一、雪花算法简介:
1、雪花算法是Twitter 开源的分布式、自增长 id 生成算法;
2、雪花算法生成的id是一个无符号长整型(unsigned long)的id,它占64个bit(8*8);
二、项目背景:
1、多台服务器组成的集群;
2、每台服务器同时启动多个worker;
3、每个worker使用雪花算法生成自增长id、再通过mycat进行批量入库。
三、需求分析:
1、自增长;
2、分布式;
显然,雪花算法很适合我们。
四、问题分析及解决方案:
1、Q:如何确保生成的id为正?
A:让id的第一个bit位固定为0。
2、Q:如何确保id自增?
A:使用毫秒级时间戳。
3、Q:如何确保集群中不同的机器上的生成id不重复?
A1:每台服务器有一个固定的机器id(hostid),这个能确保集群中不同的机器上的生成id不重复。
A2:给每台服务器配置一个id,用这个id代替hostid,这个能确保集群中不同的机器上的生成id不重复。
4、Q:如何确保同一台机器上不同的worker生成的id不重复?
A1:每个worker即一个进程(pid),可以取进程id来区别不同worker。
A2:将每个worker的pid映射成对应的workerid,并写入配置文件中。
5、Q:如何确保同一worker的同一毫秒内生成的id不重复?
A:增加序号来控制,如果时间相同则改变序号值。
通过上面的分析,我们可以确定雪花算法生成的id包括以下五部分:符号位、时间戳、hostid、workerid、序号
1)符号位,无意义;
2)时间戳,控制自增长;
3)hostid,控制不同机器生成不重复的id;
4)workerid,控制同一机器上不同进程生成不重复的id;
5)序号,控制同一机器上同一进程且同一时刻生成不重复的id;
五、bit资源分配方案:
1、符号位,固定1个bit;
2、时间戳,时间戳越大,我们能够使用的年限越多,36个bit大概可以使用两年多,41个bit大概可以使用69年。为了不吃官司,我们的时间戳应该控制在36~41位;
3、hostid,服务器自带的hostid占6个字节(48个bit),显然不能用它,所以我们需要给集群中的每一台服务器添加一个配置文件,每台服务器配置一个唯一的id作为hostid;
4、workerid,我们知道进程id一般最大为0x7fff,占15个bit,显然bit资源也不够分,所以我们需要将每个worker的pid映射成对应的workerid,并写入配置文件中;
6、序号,根据实际情况设置范围。
综上,我的分配方案如下:
1)符号位,1bit;
2)时间戳,41bit;
3)hostid,5bit(0~31);
4)workerid,5bit(0~31);
6)序号,12bit(0~4095)
该方案最多支持32台服务器的集群,每台服务器上最多同时启动32个worker(具体还得根据服务器资源分配)。
六、hostid和workerid的配置文件(Severcfg.xml):
1)Severcfg.xml
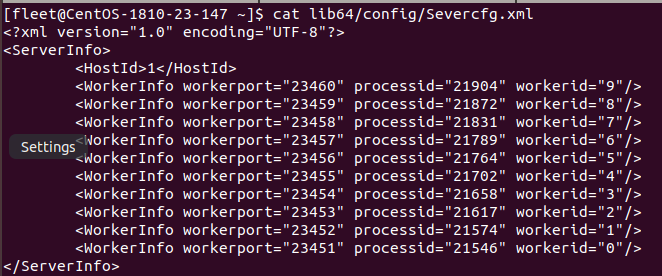
其中Hostid需要手动配置,集群中每台服务器的Hostid必须不一致;WorkerInfo是由worker启动脚本动态添加。
2)worker启动脚本:
#! /bin/bash
WORKER_DIR="/home/fleet/worker"
data_time=`date +'%Y-%m-%d'`
WORKER_NAME="/home/fleet/worker/worker.jar"
WORKER_PORT=23451
WORKER_COUNT=1
WORKER_LOG_PATH="/home/fleet/worker/logs"
SEVERCFG="/home/fleet/lib64/config/Severcfg.xml"
#判断worker所在路径是否为全路径
if [[ ! $WORKER_NAME =~ ^/.* ]];then
WORKER_NAME=$WORKER_DIR/$WORKER_NAME
fi
#判断日志路径是否为全路径
if [[ ! $WORKER_LOG_PATH =~ ^/.* ]];then
WORKER_LOG_PATH=$WORKER_DIR/$WORKER_LOG_PATH
fi
#判断worker是否存在
if [ ! -f $WORKER_NAME ];then
echo "$WORKER_NAME not exist!"
exit 1
fi
#如果日志路径不存在,创建之
if [ ! -d "$WORKER_LOG_PATH" ];then
echo "mkdir $WORKER_LOG_PATH"
mkdir $WORKER_LOG_PATH
fi
echo "WORKER_NAME:$WORKER_NAME, WORKER_PORT:<$WORKER_PORT~$[$WORKER_PORT+$[$WORKER_COUNT-1]]>, WORKER_COUNT:$WORKER_COUNT WORKER_LOG_PATH:$WORKER_LOG_PATH WORKER_DIR=$WORKER_DIR";
#start worker
cd $WORKER_DIR
source /home/fleet/.bashrc;
for ((i=0; i < $WORKER_COUNT; i++))
do
#根据判断端口是否被占用启动worker
pid=$(netstat -nlp | grep ":$WORKER_PORT" | awk '{print $7}' | awk -F"/" '{ print $1 }');
if [ ! -n "$pid" ]; then
WORKER_OUTFILE=$WORKER_LOG_PATH/worker$WORKER_PORT-$data_time.out
echo "About to start process<$WORKER_NAME>, port:$WORKER_PORT, log:$WORKER_OUTFILE";
nohup java -Xms1024m -Xmx1024m -XX:PermSize=256m -XX:MaxPermSize=512m -XX:MaxNewSize=512m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=$WORKER_DIR -jar -Dserver.port=$WORKER_PORT -Dmanagement.server.port=$WORKER_PORT $WORKER_NAME >> $WORKER_OUTFILE 2>&1 &
else
echo "WORKER_PORT:$WORKER_PORT already occupied";
fi
#将worker的进程id映射成0~31范围内的id,并写入配置文件中,注意进程id获取方式与上面不一样,因为启动worker架包有延时。。。
pid=$(ps -ef | grep $WORKER_NAME | grep "$WORKER_PORT" | grep -v grep | awk '{print $2}');
if [ -n "$pid" ] && [ -f $SEVERCFG ]; then
sed -i "/$WORKER_PORT/d" $SEVERCFG
sed -i '/HostId/a <WorkerInfo workerport="'$WORKER_PORT'" processid="'$pid'" workerid="'$i'"/>' $SEVERCFG
fi
WORKER_PORT=$[$WORKER_PORT+1];
done
ulimit -c unlimited;
ulimit -c;
该脚本的主要作用是:以某个端口为起始,启动多个worker,并将worker进程id映射成0~31范围内的id,写入配置文件中。
3)worker停止脚本
#! /bin/sh
#stop workerjar
WORKER_DIR=$(cd $(dirname $0); pwd)
WORKER_NAME="worker.jar"
CLEAR_WORKER_CRONTAB="$WORKER_DIR/clear-worker-crontab.sh"
SEVERCFG="/home/fleet/lib64/config/Severcfg.xml"
if [ $# -eq 1 ];then
WORKER_NAME=$1
else
if [ $# -gt 1 ];then
echo "Too many parameters"
exit 1
fi
fi
pid=`ps -aux |grep java | grep $WORKER_NAME | awk '{print $2}'`
if [ -n "$pid" ];then
kill -15 $pid
echo "kill worker process[$pid] success"
else
echo "not find worker process"
fi
#删除定时器
chmod 755 $CLEAR_WORKER_CRONTAB;
$CLEAR_WORKER_CRONTAB;
sed -i '/WorkerInfo/d' $SEVERCFG
4)其他脚本此处略,包括定时器等。有需要可以在下面评论区评论。
七、接下来要做的就简单了,读取配置文件中的Hostid,获取当前进程id和配置文件中的进程id做匹配,得到其对应的映射的workerid。
八、雪花算法的C++实现:
1、头文件Snowflake.h
/*
*
* 文件名称:Snowflake.h
* 文件标识:
* 摘 要:通过SnowFlake算法生成一个64位大小的分布式自增长id
*
*/
#ifndef __SNOWFLAKE_H__
#define __SNOWFLAKE_H__
#include <mutex>
#include <atomic>
//#define SNOWFLAKE_ID_WORKER_NO_LOCK
typedef unsigned int UInt;
typedef unsigned long UInt64;
#ifdef SNOWFLAKE_ID_WORKER_NO_LOCK
typedef std::atomic<UInt> AtomicUInt;
typedef std::atomic<UInt64> AtomicUInt64;
#else
typedef UInt AtomicUInt;
typedef UInt64 AtomicUInt64;
#endif
namespace service{
class Snowflake
{
public:
Snowflake(void);
~Snowflake(void);
void setHostId(UInt HostId)
{
m_HostId = HostId;
}
void setWorkerId(UInt workerId)
{
m_WorkerId = workerId;
}
UInt64 GetId()
{
return GetDistributedId();
}
private:
UInt64 GetTimeStamp();
UInt64 tilNextMillis(UInt64 lastTimestamp);
UInt64 GetDistributedId();
private:
#ifndef SNOWFLAKE_ID_WORKER_NO_LOCK
std::mutex mutex;
#endif
/**
* 开始时间截 (2019-09-30 00:00:00.000)
*/
const UInt64 twepoch = 1569772800000;
/**
* worker进程映射id所占的位数
*/
const UInt workerIdBits = 5;
/**
* 服务器id所占的位数
*/
const UInt hostIdBits = 5;
/**
* 序列所占的位数
*/
const UInt sequenceBits = 12;
/**
* worker进程映射ID向左移12位
*/
const UInt workerIdShift = sequenceBits;
/**
* 服务器id向左移17位
*/
const UInt hostIdShift = workerIdShift + workerIdBits;
/**
* 时间截向左移22位
*/
const UInt timestampLeftShift = hostIdShift + hostIdBits;
/**
* 支持的worker进程映射id,结果是31
*/
const UInt maxWorkerId = -1 ^ (-1 << workerIdBits);
/**
* 支持的服务器id,结果是31
*/
const UInt maxHostId = -1 ^ (-1 << hostIdBits);
/**
* 生成序列的掩码,这里为4095
*/
const UInt sequenceMask = -1 ^ (-1 << sequenceBits);
/**
* worker进程映射id(0~31)
*/
UInt m_WorkerId;
/**
* 服务器id(0~31)
*/
UInt m_HostId;
/**
* 毫秒内序列(0~4095)
*/
AtomicUInt sequence{ 0 };
/**
* 上次生成ID的时间截
*/
AtomicUInt64 lastTimestamp{ 0 };
};
}
#endif
2、实现代码Snowflake.cpp
#include "Snowflake.h"
#include <chrono>
#include <exception>
#include <sstream>
namespace service
{
Snowflake::Snowflake(void)
{
m_HostId = 0;
m_WorkerId = 0;
sequence = 0;
lastTimestamp = 0;
}
Snowflake::~Snowflake(void)
{
}
UInt64 Snowflake::GetTimeStamp()
{
auto t = std::chrono::time_point_cast<std::chrono::milliseconds>(std::chrono::high_resolution_clock::now());
return t.time_since_epoch().count();
}
UInt64 Snowflake::tilNextMillis(UInt64 lastTimestamp)
{
UInt64 timestamp = GetTimeStamp();
while (timestamp <= lastTimestamp) {
timestamp = GetTimeStamp();
}
return timestamp;
}
UInt64 Snowflake::GetDistributedId()
{
#ifndef SNOWFLAKE_ID_WORKER_NO_LOCK
std::unique_lock<std::mutex> lock{ mutex };
AtomicUInt64 timestamp{ 0 };
#else
static AtomicUInt64 timestamp{ 0 };
#endif
timestamp = GetTimeStamp();
// 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
std::ostringstream s;
s << "clock moved backwards. Refusing to generate id for " << lastTimestamp - timestamp << " milliseconds";
throw std::exception(std::runtime_error(s.str()));
}
if (lastTimestamp == timestamp) {
// 如果是同一时间生成的,则进行毫秒内序列
sequence = (sequence + 1) & sequenceMask;
if (0 == sequence) {
// 毫秒内序列溢出, 阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
else {
sequence = 0;
}
#ifndef SNOWFLAKE_ID_WORKER_NO_LOCK
lastTimestamp = timestamp;
#else
lastTimestamp = timestamp.load();
#endif
// 移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (m_HostId << hostIdShift)
| (m_WorkerId << workerIdShift)
| sequence;
}
}
