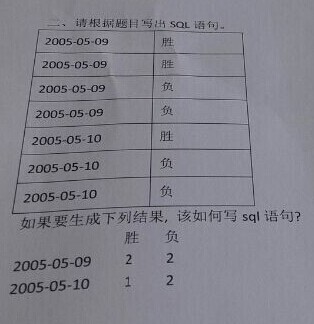
某天在某技术群看见有人发了这样一个图求助,一看就觉得这题考查的是利用sql行转列
我脑海第一时间就想到用oracle的decode函数来写,但又想到题目没有具体说是哪一种数据库~如果用decode的话,在mysql下是完全不一样的用法(也是因为这次我才知道mysql也有decode方法,但跟oracle的完全不一样,其他数据库暂没研究)
所以我就回复写了这样一个sql
初想的SQL¶
select t1.d,t1.c1 '胜',t2.c2 '负' from (select count(result) c1,d from t_result where result = '胜' group by d) t1 LEFT outer join (select count(result) c2,d from t_result where result = '负' group by d) t2 on t1.d = t2.d
这样的写法比较直观,就是先拿“胜”的出来,在拿“负”的出来,最后用日期关联起来
PS:这里的t_result是数据表,d是时间列,result是胜负结果列
后面我细想了一下,这样结果是出来的,但其实效率不高,因为两次select会导致两次表的扫描,因为之前研究过一下oracle,对这些还是比较敏感的,所以后面又改写了一下
(可能后面写的并不是最优,但起码比最初的有进步,性能有所提升,毕竟优化都是一步一步来的)
SELECT d,SUM(CASE WHEN result='胜' THEN 1 ELSE 0 END), SUM(CASE WHEN result='负' THEN 1 ELSE 0 END) FROM t_result GROUP BY d
这样扫面一次表就可以得出结果了
最后,再附上oralce的decode函数写法
SELECT d,SUM(decode(result,'胜',1,0)),SUM(decode(result,'负',1,0)) FROM t_result GROUP BY d