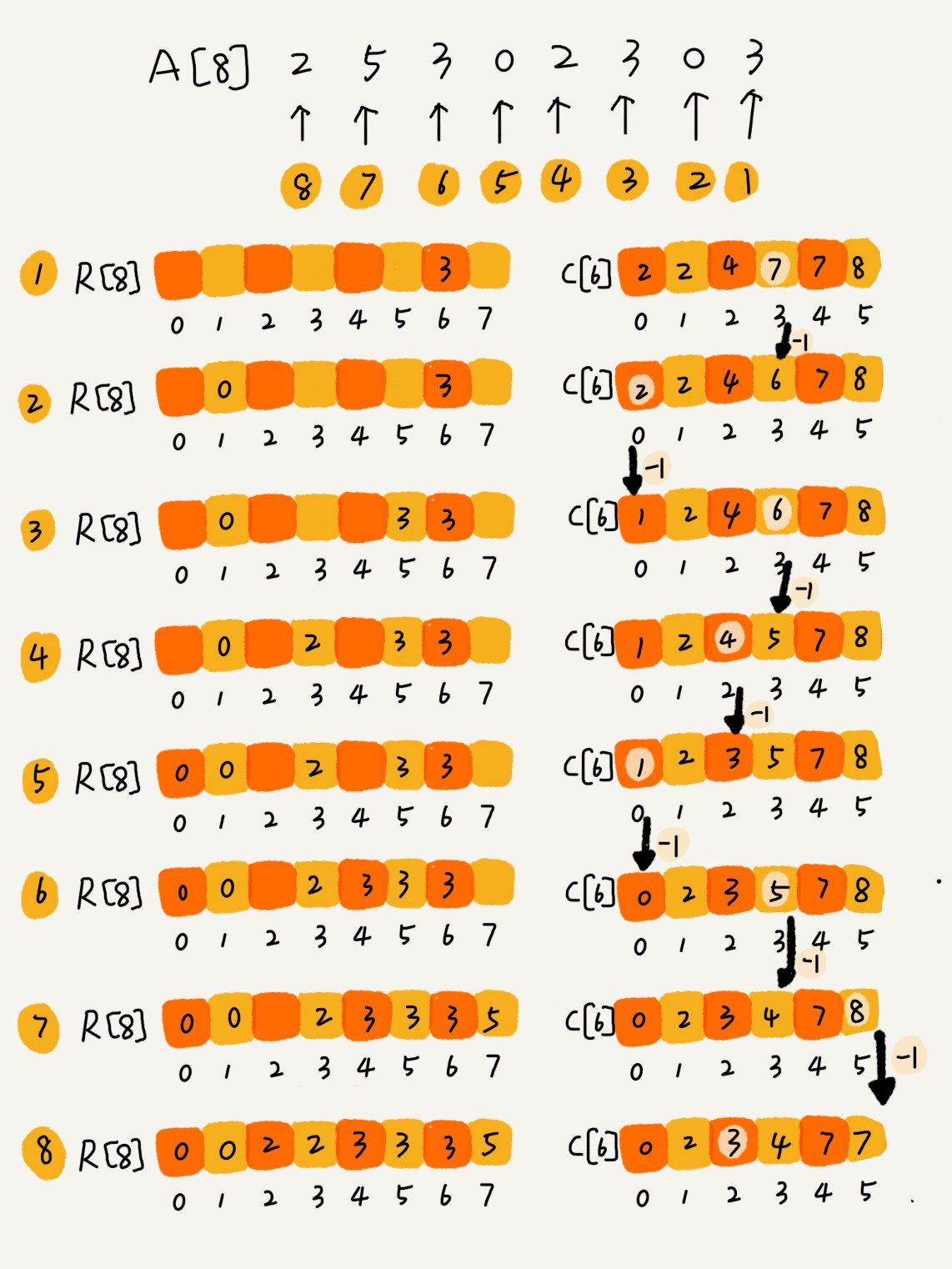
我们从后到前依次扫描数组 A。倒数第一个元素为 3 ,我们可以从数组 C 中取出下标为 3 的值 7,也就是说,分数小于等于 3 的考生有 7 个,这意味着分数 3 是数组 R(新建的一个和人数一样长的数组) 中的第 7 个元素(数组 R 中下标为 6 的位置)。当 3 放入到数组 R 中后,相应的 C[3] 要减 1,变成 6。步骤图如下:
基数排序
基数排序就是根据某一位来判断整个数的大小关系,比如你需要对手机号进行排序,我们可以直接从倒数第一位进行排序,这里需要借助稳定排序(必须),就是两个相同的数字,排序之后他们的位置不会改变。然后经过十一次之后就排好序了。(一般借助桶来实现,设置10个桶,分别是0,1,...,9。然后将排序的数字相应位置的数字依此装进对应的桶中, 然后再取出就组成一个排序数列。后面执行前面的相同的操作,知道最后一位完成,就意味着排序完成)
基数排序对要排序的数据是有要求的,需要可以分割出独立的“位”来比较,而且位之间有递进的关系,如果 a 数据的高位比 b 数据大,那剩下的低位就不用比较了。除此之外,每一位的数据范围不能太大,要可以用线性排序算法来排序,否则,基数排序的时间复杂度就无法做到 O(n) 了。