awk:报告生成器,格式化文本输出。
我们一般使用的awk命令其实就是gawk,在centos7系统下,awk是gawk的链接文件。
基本用法:gawk [options] 'program' FILE .......
program:PATTERN{ACTION STATEMENTS}
STATEMENTS语句之间使用分号隔开。
ACTION:print,printf
options:-F:文本字段分隔符。
-v:var=value,自定义变量。
1、print
print item1,item2,item3...........
要点:
1、使用逗号来分隔各个item等,而输出时的分隔符默认为空格字符。
2、输出的item可以是字符串,也可以是数值,当前记录的字段,变量或者awk的表达式。
3、如省略item,相当于print $0;
演示:


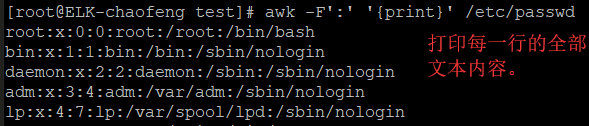
2、变量,需要指定参数:-v
2.1、内建变量
FS:input Field Seperator:输入字段分隔符,默认为空白字符。
如:-v FS=“[,:;]”,
OFS:output Field Seperator:输出字段分隔符,默认为空白字符。
演示:



RS:input Record Seperator:输入时的行分隔符,默认是换行符。
ORS:output Record Seperator:输出时的行分隔符,默认时换行符。
演示:
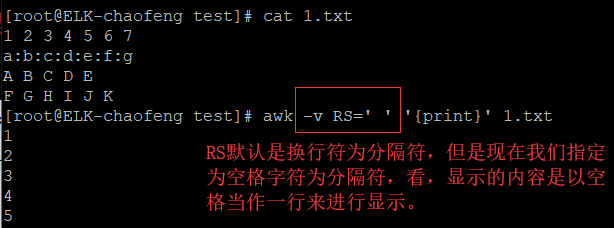
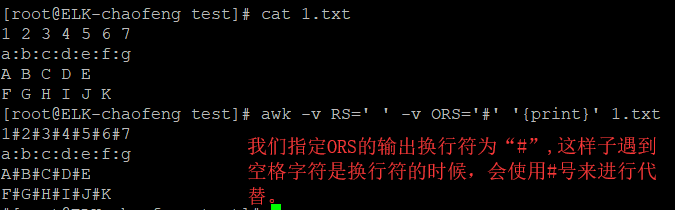
所以说RS与ORS一起使用可以达到替换字符的目的。
还有一个需要注意的:
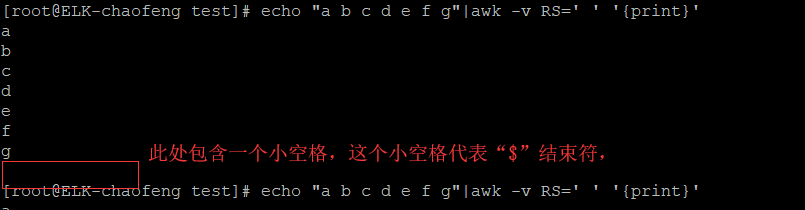
NF:显示当前行的字段数。以行为单位进行显示。
print NF:显示当前行的字段数。、
print $NF:引用当前行的第NF字段的值。
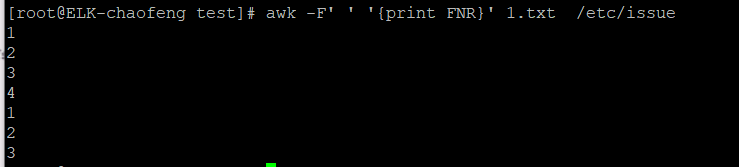
NR:行数,命令后跟的所有文件将统一合并行数
FNR:行数,每个文件单独计算行数。
演示:



这个命令就跟下面这个命令很相似:

拓展:
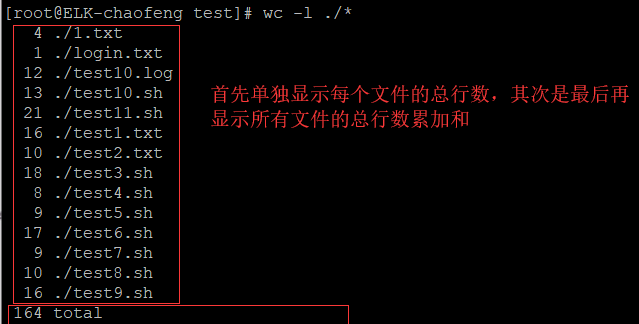
FILENAME:当前正被awk读取的文件的文件名;
ARGC:awk命令中的参数的个数。
ARGV:数组,保存了命令行参数本身。
ARGV[index]
ARGV[0],ARGV[1]
2.2、自定义变量
-v VAR_NAME=VALUE,变量名区分字符大小写。
演示:

这里的文件/etc/issue的内容没有什么用,只是用来标识文件有多少行,就显示多少个变量值。
3、printf命令
格式化输出:printf FORMAT,item1,item2........
(1):FORMAT必须给出。
(2):不会字段换行,需要显式给出换行控制符,
(3):FORMAT中需要分别为后面的每个item指定一个格式化符号,否则item无法显示。
格式符:
%c:显示单个字符
%d或%i:显示十进制整数。
%e:科学计数法显示数值
%f:显示浮点数
%s:显示字符串。
演示:

修饰符:
#[.#]:
左边的#:用于指定显示的宽度。
右边的#:显示精度。
+:显示数值的符号
-:左对齐显示。
演示:

4、操作符
算数操作符:
x+y,x-y,x*y,x/y,x^y,x%y
-x
+x:转换为数值。
字符串操作符:没有符号的操作符,字符串连接。
赋值操作符:
=,+=,-+,*=,/=,%=,^=
++,--
比较操作符:
>,>=,<,<=,!=,==
模式匹配符:
~:左侧是否能由右侧指定的模式所匹配。
!=:左侧是否不能由右侧指定的模式所匹配。
逻辑操作符:
&&
||
!
函数调用:
function_name(argu1,argu2,.......)
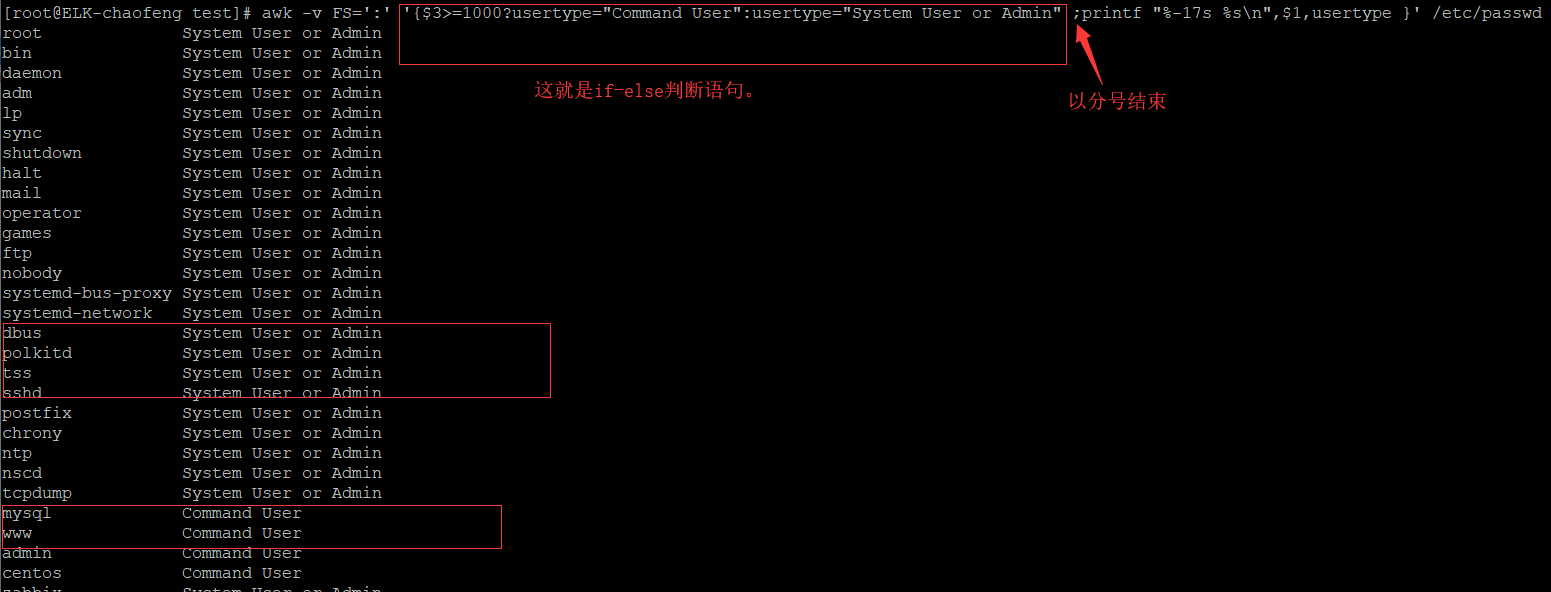
条件表达式:
selector?if-true-expression:if-false-expression
演示:
5、PATTERN
5.1、empty:空模式,匹配每一行;
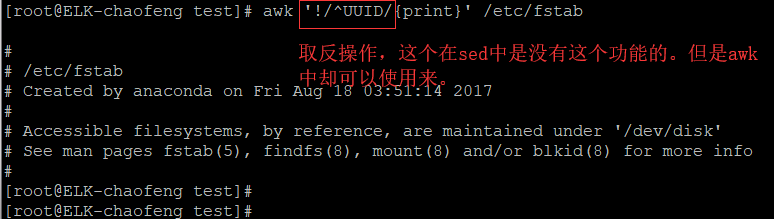
5.2、/regular expression/:仅处理能被regular expression匹配到的行。
演示:

5.3、relational expression:关系(比较)表达式,结果有“真”有“假”,但结果为“真”才能被awk处理。对于此处的关系表达式来讲,其结果为非0数值或非空字符串即为“真”。


用模式匹配的方法来做

5.4、line range:行范围。
/pat1/,/pat2/ 从pat1被匹配到的那一行开始到pat2的那一行结束之间所有的行。
注意:不支持像sed命令那样直接给出数字的格式。
演示:


NR表示统计的文件的行数,他会从1开始显示,符合要求的打印出来。
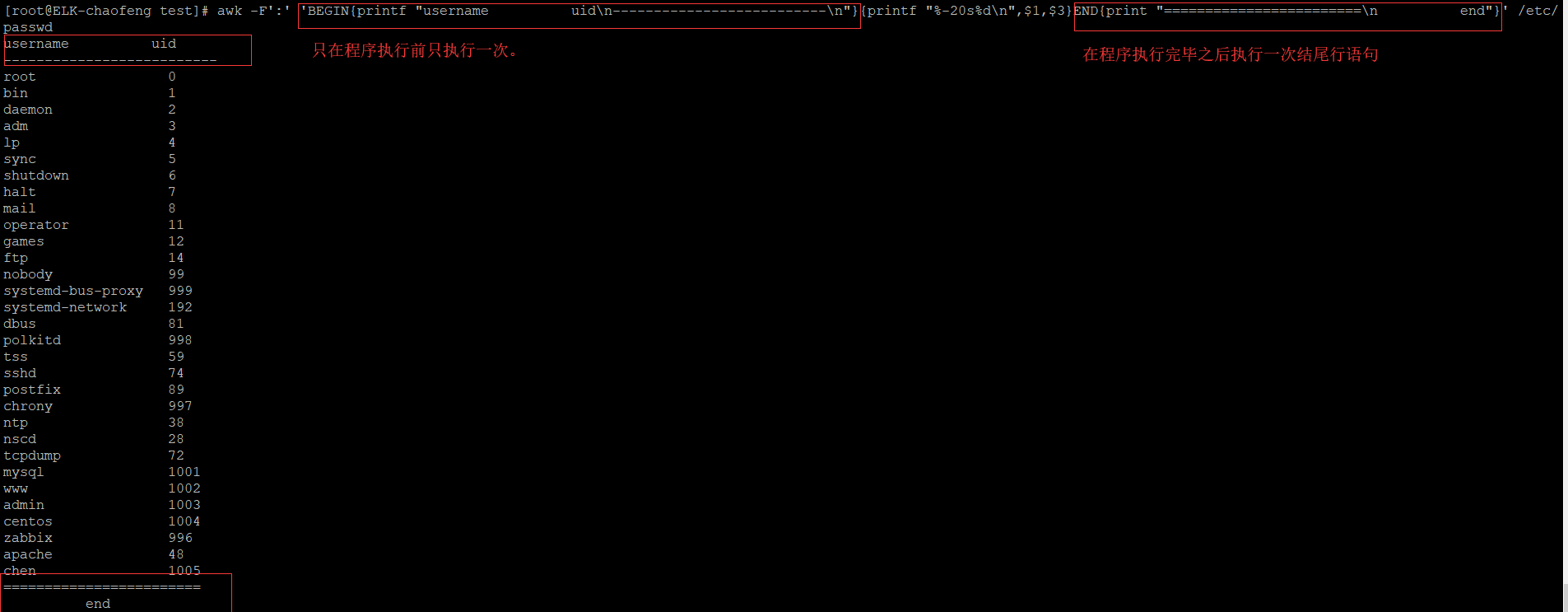
5.5、BEGIN/END模式
BEGIN:在文件格式化操作开始之前事先执行的一次操作,通常用于输出表头或做出一个初始化的操作。
END:在文件格式操作完成之后,命令推出之前执行的一次操作。通常用于输出表尾或做出清理操作。
演示:
6、常用的action
6.1、Expressions
6.2、Control statements:if,while等。
6.3、Compound statements:组合语句;
6.4、input statements
6.5、output statements
7、控制语句
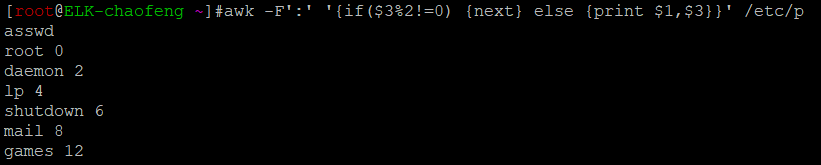
7.1、对awk取得的整行或某个字段做条件判断。
if(condition) {statements}
if(condition) {statements} [else {statements}]


判断哪个磁盘的使用量的百分比大于等于17%,然后将其输出并输出其使用率

7.2、while循环
语法:while(condition) {statements}
条件为“真”,进入循环,条件为“假”,退出循环。
使用场景:
1、对一行内的多个字段逐一类似处理时使用
2、对数组中的每个元素逐一处理
补充:length(var):取出var变量的字符串的长度。
显示/etc/fstab中以UUID开头的行,以空格分隔,显示每个item的字符串的长度。

现在再加上一个功能,只显示item的长度大于5的item

这个while循环中再加上一个if循环,其实使用的就是C语言的方式来写的。学习好C语言,就能看懂语法了。
7.3、do...while循环
语法:do {statements} while(condition)
作用:至少执行一次循环体
7.4、for循环,
语法:for(expr1;expr2;expr3) {statements}
特殊用法:for (var_name in array_name) {statements}
演示:

7.5、switch语句
语法:switch(expression) {case VALUE1 or /REGEXP/: statement; case VALUE2 or /REGEXP2/: statement; ......; default: statement}
7.6、break和continue
7.7、next
作用:提前结束对本行的处理,进入下一轮操作
演示:
7.8、array数组
关联数组:array[index-expression]
index-expression:
(1):可使用任意字符串,字符串要使用双引号。
(2):如果某数组元素事先不存在,在引用时,awk会自动创建此元素,并将其初始化为“空串”;
注意:若要判断数组中是否存某元素,要使用“index in array”格式进行。
注意:var会遍历array的每个索引。
几个常用的函数:
数组长度:length(array)
判断元素是否存在:if(key in array){ … }
删除元素:delete array[key]
删除数组:delete array
(3)定义数组元素本身就是索引。
可定义一个数组,用单词本身当索引,而元素的值存储单词出现的次数。
比如:ARRAY[array_name1]++、ARRAY[array_name2]++,表示的意思是数组中的某个元素的个数自增。这个可以用在统计网站访问数量,而array_name1、array_name2则表示元素的值,并非是索引。


这个例子中,i 保存的是数组中的索引,最后那个“print weekdays[i]”是C语言中的写法,注意这个 i 一定不能加上$符号,i 自己表示索引号。这是C语言的写法。只有在C语言中引用bash的变量,需要加上$符号,比如引用print $NF的值等。var会遍历array的每个索引。
数组元素本身当索引,而元素的值存储单词的次数。(重点,要学会)
统计tcp连接中各个状态的连接个数

统计网站的访问IP次数最多的前几个

统计一个文本文件中出现的单词的次数:
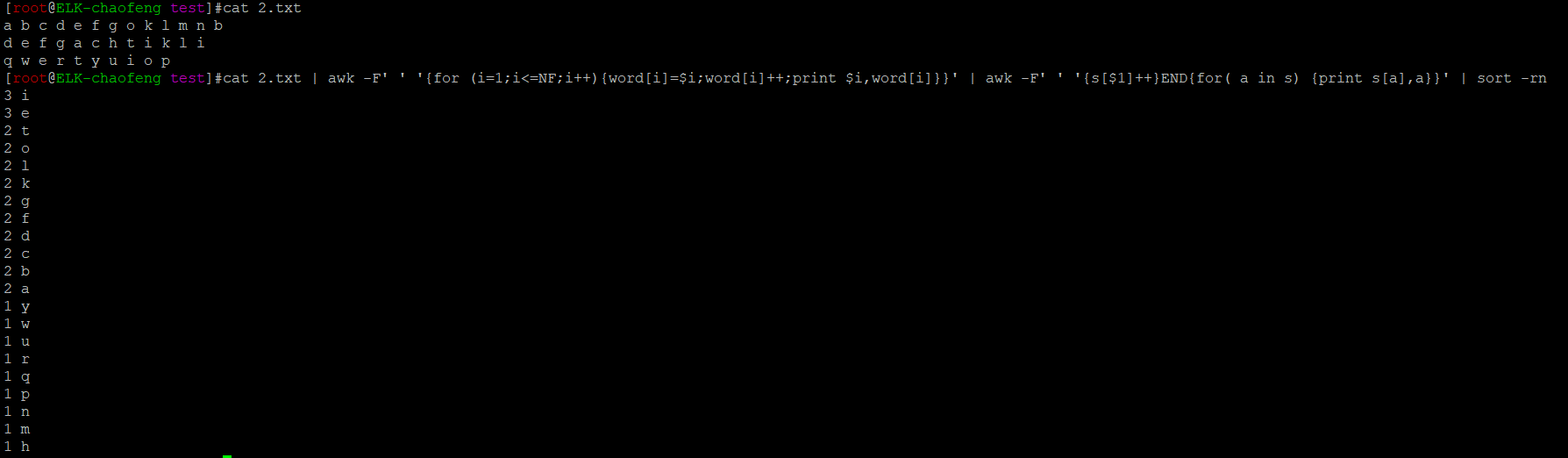
第二种方法:

9、函数
9.1、内置函数
数值处理:
rand():返回0和1一个随机数
字符串处理:
length([s]):返回指定字符串的长度。
sub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其第一次出现替换为s所表示的内容。
gsub(r,s,[t]):以r表示的模式来查找t所表示的字符中的匹配的内容,并将其所有出现均替换为s所表示的内容
split(s,a[,r]):以r为分隔符切割字符s,并将切割后的结果保存至a所表示的数组中:
统计本机tcp连接中连接本主机的IP个数

9.2、自定义函数,不讲解,自己研究。