补充知识
根据看别人打代码,使用的模块,封装的方法。
PyExecJS、python Click(定制命令)、gunicorn(是一个wsgi协议的web服务器)结合Flask后端部署。
手机爬虫
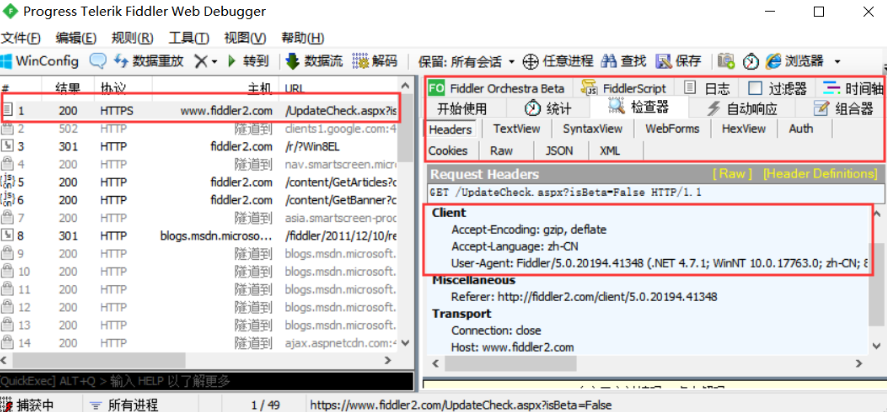
抓包工具:
前提条件:
1).电脑需要安装Fiddler 2).测试手机需要支持Wifi 3).测试手机与电脑需要同一网络 4).所测APP需支持代理
app加固、Android安卓动态调试 概念
fiddler手机抓包原理
在本机开启了一个http的代理服务器,然后它会转发所有的http请求和响应。Fiddler 是以代理web 服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888。网络请求走fiddler,fiddler从中拦截数据,由于fiddler充当中间人的角色,所以可以解密https。因此,它比一般的firebug或者是chrome自带的抓包工具要好用的多。不仅如此,它还可以支持请求重放等一些高级功能。它还可以支持对手机应用进行http抓包的。本文就是手机抓包。
selenium的使用
选择器基本用法
# 1、find_element_by_id 根据id找 # 2、find_element_by_link_text 根据链接名字找到控件(a标签的文字) # 3、find_element_by_partial_link_text 根据链接名字找到控件(a标签的文字)模糊查询 # 4、find_element_by_tag_name 根据标签名 # 5、find_element_by_class_name 根据类名 # 6、find_element_by_name 根据属性名 # 7、find_element_by_css_selector 根据css选择器 # 8、find_element_by_xpath 根据xpath选择
代码实例:模拟自动化账号登录。
from selenium import webdriver import time bro=webdriver.Chrome() bro.get("http://www.baidu.com") bro.implicitly_wait(10) dl_button=bro.find_element_by_link_text("登录") dl_button.click() user_login=bro.find_element_by_id('TANGRAM__PSP_10__footerULoginBtn') user_login.click() time.sleep(1) input_name=bro.find_element_by_name('userName') input_name.send_keys("30323545@qq.com") input_password=bro.find_element_by_id("TANGRAM__PSP_10__password") input_password.send_keys("xxxxxx") submit_button=bro.find_element_by_id('TANGRAM__PSP_10__submit') time.sleep(1) submit_button.click() time.sleep(100) print(bro.get_cookies()) bro.close()

获取cookies的结果
显示等待和隐示等待
#隐式等待:在查找所有元素时,如果尚未被加载,则等10秒 # browser.implicitly_wait(10) 表示等待所有, #显式等待:显式地等待某个元素被加载 # wait=WebDriverWait(browser,10) # wait.until(EC.presence_of_element_located((By.ID,'content_left')))
爬取京东商品信息
打开京东页面搜索游戏本电脑分析:

打开分析:
利用选择器,逐一往下查
评论数:
# commit = good.find_element_by_css_selector('.p-commit a').text

代码实例:
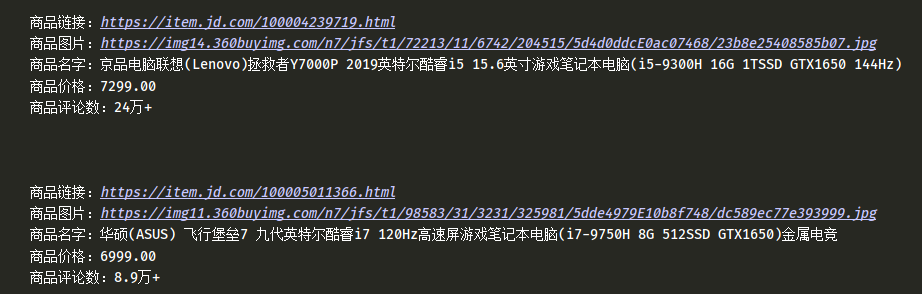
from selenium import webdriver from selenium.webdriver.common.keys import Keys #键盘按键操作 import time bro=webdriver.Chrome() bro.get("https://www.jd.com") bro.implicitly_wait(10) def get_goods(bro): print("--------------------------") 分页 goods_li = bro.find_elements_by_class_name('gl-item') for good in goods_li: img_url = good.find_element_by_css_selector('.p-img a img').get_attribute('src') if not img_url: img_url = 'https:' + good.find_element_by_css_selector('.p-img a img').get_attribute('data-lazy-img') url = good.find_element_by_css_selector('.p-img a').get_attribute('href') price = good.find_element_by_css_selector('.p-price i').text name = good.find_element_by_css_selector('.p-name em').text.replace(' ', '') commit = good.find_element_by_css_selector('.p-commit a').text print(''' 商品链接:%s 商品图片:%s 商品名字:%s 商品价格:%s 商品评论数:%s ''' % (url, img_url, name, price, commit)) next_page = bro.find_element_by_partial_link_text("下一页") time.sleep(1) next_page.click() time.sleep(1) get_goods(bro) input_search=bro.find_element_by_id('key') input_search.send_keys("游戏本电脑") input_search.send_keys(Keys.ENTER) #进入了另一个页面 try: get_goods(bro) except Exception as e: print("结束") finally: bro.close()
selenium 其他用法
获取标签属性
#获取属性: # tag.get_attribute('src') #获取文本内容 # tag.text #获取标签ID,位置,名称,大小(了解) # print(tag.id) # print(tag.location) # print(tag.tag_name) # print(tag.size) #模拟浏览器前进后退 # browser.back() # time.sleep(10) # browser.forward() #cookies管理 print(browser.get_cookies()) 获取cookie browser.add_cookie({'k1':'xxx','k2':'yyy'}) 设置cookie print(browser.get_cookies()) #运行js # from selenium import webdriver # import time # # bro=webdriver.Chrome() # bro.get("http://www.baidu.com") # bro.execute_script('alert("hello world")') #打印警告 # time.sleep(5) #选项卡管理 # import time # from selenium import webdriver # # browser=webdriver.Chrome() # browser.get('https://www.baidu.com') # browser.execute_script('window.open()') # # print(browser.window_handles) #获取所有的选项卡 # browser.switch_to_window(browser.window_handles[1]) # browser.get('https://www.taobao.com') # time.sleep(3) # browser.switch_to_window(browser.window_handles[0]) # browser.get('https://www.sina.com.cn') # browser.close() #动作链 # from selenium import webdriver # from selenium.webdriver import ActionChains # # from selenium.webdriver.support.wait import WebDriverWait # 等待页面加载某些元素 # import time # # driver = webdriver.Chrome() # driver.get('http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable') # wait=WebDriverWait(driver,3) # # driver.implicitly_wait(3) # 使用隐式等待 # # try: # driver.switch_to.frame('iframeResult') ##切换到iframeResult # sourse=driver.find_element_by_id('draggable') # target=driver.find_element_by_id('droppable') # # # #方式一:基于同一个动作链串行执行 # # actions=ActionChains(driver) #拿到动作链对象 # # actions.drag_and_drop(sourse,target) #把动作放到动作链中,准备串行执行 # # actions.perform() # # #方式二:不同的动作链,每次移动的位移都不同 # # ActionChains(driver).click_and_hold(sourse).perform() # distance=target.location['x']-sourse.location['x'] # track=0 # while track < distance: # ActionChains(driver).move_by_offset(xoffset=2,yoffset=0).perform() # track+=2 # # ActionChains(driver).release().perform() # # time.sleep(10) # # finally: # driver.close()
selenium拿到cookie;requests使用
先手动登录,获取cookies,再用requests携带cookies实现登录。用request发送会比selenium速度快写=些。
import time from selenium import webdriver import json # browser=webdriver.Chrome() # browser.get('https://account.cnblogs.com/signin?returnUrl=https%3A%2F%2Fwww.cnblogs.com%2F') # # time.sleep(30) # cookie=browser.get_cookies() # print(cookie) # with open('cookie.json','w')as f: # json.dump(cookie,f)
#下一次 # import time # from selenium import webdriver # import json # browser=webdriver.Chrome() # browser.get('https://www.cnblogs.com/') # with open('cookie.json','r')as f: # di=json.load(f) # # cookies = {} # # 获取cookie中的name和value,转化成requests可以使用的形式 # for cookie in di: # cookies[cookie['name']] = cookie['value'] # print(cookies) # browser.add_cookie(cookies) # browser.refresh() # # time.sleep(10)
#request模块模拟 import requests with open('cookie.json','r')as f: di=json.load(f) cookies = {} # 获取cookie中的name和value,转化成requests可以使用的形式 for cookie in di: print(cookie) for key in cookie.keys(): cookies[key] = cookie[key] print(cookies) res=requests.get('https://i-beta.cnblogs.com/api/user', cookies=cookies) print(res.text)
验证码破解(了解)
tesseract-ocr-4.00的安装与初步进行图片文字识别

在线打码平台:
python桌面开发、百度ocr识别、python Tkinter
requests-html介绍
请求加解析前端数据,支持javascript
详细参考中文的官方文档:
知乎破解加密算法模拟登陆
详见:https://www.cnblogs.com/xiaoyuanqujing/articles/11843045.html
#破解知乎登录 from requests_html import HTMLSession #请求解析库 import base64 #base64解密加密库 from PIL import Image #图片处理库 import hmac #加密库 from hashlib import sha1 #加密库 import time from urllib.parse import urlencode #url编码库 import execjs #python调用node.js from http import cookiejar class Spider(): def __init__(self): self.session = HTMLSession() self.session.cookies = cookiejar.LWPCookieJar() #使cookie可以调用save和load方法 self.login_page_url = 'https://www.zhihu.com/signin?next=%2F' self.login_api = 'https://www.zhihu.com/api/v3/oauth/sign_in' self.captcha_api = 'https://www.zhihu.com/api/v3/oauth/captcha?lang=en' self.headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER', } self.captcha ='' #存验证码 self.signature = '' #存签名 # 首次请求获取cookie def get_base_cookie(self): self.session.get(url=self.login_page_url, headers=self.headers) # 处理验证码 def deal_captcha(self): r = self.session.get(url=self.captcha_api, headers=self.headers) r = r.json() if r.get('show_captcha'): while True: r = self.session.put(url=self.captcha_api, headers=self.headers) img_base64 = r.json().get('img_base64') with open('captcha.png', 'wb') as f: f.write(base64.b64decode(img_base64)) captcha_img = Image.open('captcha.png') captcha_img.show() self.captcha = input('输入验证码:') r = self.session.post(url=self.captcha_api, data={'input_text': self.captcha}, headers=self.headers) if r.json().get('success'): break def get_signature(self): # 生成加密签名 a = hmac.new(b'd1b964811afb40118a12068ff74a12f4', digestmod=sha1) a.update(b'password') a.update(b'c3cef7c66a1843f8b3a9e6a1e3160e20') a.update(b'com.zhihu.web') a.update(str(int(time.time() * 1000)).encode('utf-8')) self.signature = a.hexdigest() def post_login_data(self): data = { 'client_id': 'c3cef7c66a1843f8b3a9e6a1e3160e20', 'grant_type': 'password', 'timestamp': str(int(time.time() * 1000)), 'source': 'com.zhihu.web', 'signature': self.signature, 'username': '+8618953675221', 'password': 'lqz12345', 'captcha': self.captcha, 'lang': 'en', 'utm_source': '', 'ref_source': 'other_https://www.zhihu.com/signin?next=%2F', } headers = { 'x-zse-83': '3_2.0', 'content-type': 'application/x-www-form-urlencoded', 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.98 Safari/537.36 LBBROWSER', } data = urlencode(data) with open('ttt.js', 'rt', encoding='utf-8') as f: js = execjs.compile(f.read()) data = js.call('b', data) print(data) r = self.session.post(url=self.login_api, headers=headers, data=data) if r.status_code == 201: self.session.cookies.save('mycookie') print('登录成功') else: print('登录失败') def login(self): self.get_base_cookie() self.deal_captcha() self.get_signature() self.post_login_data() if __name__ == '__main__': zhihu_spider = Spider() zhihu_spider.login()
XPath
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上。
因此,对 XPath 的理解是很多高级 XML 应用的基础。
选取节点
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。

doc=''' <html> <head> <base href='http://example.com/' /> <title>Example website</title> </head> <body> <div id='images'> <a href='image1.html' a="xxx">Name: My image 1 <br /><img src='image1_thumb.jpg' /></a> <a href='image2.html'>Name: My image 2 <br /><img src='image2_thumb.jpg' /></a> <a href='image3.html'>Name: My image 3 <br /><img src='image3_thumb.jpg' /></a> <a href='image4.html' class='li'>Name: My image 4 <br /><img src='image4_thumb.jpg' /></a> <a href='image5.html' class='li li-item' name='items'>Name: My image 5 <br /><img src='image5_thumb.jpg' /></a> <a href='image6.html' name='items'><span><h5>test</h5></span>Name: My image 6 <br /><img src='image6_thumb.jpg' /></a> </div> </body> </html> ''' from lxml import etree html=etree.HTML(doc) # html=etree.parse('search.html',etree.HTMLParser()) # 1 所有节点 a=html.xpath('//*') #匹配所有标签 # 2 指定节点(结果为列表) # a=html.xpath('//head') # 3 子节点,子孙节点 a=html.xpath('//div/a') a=html.xpath('//body/a') #无数据 a=html.xpath('//body//a') # 4 父节点 # a=html.xpath('//body//a[@href="image1.html"]/..') a=html.xpath('//body//a[1]/..') #从1开始 # 也可以这样 a=html.xpath('//body//a[1]/parent::*') # 5 属性匹配 a=html.xpath('//body//a[@href="image1.html"]') # 6 文本获取 a=html.xpath('//body//a[@href="image1.html"]/text()') a=html.xpath('//body//a/text()') # 7 属性获取 # a=html.xpath('//body//a/@href') # # 注意从1 开始取(不是从0) a=html.xpath('//body//a[2]/@href') # 8 属性多值匹配 # a 标签有多个class类,直接匹配就不可以了,需要用contains # a=html.xpath('//body//a[@class="li"]') a=html.xpath('//body//a[contains(@class,"li")]/text()') # a=html.xpath('//body//a[contains(@class,"li")]/text()') # 9 多属性匹配 a=html.xpath('//body//a[contains(@class,"li") or @name="items"]') a=html.xpath('//body//a[contains(@class,"li") and @name="items"]/text()') a=html.xpath('//body//a[contains(@class,"li")]/text()') # 10 按序选择 a=html.xpath('//a[2]/text()') a=html.xpath('//a[2]/@href') # 取最后一个 a=html.xpath('//a[last()]/@href') # 位置小于3的 a=html.xpath('//a[position()<3]/@href') # 倒数第二个 a=html.xpath('//a[last()-2]/@href') # 11 节点轴选择 # ancestor:祖先节点 # 使用了* 获取所有祖先节点 a=html.xpath('//a/ancestor::*') # # 获取祖先节点中的div a=html.xpath('//a/ancestor::div') # attribute:属性值 a=html.xpath('//a[1]/attribute::*') # child:直接子节点 a=html.xpath('//a[1]/child::*') # descendant:所有子孙节点 a=html.xpath('//a[6]/descendant::*') # following:当前节点之后所有节点 a=html.xpath('//a[1]/following::*') a=html.xpath('//a[1]/following::*[1]/@href') # following-sibling:当前节点之后同级节点 a=html.xpath('//a[1]/following-sibling::*') a=html.xpath('//a[1]/following-sibling::a') a=html.xpath('//a[1]/following-sibling::*[2]/text()') a=html.xpath('//a[1]/following-sibling::*[2]/@href') print(a)