题目内容要求:(1) 给出散列函数的具体应用。(2) 结合生日攻击、以及2004、2005年王晓云教授有关MD5安全性和2017年google公司SHA-1的安全性,说明散列函数的安全性以及目前安全散列函数的发展。问题2的回答可以参考下面给出的第一个链接。(3)结合md5算法中的选择前缀碰撞以及第二个链接中的helloworld.exe和goodbyworld.exe两个可执行文件的md5消息摘要值和两个文件的执行结果说明md5算法在验证软件完整性时可能出现的问题。
链接1:https://www.win.tue.nl/hashclash/
链接2:http://www.win.tue.nl/hashclash/SoftIntCodeSign/
1.散列函数的具体应用
在介绍散列函数前,我们先来了解一下散列函数的概念:一般的线性表,树中,记录在结构中的相对位置是随机的,即和记录的关键字之间不存在确定的关系,因此,在结构中查找记录时需进行一系列和关键字的比较。这一类查找方法建立在“比较“的基础上,查找的效率依赖于查找过程中所进行的比较次数。 理想的情况是能直接找到需要的记录,因此必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中一个唯一的存储位置相对应。
对于HASH函数的使用,有很多误区,在此特列举其使用场景以及常见的使用误区。但是不论如何,我们都该记得HASH函数的特点:固定长度的输出,单向不可逆,碰撞约束。
正确的应用场景:
1,数据校验
HASH函数有类似数据冗余校验类似的功能,但是它比简单的冗余校验碰撞的概率要小得多,顾而在现在密码学中总是用HASH来做关键数据的验证。
2,单向性的运用
利用HASH函数的这个特点,我们能够实现口令,密码等安全数据的安全存储。密码等很多关键数据我们需要在数据库中存储,但是在实际运用的过程中,只是作比较操作,顾而我们可以比较HASH结果。这一点相信在银行等系统中有所运用,否则我们真的要睡不着觉了:)
3,碰撞约束以及有限固定摘要长度
数字签名正是运用了这些特点来提高效率的。我们知道非对称加密算法速度较低,通过HASH处理我们可以使其仅仅作用于HASH摘要上,从而提高效率。
4,可以运用HASH到随机数的生成和密码,salt值等的衍生中
因为HASH算法能够最大限度的保证其唯一性,故而可以运用到关键数据的衍生中(从一个随机的种子数产生,并且不暴露种子本身秘密)。
2.散列函数的安全性以及目前安全散列函数的发展。
抗碰撞性:
强抗碰撞性:是指要找到散列值相同的两条不同的消息是非常困难的。
生日攻击(Birthday Attack):
生日悖论(Birthday paradox):
证明:
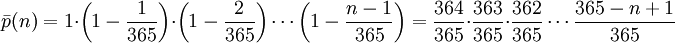

生日攻击原理:
步骤:
破解时间:

安全散列函数结构:
Merkle-Damgard结构:
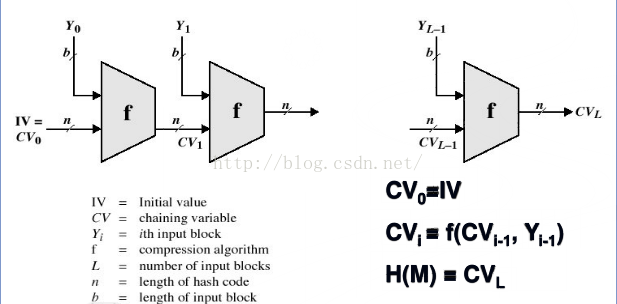
MD5是Message DigestAlgorithm MD5的缩写,中午名为消息摘要算法第5版。为计算机安全领域广泛使用的一种散列函数,用以提供消息的完整性保护。算法的文件号为RFC1321。其实在生活中也广泛见识过MD5,下载一个文件时,当下载完成之后要进行MD5校验,校验的目的就是去检测下载的文件有没有被篡改,哪怕是动了一个bit位,下载文件的内容生成的MD5校验值跟原文生成的MD5校验值差距是天大的,这取决于MD5校验值的生成算法。
MD5之前还有MD2、MD4由于在安全性上的原因,最终还是被MD5替换。MD5的用处主要有一下几个场景:
1、数据完整性校验
检查数据有没有被篡改过,这里取个例子。当用Android手机进行OTA升级的时候,下载完升级包(不管是全升包还是增量包),紧接着就是用该升级包的标准MD5进行验证,如果校验的结果等于标准的MD5值,那么就证明这个升级包没有被篡改过。
2、不可逆的加密
像Unix系统中,用户用用户名和密码登陆系统,由于系统中存放的是用户名和密码组合MD5校验值,所以登陆框将会把用户名和密码进行MD5算法从而生成用户名和密码组合的MD5校验值,系统由此可以知道能不能登陆成功。
MD5算法解析
MD5是以512位做为一个单位来处理原文,每一个512位又被分成16*32位来进行处理,直到所有原文都被处理一遍。
1、首先要对原文进行填充,保证数据长度是512个位的整数倍,填充方式如下:
(原文+ n + 64) %512 = 0
n:表示需要在原文后面添加多少位,一般添加1个1,或n和0
64:表示原文的长度
2、MD5算法中,需要初始链接变量,作为算法第一轮运算的基础,它作为MD5算法的初始值,可以想象,就算是同一段原文在进行MD5生成时,只要链接变量不一样,生成的MD5校验值也是不一样的。
针对这512位为一个分组的数据,处理方式是将它分成16*32位。从程序上来看,主循环有4轮,每一轮对这个16个数字进行处理,这里需要提到4个函数,每一次的处理都是通过这4个函数来完成的。当经过这些循环之后,会生成一个32位的MD5目标校验值。如果采用相同的初始链接变量和4个函数,那么对于同一段原文生成的MD5目标校验值是一样的,所以,MD5就能去检测数据的完整性和一致性。