摘自:https://zhuanlan.zhihu.com/p/349607083
原文地址:https://towardsdatascience.com/pandas-vs-sql-in-5-examples-485b5571d934
本文的重点是在合并和连接操作方面比较Pandas和SQL。Pandas是一个用于Python的数据分析和操作库。SQL是一种用于管理关系数据库中的数据的编程语言。两者都使用带标签的行和列的表格数据。
Pandas的merge函数根据公共列中的值组合dataframe。SQL中的join可以执行相同的操作。这些操作非常有用,特别是当我们在表的不同数据中具有共同的数据列(即数据点)时。
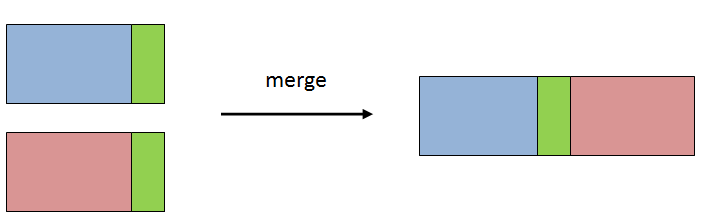
pandas的merge图解
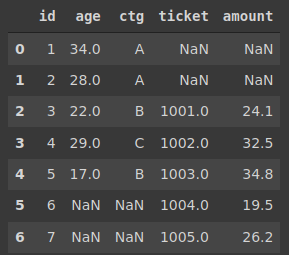
我创建了两个简单的dataframe和表,通过示例来说明合并和连接。
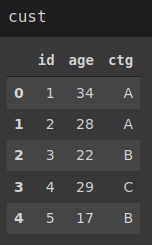
“cust”包含5个客户的3条信息。列是id、年龄和类别。

“purc”包含客户id、机票号码和购买金额。
id是共同列的列,所以我们将在合并或联接时使用它。
您可能已经注意到,id列并不完全相同。有些值只存在于一个dataframe中。我们将在示例中看到处理它们的方法。
示例1
第一个示例是基于id列中的共享值进行合并或连接。使用默认设置完成了这个任务,所以我们不需要调整任何参数。
import pandas as pd
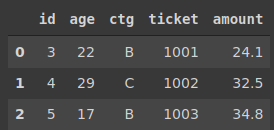
cust.merge(purc, on='id')
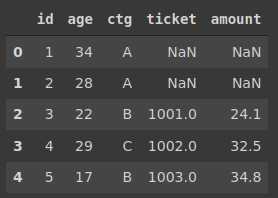
Pandas的merge函数不会返回重复的列。另一方面,如果我们选择两个表中的所有列(“*”),则在SQL join中id列是重复的。
mysql> select cust.*, purc.*
-> from cust join purc
-> on cust.id = purc.id
;+------+------+------+------+--------+--------+
| id | age | ctg | id | ticket | amount |
+------+------+------+------+--------+--------+
| 3 | 22 | B | 3 | 1001 | 24.10 |
| 4 | 29 | C | 4 | 1002 | 32.50 |
| 5 | 17 | B | 5 | 1003 | 34.80 |
+------+------+------+------+--------+--------+示例2
假设我们希望左表中有所有的行,而右表中只有匹配的行。在Pandas中,on参数被更改为“left”。在SQL中,我们使用“left join”而不是“join”关键字。
cust.merge(purc, on='id', how='left')
mysql> select cust.*, purc.*
-> from cust
-> left join purc
-> on cust.id = purc.id
;+------+------+------+------+--------+--------+
| id | age | ctg | id | ticket | amount |
+------+------+------+------+--------+--------+
| 3 | 22 | B | 3 | 1001 | 24.10 |
| 4 | 29 | C | 4 | 1002 | 32.50 |
| 5 | 17 | B | 5 | 1003 | 34.80 |
| 1 | 34 | A | NULL | NULL | NULL |
| 2 | 28 | A | NULL | NULL | NULL |purcdataframe和表中没有id为1或2的行。因此,purc中的列中填充了这些行的空值。
示例3
如果我们想要看到两个dataframe或表中的所有行,该怎么办?
在Pandas中,这是一个简单的操作,可以通过将' outer '参数传递给on形参来完成。
cust.merge(purc, on='id', how='outer')
MySQL没有提供“完整的外连接”,但是我们可以通过两个左连接来实现。
注意:尽管关系数据库管理系统(rdbms)采用的SQL语法基本相同,但可能会有一些细微的差异。因此,最好检查特定RDBMS的文档,看看它是否支持完整的外部连接。
在MySQL中,完整的外连接可以通过两个左连接实现:
mysql> select cust.*, purc.*
-> from cust left join purc
-> on cust.id = purc.id
-> union
-> select cust.*, purc.*
-> from purc left join cust
-> on cust.id = purc.id
;+------+------+------+------+--------+--------+
| id | age | ctg | id | ticket | amount |
+------+------+------+------+--------+--------+
| 3 | 22 | B | 3 | 1001 | 24.10 |
| 4 | 29 | C | 4 | 1002 | 32.50 |
| 5 | 17 | B | 5 | 1003 | 34.80 |
| 1 | 34 | A | NULL | NULL | NULL |
| 2 | 28 | A | NULL | NULL | NULL |
| NULL | NULL | NULL | 6 | 1004 | 19.50 |
| NULL | NULL | NULL | 7 | 1005 | 26.20 |
+------+------+------+------+--------+--------+union操作符将多个查询的结果堆叠起来。这类似于Pandas的concat功能。
示例4
合并或联接不仅仅是合并数据。我们可以把它们作为数据分析的工具。例如,我们可以计算每个类别(“ctg”)的总订单金额。
cust.merge(purc, on='id', how='left')[['ctg','amount']].groupby('ctg').mean()
ctg amount
--------------
A NaN
B 29.45
C 32.50因为purc表不包含任何属于类别A中的客户的购买,所以sum结果为Null。
mysql> select cust.ctg, sum(purc.amount)
-> from cust
-> left join purc
-> on cust.id = purc.id
-> group by cust.ctg
;+------+------------------+
| ctg | sum(purc.amount) |
+------+------------------+
| A | NULL |
| B | 58.90 |
| C | 32.50 |
+------+------------------+示例5
我们还可以在组合之前根据条件筛选行。让我们假设我们需要找到小于25岁的客户的购买量。
对于pandas 我们首先过滤dataframe,然后应用合并函数。
cust[cust.age < 25].merge(purc, on='id', how='left')[['age','amount']]
age amount
0 22 24.1
1 17 34.8mysql使用一个where子句来指定过滤条件。
mysql> select cust.age, purc.amount
-> from cust
-> join purc
-> on cust.id = purc.id
-> where cust.age < 25
;+------+--------+
| age | amount |
+------+--------+
| 22 | 24.10 |
| 17 | 34.80 |
+------+--------+总结
我们已经介绍了一些示例来演示Pandas合并函数和SQL连接之间的区别和相似之处。
这些例子可以看作是简单的案例,但是它们可以帮助您建立直觉并理解基础知识。在理解了基础知识之后,您可以构建更高级的操作。