从最简单的for循环说起
for( 初始化;条件; ){
}
条件为Trusy 值时候,可以继续执行for 循环,当条件变为Falsy 时跳出for循环。
for循环常见的四种写法
const persons = ['乔丹', '艾弗森', '邓肯', '科比', '麦迪', '奥尼尔']
// 方法一
for (let i = 0; i < persons.length; i++) {
console.log(persons[i])
}
// 方法二
for (let i = 0, len = persons.length; i < len; i++) {
console.log(persons[i])
}
// 方法三
for (let i = 0, person; person = persons[i]; i++) {
console.log(person)
}
// 方法四
for (let i = persons.length; i--;) {
console.log(persons[i])
}
第一种方法是最常见的方式,不解释。
第二种方法是将persons.length缓存到变量len中,这样每次循环时就不会再读取数组的长度。
第三种方式是将取值与判断合并,通过不停的枚举每一项来循环,直到枚举到空值则循环结束。执行顺序是:
第一步:先声明索引i = 0和变量person
第二步:取出数组的第i项persons[i]赋值给变量person并判断是否为Truthy(备注:Truthy,是指判断可为true的值,例如,1,true,”s“, [1],{age:9}, Falsy, 是指 0, false ,”“, undefined, null, [], 但是{} 不是Falsy值)
第三步:执行循环体,打印person
第四步:i++。
当第二步中person的值不再是Truthy时,循环结束。方法三甚至可以这样写
for (let i = 0, person; person = persons[i++];) {
console.log(person)
}
第四种方法是倒序循环。执行的顺序是:
第一步:获取数组长度,赋值给变量i
第二步:判断i是否大于0并执行i--
第三步:执行循环体,打印persons[i],此时的i已经-1了
从后向前,直到i === 0为止。这种方式不仅去除了每次循环中读取数组长度的操作,而且只创建了一个变量i。
四种for循环方式在数组浅拷贝中的性能和速度测试
先造一个足够长的数组作为要拷贝的目标(如果`i`值过大,到亿级左右,可能会抛出JS堆栈跟踪的报错)
const ARR_SIZE = 6666666
const hugeArr = new Array(ARR_SIZE).fill(1)
然后分别用四种循环方式,把数组中的每一项取出,并添加到一个空数组中,也就是一次数组的浅拷贝。并通过[console.time](https://developer.mozilla.org/en-US/docs/Web/API/Console/time)和[console.timeEnd](https://developer.mozilla.org/en-US/docs/Web/API/Console/timeEnd)记录每种循环方式的整体执行时间。通过[process.memoryUsage()](http://www.ruanyifeng.com/blog/2017/04/memory-leak.html)比对执行前后内存中已用到的堆的差值。
/* node环境下记录方法执行前后内存中已用到的堆的差值 */
function heapRecord(fun) {
if (process) {
const startHeap = process.memoryUsage().heapUsed
fun()
const endHeap = process.memoryUsage().heapUsed
const heapDiff = endHeap - startHeap
console.log('已用到的堆的差值: ', heapDiff)
} else {
fun()
}
}
// 方法一,普通for循环
function method1() {
var arrCopy = []
console.time('method1')
for (let i = 0; i < hugeArr.length; i++) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method1')
}
// 方法二,缓存长度
function method2() {
var arrCopy = []
console.time('method2')
for (let i = 0, len = hugeArr.length; i < len; i++) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method2')
}
// 方法三,取值和判断合并
function method3() {
var arrCopy = []
console.time('method3')
for (let i = 0, item; item = hugeArr[i]; i++) {
arrCopy.push(item)
}
console.timeEnd('method3')
}
// 方法四,i--与判断合并,倒序迭代
function method4() {
var arrCopy = []
console.time('method4')
for (let i = hugeArr.length; i--;) {
arrCopy.push(hugeArr[i])
}
console.timeEnd('method4')
}
分别调用上述方法,每个方法重复执行12次,去除一个最大值和一个最小值,求平均值(四舍五入),最终每个方法执行时间的结果如下表(测试机器:`MacBook Pro (15-inch, 2017) 处理器:2.8 GHz Intel Core i7 内存:16 GB 2133 MHz LPDDR3` 执行环境:`node v10.8.0`):
- 方法一 方法二 方法三 方法四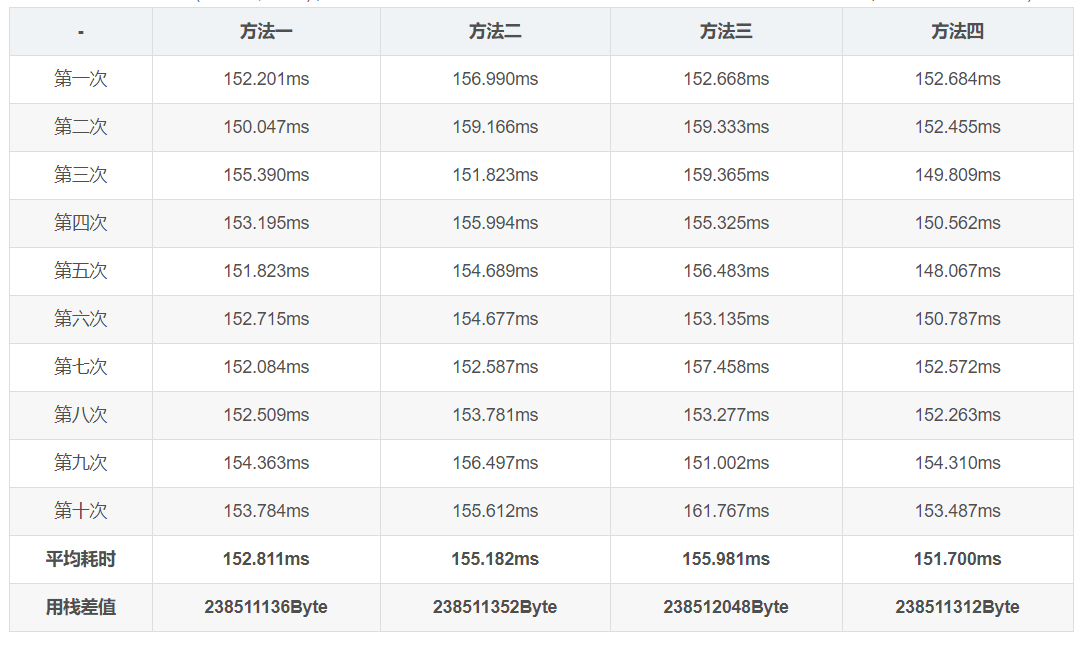
小结
在`node`下执行完成同一个数组的浅拷贝任务,耗时方面四种方法的差距微乎其微,有时候排序甚至略有波动。
考虑到在不同环境或浏览器下的性能和效率: `推荐`:第四种`i–`倒序循环的方式。`不推荐`:第三种方式。主要是因为当数组里存在非`Truthy`的值时,比如`0`和`”`,会导致循环直接结束。
while循环以及ES6+的新语法forEach、map和for of,会更快吗?
不啰嗦,实践是检验真理的唯一标准
// 方法五,while
function method5() {
var arrCopy = []
console.time('method5')
let i = 0
while (i < hugeArr.length) {
arrCopy.push(hugeArr[i++])
}
console.timeEnd('method5')
}
// 方法六,forEach
function method6() {
var arrCopy = []
console.time('method6')
hugeArr.forEach((item) => {
arrCopy.push(item)
})
console.timeEnd('method6')
}
// 方法七,map
function method7() {
var arrCopy = []
console.time('method7')
arrCopy = hugeArr.map(item => item)
console.timeEnd('method7')
}
}
// 方法八,for of
function method8() {
var arrCopy = []
console.time('method8')
for (let item of hugeArr) {
arrCopy.push(item)
}
console.timeEnd('method8')
}
测试方法同上,测试结果: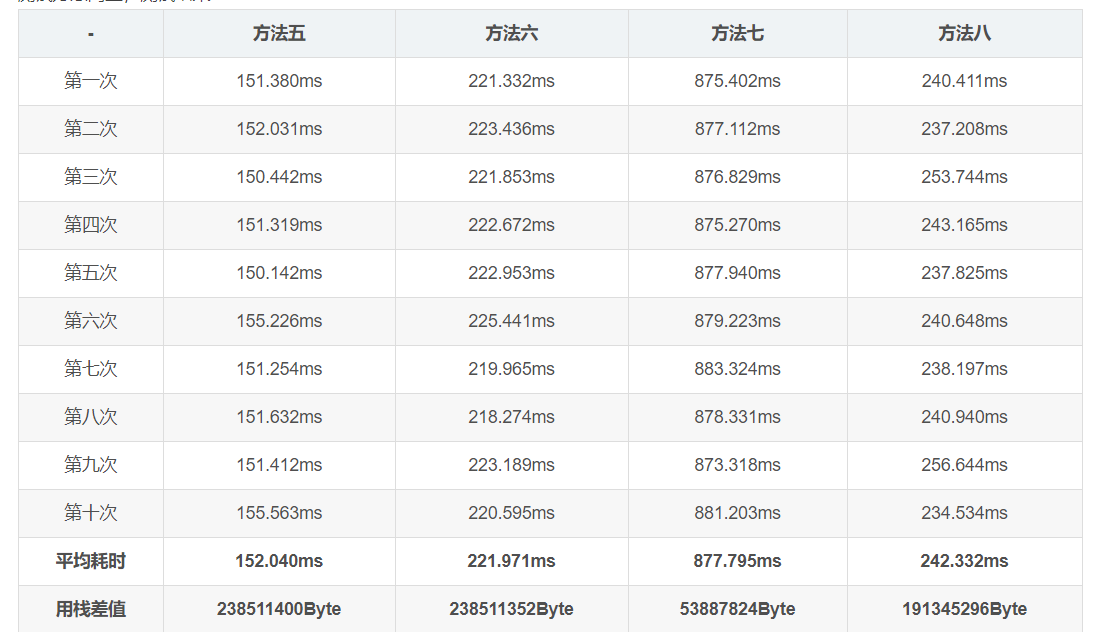
在`node`下,由上面的数据可以很明显的看出,`forEach`、`map`和`for of` 这些`ES6+`的语法并没有传统的`for`循环或者`while`循环快,特别是`map`方法。但是由于`map`有返回值,无需额外调用新数组的`push`方法,所以在执行浅拷贝任务上,内存占用很低。而`for of`语法在内存占用上也有一定的优势。
但是随着执行环境和浏览器的不同,这些语法在执行速度上也会出现偏差甚至反转的情况,直接看图: `谷歌浏览器` `火狐浏览器` `safari浏览器下` 可以看出:
谷歌浏览器中ES6+的循环语法会普遍比传统的循环语法慢,但是火狐和safari中情况却几乎相反。
谷歌浏览器的各种循环语法的执行耗时上差距并不大。但map特殊,速度明显比其他几种语法慢,而在火狐和safari中却出现了反转,map反而比较快!
顺便提一下:`for循环 while循环 for of 循环`是可以通过`break`关键字跳出的,而`forEach map`这种循环是无法跳出的。
总结
之前有听到过诸如“缓存数组长度可以提高循环效率”或者“ES6的循环语法更高效”的说法。抛开业务场景和使用便利性,单纯谈性能和效率是没有意义的。 ES6新增的诸多数组的方法确实极大的方便了前端开发,使得以往复杂或者冗长的代码,可以变得易读而且精炼,而好的for循环写法,在大数据量的情况下,确实也有着更好的兼容和多环境运行表现。当然本文的讨论也只是基于观察的一种总结,并没有深入底层。而随着浏览器的更新,这些方法的孰优孰劣也可能成为玄学。目前发现在Chrome Canary 70.0.3513.0下for of 会明显比Chrome 68.0.3440.84快。
本文的测试环境:node v10.8.0、Chrome 68.0.3440.84、Safari 11.1.2 (13605.3.8)、Firefox 60.0
原文:https://blog.csdn.net/haochuan9421/article/details/81414532