之前的一篇文章自编数据标注(分割)软件 之 数组嵌套实现哈希函数的数据分片应用介绍了如何显示数据点的活动标签。但是并不特别符合当前的需求,并无法达到动态修改每段数据的标签值,因为其中的labelNum是由slice获取得的,并且是从头到尾遍历进行的赋值操作,算法复杂度较高为O(n),即在每一次的分割点的加入都需要O(n)的时间复杂度。
这时便想到链表,原来没有考虑链表是因为感觉链表在做这种映射工作时的时间复杂度太高,但是可以通过工程的本身特点降低这种时间复杂度。
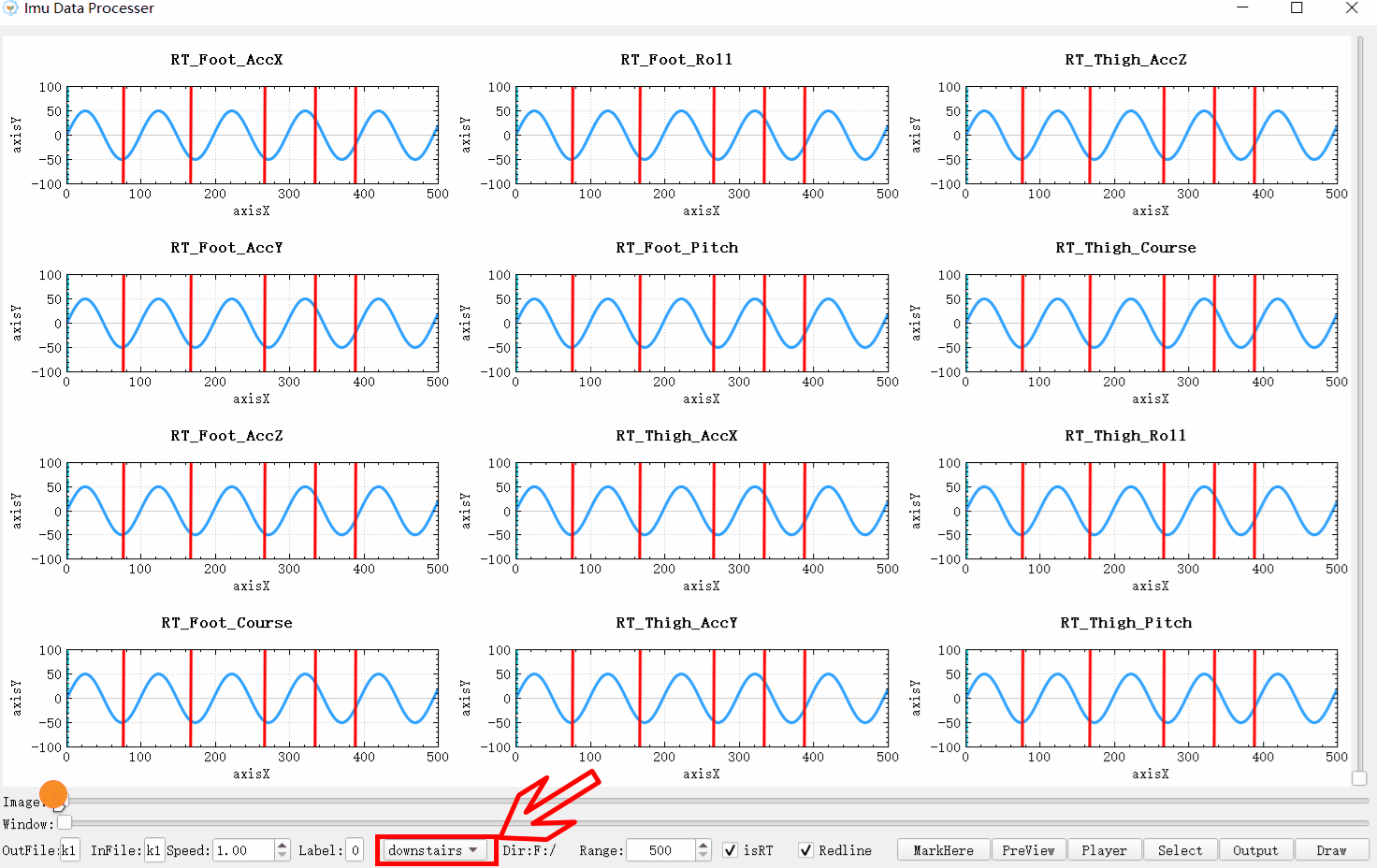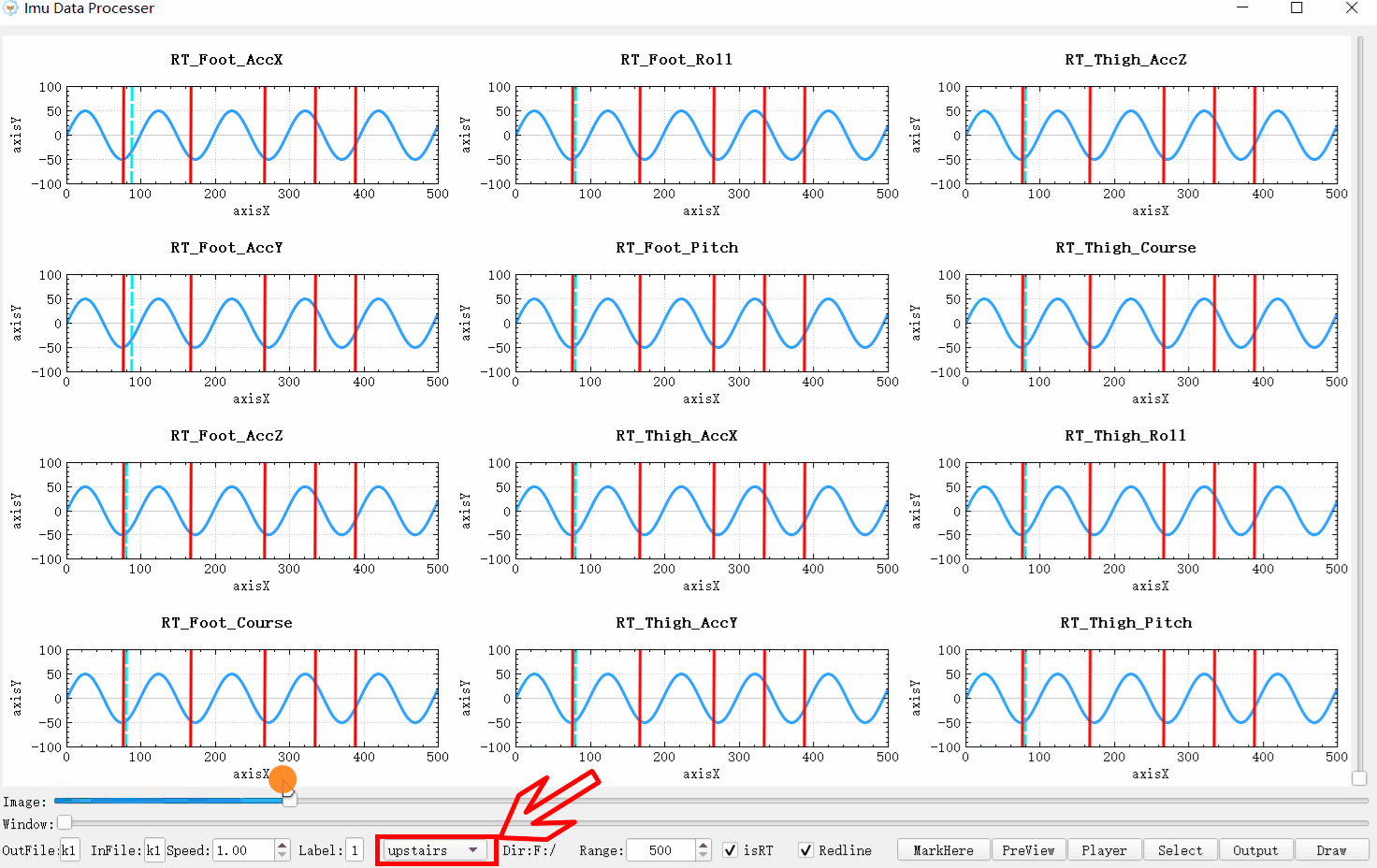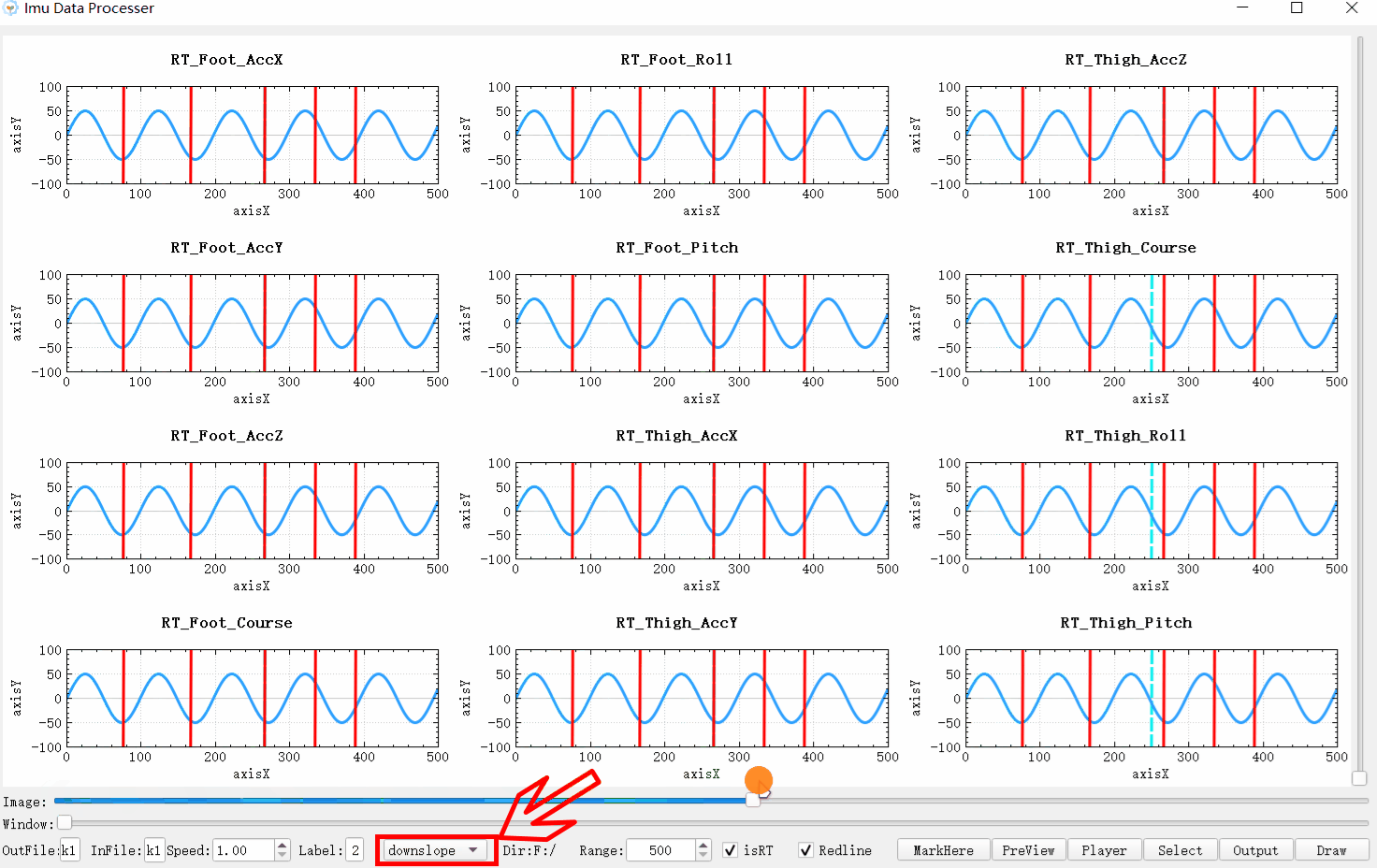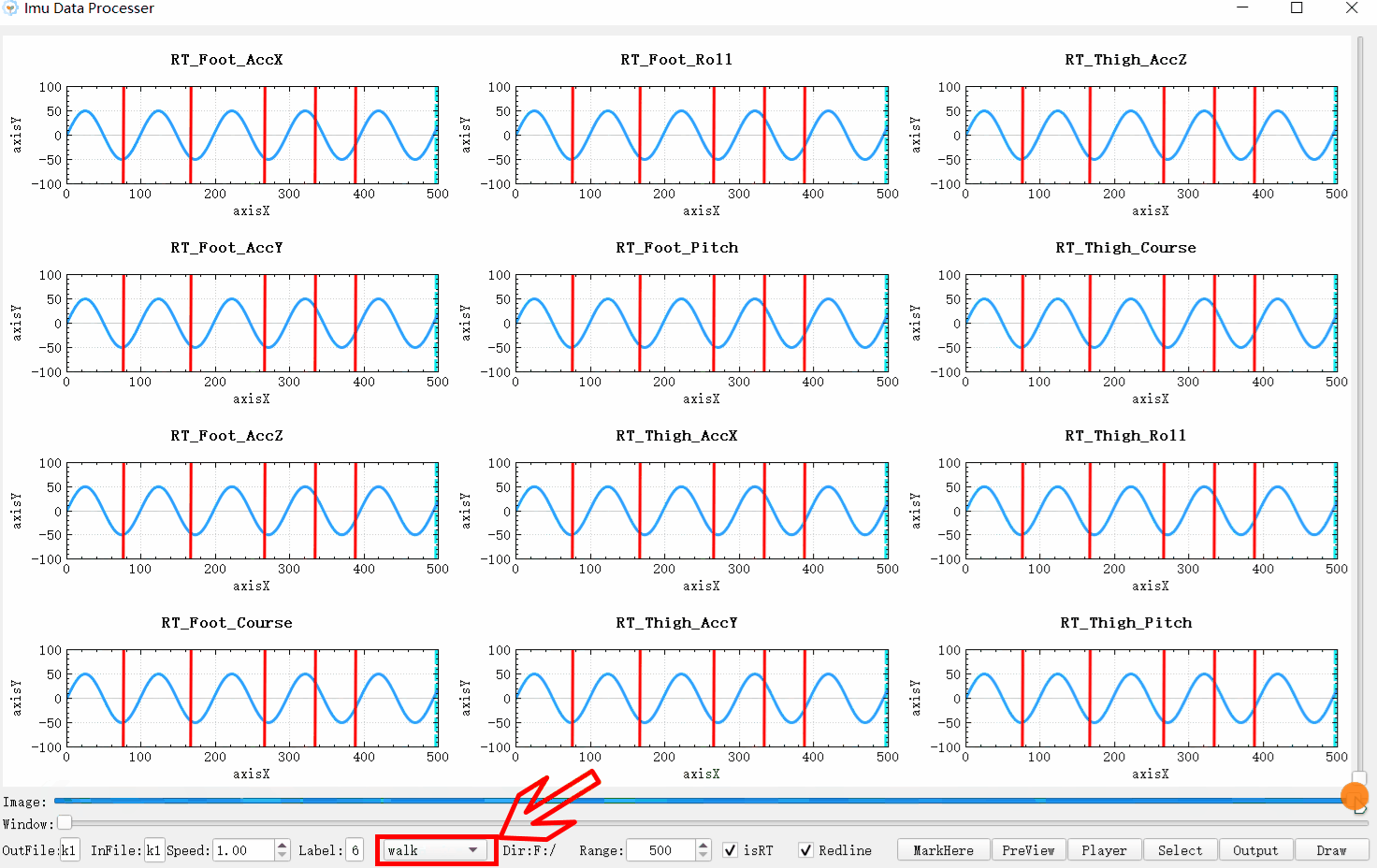
可以看效果图,因为标签的显示是一个数据接一个数据的显示,前后连续,这跟链表本身的存储方式十分类似,所以用于显示的话,假设这里有m个分割点,则链表本身所需的空间复杂度为O(m+1)。并且从前一个标签到后一个标签的切换的时间复杂度为O(1)。虽然时间复杂度和数组映射一样为O(1),但是每一次多了比较操作实际上时间消耗大了一倍。但是删除和插入操作的时间复杂度近乎为O(1)与数组的O(n)相比效率高了很多。
链表的运用
下面来看一下实现,这里使用的双线链表,因为移动方向不唯一,同时由于链表实现代码太长这里只介绍不同的地方:
class MarkPoint;
template<typename Item = int,typename Label = std::string>
class MarkList {
public:
/*双向链表的基本函数实现 end begin append push_back等*/
void initendPos(){
endPos = this->end();
}
MarkPoint * getCurrent(){
return endPos;
}
void setCurrentLabel(Label label){
this->endPos->prev()->setLabel(label);
}
bool delPos(int position){
auto start = endPos;
while(start!=trail && start->data() < position){
start = start->next();
}
while(start!=head && start->data() > position){
start = start->prev();
}
if(start==trail || start==this->begin() || start==this->end() || start==head) {
return false;
}
if(start->data()==position){
if(endPos==start)
endPos = start->next();
start->prev()->next() = start->next();
start->next()->prev() = start->prev();
delete start->release();
start = nullptr;
return true;
}else{
return false;
}
}
bool insertPos(int position,Label label){
auto start = endPos;
while(start!=trail && start->data() < position){
start = start->next();
}
while(start!=head && start->prev()->data() > position){
start = start->prev();
}
if(start==trail||start==this->begin()||start==head) return false;
MarkPoint *item = new MarkPoint(position,label);
item->next() = start;
item->prev() = start->prev();
item->prev()->next() = item;
item->next()->prev() = item;
return true;
}
bool isChangeTag(int position){
bool change = false;
while(endPos!=trail && endPos->data() < position){
endPos = endPos->next();
change = true;
}
while(endPos!=head && endPos->prev()->data() > position){
endPos = endPos->prev();
change = true;
}
return change;
}
int getTag(){
return endPos->prev()->label();
}
private:
MarkPoint * endPos;
}
这里的第一个不同点是当前节点的记录,也就是endPos:其代表了当前所在段的最后一个数据,也是当前数据段的前后分割点的后分割点,当然这个节点也就是当前显示的节点。这个节点的存在是分割点(节点)插入的关键,其实现了接近于O(1)的时间复杂度用于删除和插入,因为工程的需求,显示的分割点和插入的分割点之间相差的分割点个数小于全部分割点个数且接近于1,当然这个相差的个数也就是链表中节点的前后搜索个数。所以效率高很多。
在代码实现中insertPos和delPos操作的起始节点就是endPos,两个函数从endPos开始搜索,而节点的存储的value值是分割点的位置(数据的时间流的哈希值,从0到n递增)。同时链表类中的isChangeTag函数用以判断标签是否改变,并且维护了当前数据段的endPos,及当经过分割点时更改endPos,并且改变Label的显示(红框部分)。当然除了存储mark点的位置,同时也存储了该分割点之前一个数据段的标签值。
这篇博文就到这里了,有需要看不懂的同学可以留言。