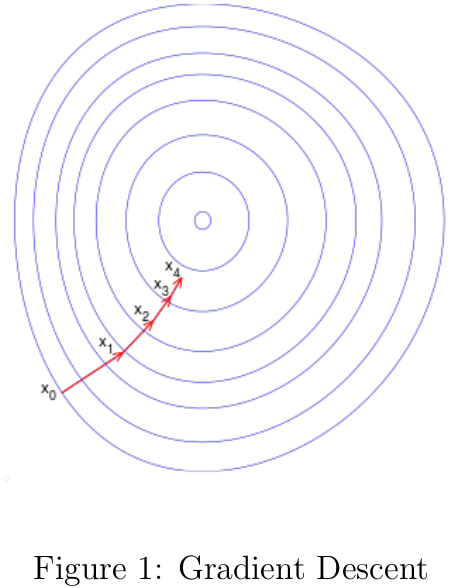
Gradient Descent
机器学习中很多模型的参数估计都要用到优化算法,梯度下降是其中最简单也用得最多的优化算法之一。梯度下降(Gradient Descent)[3]也被称之为最快梯度(Steepest Descent),可用于寻找函数的局部最小值。梯度下降的思路为,函数值在梯度反方向下降是最快的,只要沿着函数的梯度反方向移动足够小的距离到一个新的点,那么函数值必定是非递增的,如图1所示。
梯度下降思想的数学表述如下:
其中f(x)f(x)为存在下界的可导函数。根据该思路,如果我们从x0x0为出发点,每次沿着当前函数梯度反方向移动一定距离αkαk,得到序列x0,x1,⋯,xnx0,x1,⋯,xn:
对应的各点函数值序列之间的关系为:
很显然,当nn达到一定值时,函数f(x)f(x)是会收敛到局部最小值的。算法1简单描述了一般化的梯度优化方法。 在算法1中,我们需要选择一个搜索方向dkdk满足以下关系:
在算法1中,我们需要选择一个搜索方向dkdk满足以下关系:
当dk=−∇f(x)dk=−∇f(x)时f(x)f(x)下降最快,但是只要满足∇f(xk)Tdk<0∇f(xk)Tdk<0的dkdk都可以作为搜素方向。一般搜索方向表述为如下形式:
其中BkBk为正定矩阵。当Bk=IBk=I时对应最快梯度下降算法;当Bk=H(xk)−1Bk=H(xk)−1时对应牛顿法,如果H(xk)=∇2f(xk)H(xk)=∇2f(xk)为正定矩阵。 在迭代过程中用于更新xkxk的步长αkαk可以是常数也可以是变化的。如果αkαk足够小,收敛是可以得到保证的,但这意味这迭代次数nn要很大时函数才会收敛(图2(a));如果αkαk比较大,更新后的点很可能越过局部最优解(图2(b))。有什么方法可以帮助我们自动确定最优步长呢?下面要说的线性搜索就包含一组解决方案。
Line Search
在给定搜索方向dkdk的前提下,线性搜索要解决的问题如下:
如果h(α)h(α)是可微的凸函数,我们能通过解析解直接求得上式最优的步长;但非线性的优化问题需要通过迭代形式求得近似的最优步长。对于上式,局部或全局最优解对应的导数为h′(α)=∇f(xk+αdk)Tdk=0h′(α)=∇f(xk+αdk)Tdk=0。因为dkdk与f(xk)f(xk)在xkxk处的梯度方向夹角大于90度,因此h′(0)≤0h′(0)≤0,如果能找到α^α^使得h′(α^)>0h′(α^)>0,那么必定存在α⋆∈[0,α^)α⋆∈[0,α^)使得h′(α⋆)=0h′(α⋆)=0。有多种迭代算法可以求得α⋆α⋆的近似值,下面选择几种典型的介绍。
Bisection Search
二分线性搜索(Bisection Line Search)[2]可用于求解函数的根,其思想很简单,就是不断将现有区间划分为两半,选择必定含有使h′(α)=0h′(α)=0的半个区间作为下次迭代的区间,直到寻得h′(α⋆)≈0h′(α⋆)≈0为止,算法描述见2。 二分线性搜素可以确保h(α)h(α)是收敛的,只要h(α)h(α)在区间(0,α^)(0,α^)上是连续的且h′(0)h′(0)和h(α^)h(α^)异号。经历nn次迭代后,当前区间[αl,αh][αl,αh]的长度为:
二分线性搜素可以确保h(α)h(α)是收敛的,只要h(α)h(α)在区间(0,α^)(0,α^)上是连续的且h′(0)h′(0)和h(α^)h(α^)异号。经历nn次迭代后,当前区间[αl,αh][αl,αh]的长度为:
由迭代的终止条件之一αh−αl≥ϵαh−αl≥ϵ知迭代次数的上界为:
下面给出二分搜索的Python代码

1 def bisection(dfun,theta,args,d,low,high,maxiter=1e4):
2 """
3 #Functionality:find the root of the function(fun) in the interval [low,high]
4 #@Parameters
5 #dfun:compute the graident of function f(x)
6 #theta:Parameters of the model
7 #args:other variables needed to compute the value of dfun
8 #[low,high]:the interval which contains the root
9 #maxiter:the max number of iterations
10 """
11 eps=1e-6
12 val_low=np.sum(dfun(theta+low*d,args)*d.T)
13 val_high=np.sum(dfun(theta+high*d,args)*d.T)
14 if val_low*val_high>0:
15 raise Exception('Invalid interval!')
16 iter_num=1
17 while iter_num<maxiter:
18 mid=(low+high)/2
19 val_mid=np.sum(dfun(theta+mid*d,args)*d.T)
20 if abs(val_mid)<eps or abs(high-low)<eps:
21 return mid
22 elif val_mid*val_low>0:
23 low=mid
24 else:
25 high=mid
26 iter_num+=1
Backtracking
回溯线性搜索(Backing Line Search)[1]基于Armijo准则计算搜素方向上的最大步长,其基本思想是沿着搜索方向移动一个较大的步长估计值,然后以迭代形式不断缩减步长,直到该步长使得函数值f(xk+αdk)f(xk+αdk)相对与当前函数值f(xk)f(xk)的减小程度大于期望值(满足Armijo准则)为止。Armijo准则(见图3)的数学描述如下:
其中f:Rn→Rf:Rn→R,c1∈(0,1)c1∈(0,1),αα为步长,dk∈Rndk∈Rn为满足f′(xk)Tdk<0f′(xk)Tdk<0的搜索方向。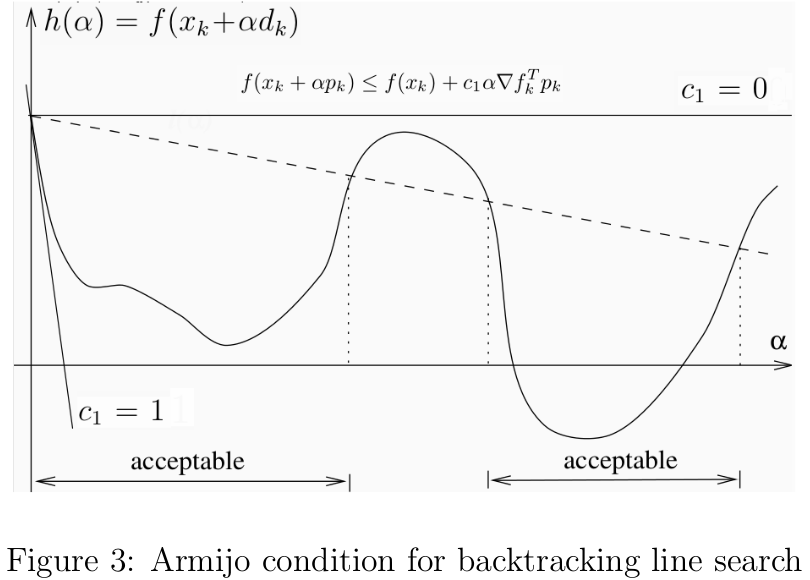 但是仅凭Armijo准则不足以求得较好的步长,根据前面的梯度下降的知识可知,只要αα足够小就能满足Armijo准则。因此常用的策略就是从较大的步长开始,然后以τ∈(0,1)τ∈(0,1)的速度缩短步长,直到满足Armijo准则为止,这样选出来的步长不至于太小,对应的算法描述见3。前面介绍的二分线性搜索的目标是求得满足h′(α)≈0h′(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。前者可以少计算几次搜索方向,但在计算最优步长上花费了不少代价;后者退而求其次,找到一个差不多的步长即可,那么代价就是要多计算几次搜索方向。
但是仅凭Armijo准则不足以求得较好的步长,根据前面的梯度下降的知识可知,只要αα足够小就能满足Armijo准则。因此常用的策略就是从较大的步长开始,然后以τ∈(0,1)τ∈(0,1)的速度缩短步长,直到满足Armijo准则为止,这样选出来的步长不至于太小,对应的算法描述见3。前面介绍的二分线性搜索的目标是求得满足h′(α)≈0h′(α)≈0的最优步长近似值,而回溯线性搜索放松了对步长的约束,只要步长能使函数值有足够大的变化即可。前者可以少计算几次搜索方向,但在计算最优步长上花费了不少代价;后者退而求其次,找到一个差不多的步长即可,那么代价就是要多计算几次搜索方向。 接下来,我们要证明回溯线性搜索在Armijo准则下的收敛性问题[6]。因为h′(0)=f′(xk)Tdk<0h′(0)=f′(xk)Tdk<0,且0<c1<10<c1<1,则有
接下来,我们要证明回溯线性搜索在Armijo准则下的收敛性问题[6]。因为h′(0)=f′(xk)Tdk<0h′(0)=f′(xk)Tdk<0,且0<c1<10<c1<1,则有
根据导数的基本定义,结合上式,有如下关系:
因此,存在一个步长α^>0α^>0,对任意的α∈(0,α^)α∈(0,α^),下式均成立
即∀α∈(0,α^),f(xk+αdk)<f(xk)+cαf′(xk)Tdk∀α∈(0,α^),f(xk+αdk)<f(xk)+cαf′(xk)Tdk。 下面给出基于Armijo准则的线性搜索Python代码:
1 def ArmijoBacktrack(fun,dfun,theta,args,d,stepsize=1,tau=0.5,c1=1e-3): 2 """ 3 #Functionality:find an acceptable stepsize via backtrack under Armijo rule 4 #@Parameters 5 #fun:compute the value of objective function 6 #dfun:compute the gradient of objective function 7 #theta:a vector of parameters of the model 8 #stepsize:initial step size 9 #c1:sufficient decrease Parameters 10 #tau:rate of shrink of stepsize 11 """ 12 slope=np.sum(dfun(theta,args)*d.T) 13 obj_old=costFunction(theta,args) 14 theta_new=theta+stepsize*d 15 obj_new=costFunction(theta_new,args) 16 while obj_new>obj_old+c1*stepsize*slope: 17 stepsize*=tau 18 theta_new=theta+stepsize*d 19 obj_new=costFunction(theta_new,args) 20 return stepsize
Interpolation
基于Armijo准则的回溯线性搜索的收敛速度无法得到保证,特别是要回退很多次后才能落入满足Armijo准则的区间。如果我们根据已有的函数值和导数信息,采用多项式插值法(Interpolation)[12,6,5,9]拟合函数,然后根据该多项式函数估计函数的极值点,这样选择合适步长的效率会高很多。 假设我们只有xkxk处的函数值f(xk)f(xk)及其倒数f′(xk)f′(xk),且第一次尝试的步长为α0α0。如果α0α0不满足条件,那么我们根据这些信息可以构造一个二次近似函数hq(α)hq(α)
注意,该二次函数满足hq(0)=h(0)hq(0)=h(0),h′q(0)=h′(0)hq′(0)=h′(0)和hq(α0)=h(α0)hq(α0)=h(α0),如图4(a)所示。接下来,根据hq(α)hq(α)的最小值估计下一个步长:
如果α1α1仍然不满足条件,我们可以继续重复上述过程,直到得到的步长满足条件为止。假设我们在整个线性搜索过程中都用二次插值函数,那么最好有c1∈(0,0.5]c1∈(0,0.5],为什么呢?简单证明一下:如果α0α0不满足Armijo准则,那么必定存在比α0α0小的步长满足该准则,所以利用二次插值函数估算的步长α1<α0α1<α0才合理。结合α0α0不满足Armijo准则和α1<α0α1<α0,可知c1≤0.5c1≤0.5。 如果我们已经尝试了多个步长,却每次只用上一次步长的相关信息构造二次函数,未免是对计算资源的浪费,其实我们可以利用多个步长的信息构造信息量更大更准确的插值函数的。在计算导数的代价大于计算函数值的代价时,应尽量避免计算h′(α)h′(α),下面给出一个三次插值函数hc(α)hc(α),如图4(b)所示
其中
对hc(α)hc(α)求导,可得极值点αi+1∈[0,αi]αi+1∈[0,αi]的形式如下:
利用以上的三次插值函数求解下一个步长的过程不断重复,直到步长满足条件为止。如果出现a=0a=0的情况,三次插值函数退化为二次插值函数,在实现该算法时需要注意这点。在此过程中,如果αiαi太小或αi−1αi−1与αiαi太接近,需要重置αi=αi−1/2αi=αi−1/2,该保护措施(safeguards)保证下一次的步长不至于太小[6,5]。为什么会有这个作用呢?1)因为αi+1∈[0,αi]αi+1∈[0,αi],所以当αiαi很小时αi+1αi+1也很小;2)当αi−1αi−1与αiαi太靠近时有a≈b≈∞a≈b≈∞,根据αi+1αi+1的表达式可知αi+1≈0αi+1≈0。 但是,在很多情况下,计算函数值后只需付出较小的代价就能顺带计算出导数值或其近似值,这使得我们可以用更精确的三次Hermite多项式[6]进行插值,如图4(c)所示