文件的读写
| <file>.read(size=-1) | 从文件中读入一整个文件内容,如果给出参数,读入前size长度的字符串或字节流 |
| <file>.readline(size=-1) | 从文件中读入一行内容,如果给出参数,读入该行前size长度的字符串或字节流 |
| <file>.readlines(hint=-1) | 从文件中读入所有行,以每行为元素形成一个列表,如果给出参数,读入hint行 |
import pandas as pd
grade = pd.read_excel(r"C:UsersAdministratorDesktop57.xlsx", sheet_name="Sheet1") # filename为excel表格的文件路径
for i in range(len(grade.index)):
for j in range(1, len(grade.columns)):
if grade.iloc[i, j] == '优秀':
grade.iat[i, j] = 90
elif grade.iloc[i, j] == '良好':
grade.iat[i, j] = 80
elif grade.iloc[i, j] == '合格':
grade.iat[i, j] = 60
else:
grade.iat[i, j] = 0
grade.to_csv("55.csv") # csv文件的保存路径
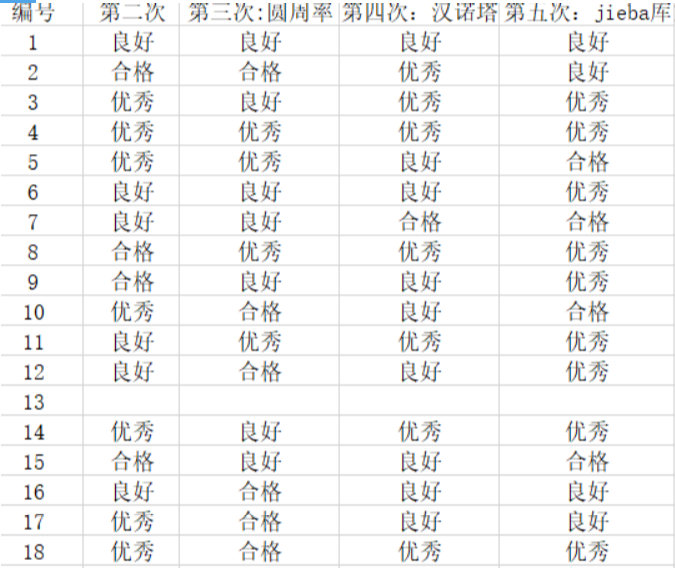
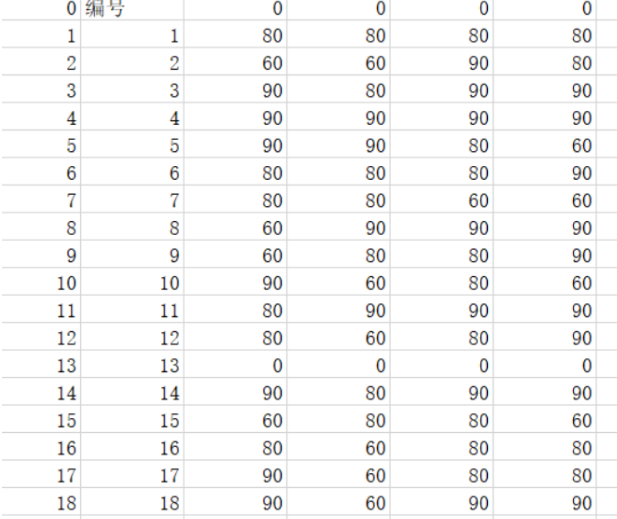
网页截图