1. 开发环境&生产环境
1.1 开发环境
平时在写代码时,大多都是在Win10/Win7/Mac上,这些系统都可以称呼为开发系统,咱们会为了更高效的开发应用程序,安装很多很多的软件,会导致操作系统不安全(安多了软件),稳定性降低。
1.2 生产环境
- 在生产环境中,操作系统不会采用Win10/Mac等,这种操作系统相对不安全,生产环境是要面向全体用户的,一般会采用专业的操作系统。
- 大多失眠上使用的都是基于Linux的操作系统,当然还有Windows版本的服务器操作系统,Windows 2003 service等等。
- 由于Linux内核版本完全对外开源,市场占有率大,所以第一步我们要学会如何操作Linux操作系统。
2. Web1.0&Web2.0阶段
2.1 Web1.0阶段
在web1.0阶段,由于带宽不足,这时的项目大多是内容少,用户量也不多,甚至有一些项目不需要对外开放,对安全性和稳定性的要求是不高的。
此时的单体框架就足以应对。
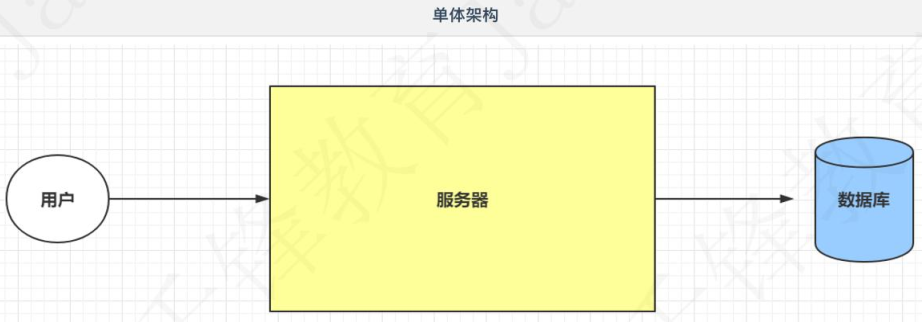
2.2 Web2.0阶段
随之而来的web2.0阶段,实现了ADSL拨号上网,宽带提速,最高可以达到8M,用户量也就不断增加,一些用户网站也开始活跃,项目就需要考虑安全性和稳定性。
在基于上面的单体架构图中,无法满足Web2.0对项目的需求。
在单体架构的基础上去搭建集群。
在搭建集群之后,可以提升项目的稳定性(一个服务器挂了,还有其它的),并且并发能力增强(服务器多,自然强),还可以避免单点故障(什么是单点故障??)。

2.3 搭建集群后发生的问题
- 用户的请求到底要发送到哪台服务器上。如何保证请求平均的分发给不同的服务器,从而缓解用户量增加的压力。
- 编写项目时,如果用户登录成功了,将用户的标识放到Session中,在搭建集群之后,数据共享问题(Session是基于Tomcat服务器的,如何保证在服务器1上登录成功,2和3都是知道的)。
- 当数据量特别庞大时,如果还直接去数据库查询,速度很慢,如何提升查询效率(当然可以通过SQL优化,但是SQL优化是有限的)。
- 针对大家在搜索一些数据时,如果用where content like '%#{xxx}%',用这种通配符去数据库查,用户量多,直接GG。
- 等等..........
为了解决上述的问题,需要使用到三门技术。
- Nginx-解决用户请求平均分发。
- Redis-解决数据共享并实现缓存功能。
- ElasticSearch-解决搜索数据的功能。
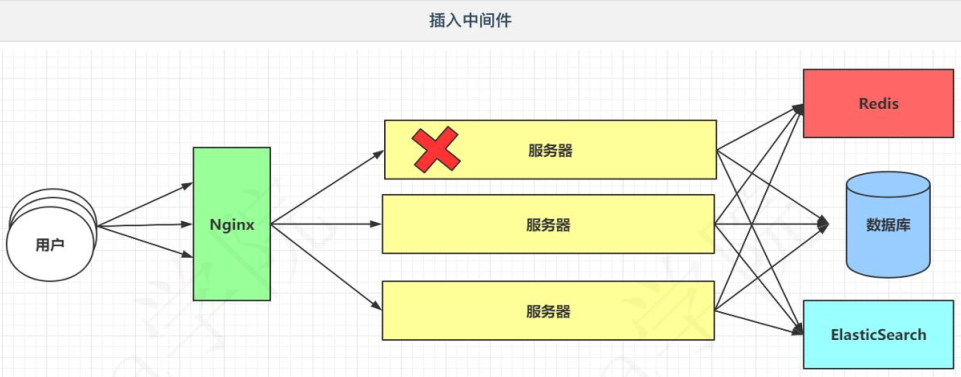
3. 垂直结构
比如项目包含了三个模块,用户模块、商品模块、订单模块。如果商品模块压力过大(浏览的肯定比下单的多),一般最直接有效的方式就是搭建集群。在单体架构的集群上去搭建,效果相对比较差。
随着项目的不断更新,项目中的功能越来越多,最严重可能会导致项目无法启动(项目无法启动,项目启动肯定要占用jvm内存,如果项目过大,则jvm内存不够用)。
关于单体架构中,完美的体现了低内聚,高耦合,避开了开发的准则(我们需要高内聚,低耦合)。
为了解决上述的各种问题,演进出了垂直架构。
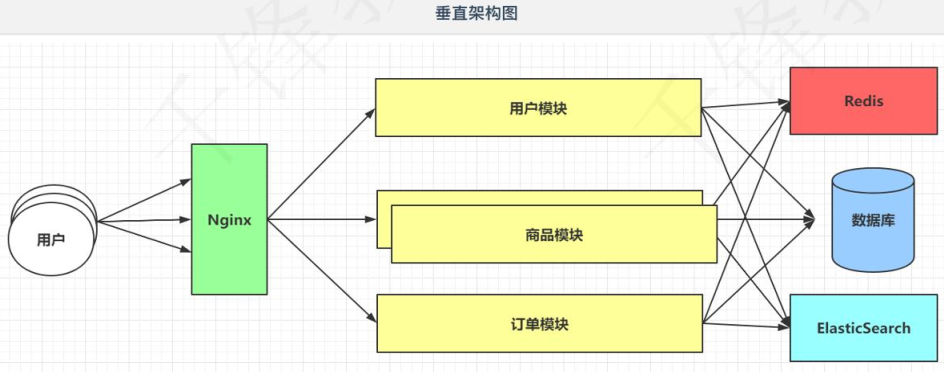
4. 分布式结构
随着项目的不断迭代,新老功能之间需要交互,服务器和服务器之间是需要通讯的(上面并没有提供相应的功能,我们可能需要HttpClient或者是RestTmplate等,这样的话,通信成本是比较高的)。
对于上面垂直架构,由于商品模块访问量大,因此针对商品模块进行了集群的搭建。但项目一般分为三层的,Controller,Service,Dao。导致程序变慢的重灾区,一般是Service和Dao(需要通过IO读取数据库),在搭建进群时,确实针对三层都搭建进群,效果不是很好。
架构从垂直架构演变到了分布式架构(所有模块之间都可以相互通信,只是为了图不复杂,没有完全画出)。
分布式架构落地的技术,国内通讯的方式有两种
- Dubbo RPC(通讯方式)阿里系
- SpringCloud HTTP(通讯方式)
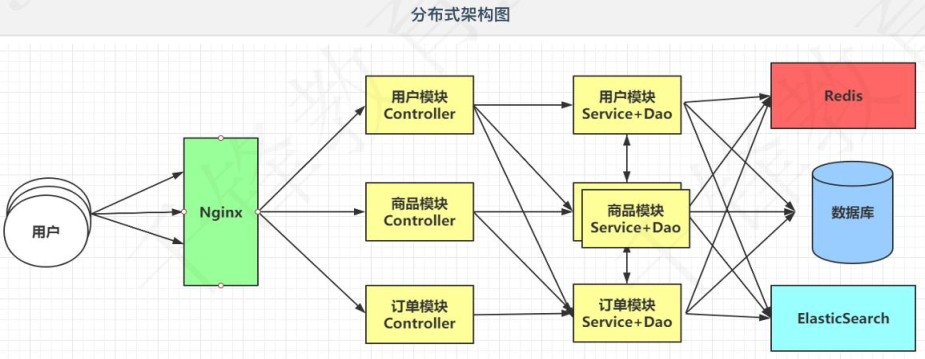
5. 分布式架构常见问题
5.1 服务之间的异步通讯
这里的服务之间就是模块之间
使用分布式架构之后,服务之间的通信都是同步的(比如商品模块Controller需要访问用户模块Service+Dao和订单模块Service+Dao之后才能完成功能,假设每个模块需要1秒,那则是三秒。这是非常要命的,但是对于核心业务那是必须等待的。但假如是非核心业务呢?即如果访问商品模块Controller后需要打印日志,这个只要发送打印需求就好,你什么时候打印我不太操心,这样如果是同步通信就不是很完美了(使用分布式架构之后,服务之间的通信都是同步的))。
在一些不是核心业务的功能上,咱们希望可以实现异步通讯。
为了实现服务之间的异步通讯,需要学习MQ,而MQ有很多,我们要学的是RabbitMQ(即订单模块Controller操作后需要与日志模块的Service和Dao通讯,但是这里用同步不合适,因此用异步通讯MQ,这里采用RabbitMQ技术,订单模块Controller先发送信息给MQ,然后就不管了,而MQ是一个消息队列,它在合适的时候访问日志模块的Service和Dao)。
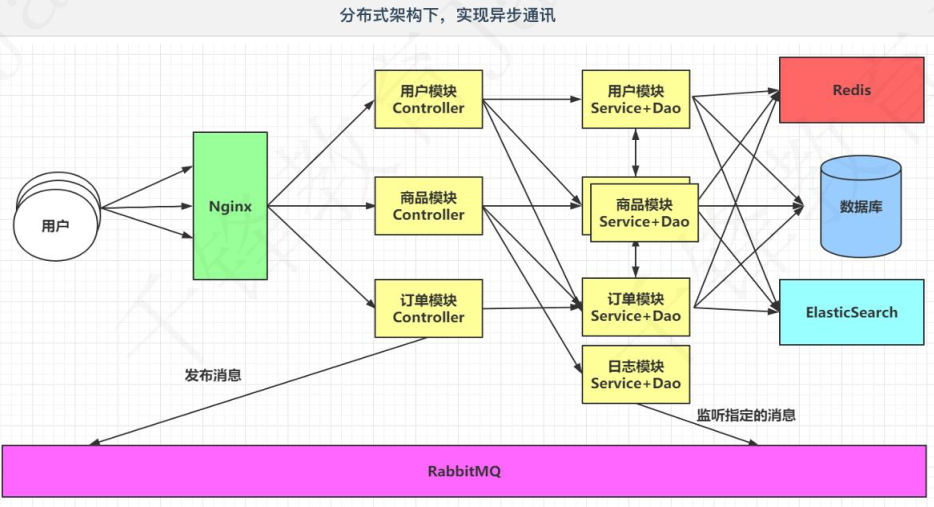
5.2 服务之间通讯地址的维护
由于服务越来越多(以前一个独立的服务拆分成好多单独的服务,并且喝多服务还要搭建集群),每个服务的访问地址都是不一样的:协议://ip地址:端口号/路径
由于模块繁多,并且模块搭建的集群数量增加,会导致其它模块需要维护各种ip地址等信息,导致项目维护性极低,耦合性变高,并且实现负责均衡也变得麻烦。
需要使用以下技术来解决当前问题:
- Eureka注册中心帮助我们管理服务信息(所有的通讯地址都在Eureka中维护,比如用户模块Controller像访问商品模块Service+Dao,不需要知道其地址,只需要向Eureka去拿地址即可。注意:这里不是通过Eureka访问,而是去拿地址,依然是用户模块Controller访问商品模块Service+Dao)。
- Robbin可以帮我们实现服务之间的负载均衡(此时去Eureka去拿地址访问但还是商品模块中第一个模块,那商品模块的集群就没有效果,这时候就要实现负责均衡)。
Nginx是服务器端负载均衡:
negix是客户端所有请求统一交给negix,由negix进行实现负载均衡请求转发,属于服务端负载均衡。
即请求由negix服务器端进行转发,是客户端到服务器端之间的负载均衡。
Rabbion是客户端负载均衡(我怎么感觉这样写是不对的)
Ribbon 是从 eureka 注册中心服务器端上获取服务注册信息列表,缓存到本地,然后在本地实现轮询负载均衡策略。
这是模块之间,即服务之间的负载均衡。
Rabbion是在客户端实现复杂均衡,Rabbion是在本地,即在访问的那块,即如果是商品模块Controller访问订单模块Service+Dao,则Rabbion是放在客户端(商品模块Controller)中的。
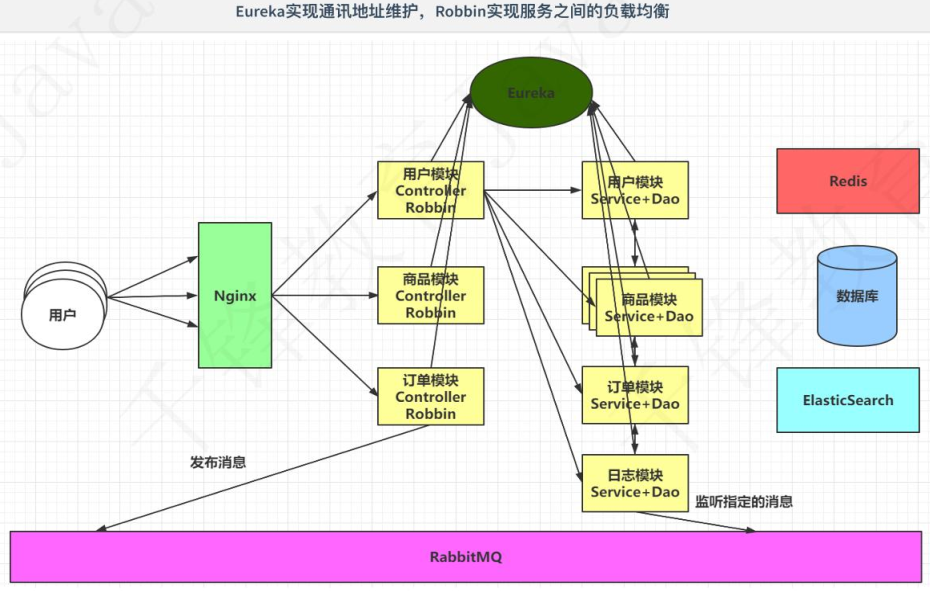
5.3 服务降级
在上述的架构中,如果说订单模块出现了问题,只要是设计到订单的功能,全部都无法使用(所有访问订单模块Service+Dao的模块在等待一段时间后,超时时间已过,就抛出异常),甚至可能会导致服务器提供的线程池耗尽。给用户友好的提示都是无法做到的(不懂)。
为了解决上述的问题,使用Hystrix处理:
Hystrix提供了线程池隔离的方式,避免服务器线程池耗尽,在一个服务无法使用时,还提供断路器的方式来处理问题服务,从而执行降级方法,返回托底数据(其实就是通过服务降级的方式给你一个友好的提示,当然服务器还是挂了不能给你提供订单服务)。
Hystiix和Rabbion都是在服务内部提供的,Rabbion是为了省事,没有画那么多。
Ps:Eureka,Robbin,Hystrix都是SpringCloud技术栈中的组件。
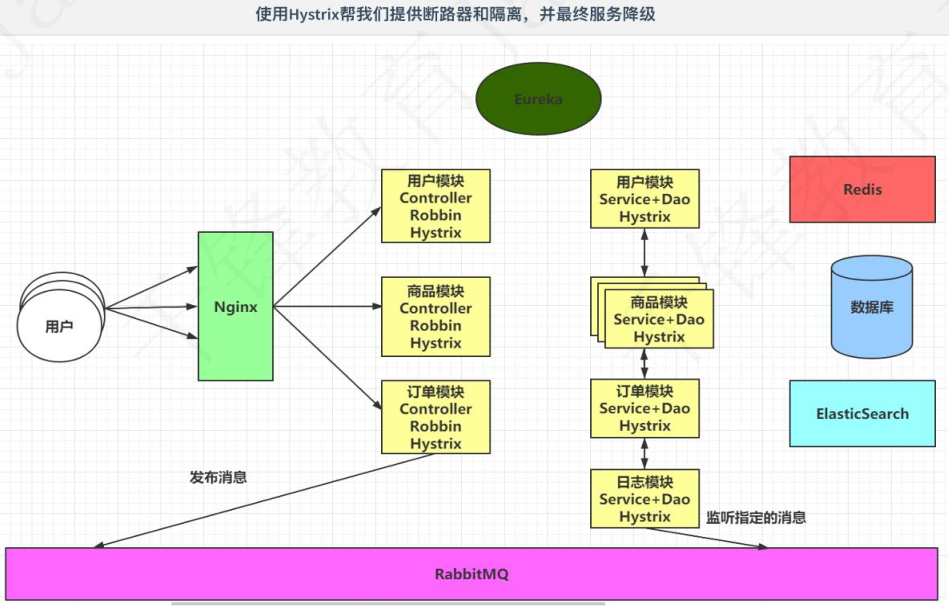
5.4 海量数据
海量数据会导致数据库无法存储全部的内容,即便数据库可以存储海量的数据,在查询数据时,数据库的响应是极其缓慢的,在用户高并发的情况下,数据库也是无法承受的。
为了解决上述的问题,可以基于MyCat实现数据库的分库分表(一个数据库不够,就多个)。
通过MyCat,在去访问数据库。
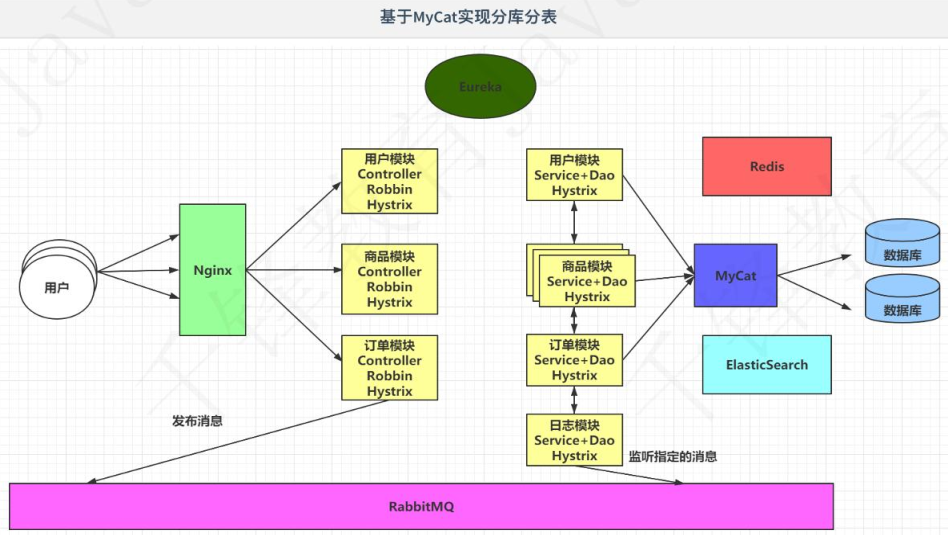
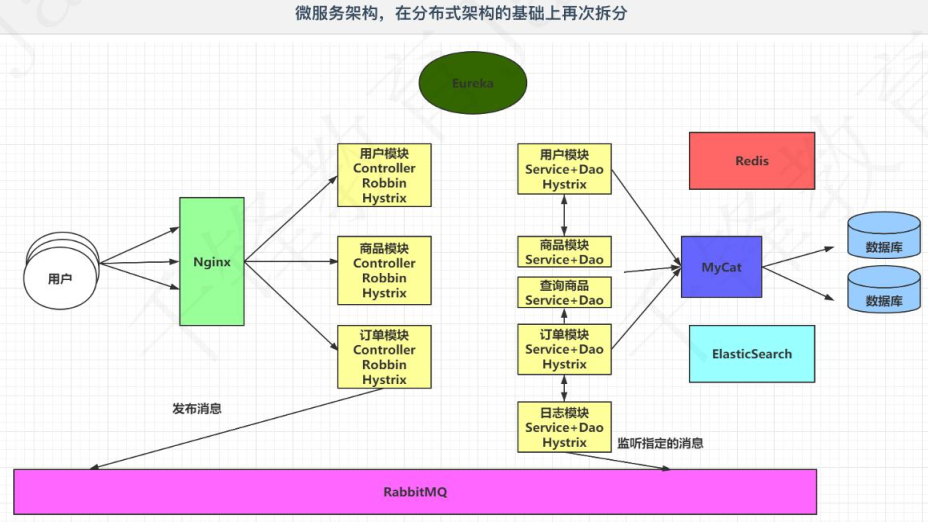
6. 微服务架构
6.1 微服务架构
虽然已经将每个模块独立的做开发,比如商品模块,压力最大的是商品的查询(而商品的增加、修改和删除可能访问量不大)。所有可以针对商品的查询做一个单独的项目。
在单独模块中再次拆分项目的方式就可以称之为微服务架构,微服务架构也是分布式架构,只是它可以将一个模块再拆,拆的更细,比如上面的,一个模块只做商品的查询。
注:下图中的商品模块Service+Dao和查询商品Service+Dao都属于商品模块,后者里面只是查询商品,前者里面放的是商品模块中除查询商品外的其它内容。
其实下图和上面的分布式架构变化不大,但是我们还要说一些其它内容。
6.2 模块过多,运维成本增加
我们发现上面的分布式架构、微服务架构模块非常多,这么多的内容部署到生产环境中,运维成本非常高。为了解决模块过多,运维程本增加的问题,需要采用一个技术去管理或者说是部署这些模块或者中间件,采用Docker容器化技术来帮助我们管理各个模块的部署,还可以通过CI、CD持续集成,持续交付,持续部署。
而且后期在学习的时候,也需要大量的软件(需要去linux中安装许多软件,时间长,安装可能失败等),可以使用Docker来帮助我们快速的安装软件。

6.3 分布式架构下的其它问题
分布式架构帮助我们解决了很多的问题,但是随之带来了很多问题。
- 分布式事务:最传统的操作事务的方式,是通过Connection链接对象的方式操作,Spring也提供了声明式事务的操作(本质也是Connection链接对象)。但是这样会有问题,比如商品Service+Dao模块访问数据库,但是要完成这个操作,需要调用下订单模块的Service+Dao,而这个模块也需要调用数据库,这时候我们希望这两个访问数据库的操作要么都成功,要么都失败。但是呢?这两个是不同的模块的,Connection对象肯定是不一样的;再比如商品Service+Dao模块访问数据库,总共访问了两次数据库,依次是访问上面的数据库一次是访问下面的,那也会出现这样的Connection链接对象不同,造成事务出现问题。为了解决事务的问题,后期会使用到RavvitMQ(前面说过)或者LCN等方式来解决。
- 分布式锁:锁在这种分布式架构中也是失效的,传统的锁方式,synchronized(基于对象)或者Lock锁(基于对象或者unsafe类下的puk方法)。无论是哪种锁,在分布式架构中,传统的锁是没有效果的。因此造成锁失效,为了解决锁失效问题,后续会使用到Redis或者Zookeeper来解决锁失效问题。
- 分布式任务:什么是分布式任务,这里就要说到传统定任务,在之前,咱们学另一个框架,叫corse,在一定的时间周期内,去执行某件事情,比如备份数据库这种操作。在传统的定时任务下,由于分布式环境的问题,可能会造成任务重复执行,一个比较大定任务,需要可以拆分。传统的用corse方式就比较麻烦,为了解决这个问题,后续会使用到Redis+Quartz或者是Elastic-Job。