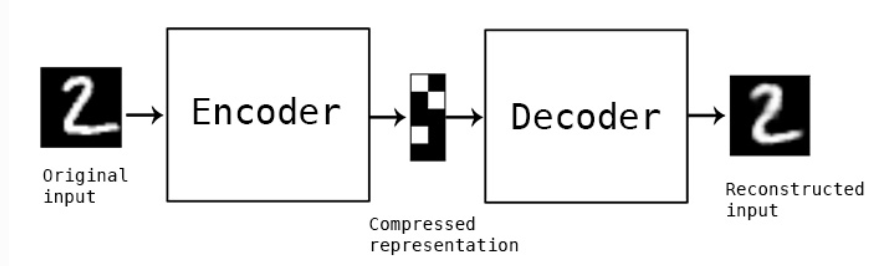
自编码器是指使用自身的高阶特征编码自己。
自编码器是一种神经网络,它的输出和输入是一致的,目标是使用稀疏的高阶特征重新组合来重构自己。
自动编码器是一种数据的压缩算法,其中数据的压缩和解压缩函数是数据相关的、有损的、从样本中自动学习的,在大部分提到自动编码器的场合,压缩和解压缩的函数是通过神经网络实现的。
自编码器特点:
1.自动编码是数据相关的,这意味着自动编码器只能压缩那些与训练数据类似的数据。
2.自动编码器是有损的,与无损压缩算法不同。
3.自动编码器是从数据样本中自动学习的。
自编码器的设计:
1.搭建编码器,把原图像编译成一个向量
2.搭建解码器,接收一个向量去生成一个图片
3.设定损失函数,我们希望输入的图片和生成的图片越接近越好,设定一个损失值表示差距。
自编码器的应用:
1.数据去噪,把一张有噪声的图片输入到神经网络,让神经网络去记住这张图片的高阶特征,在压缩的时候把高阶特征提取出来,再去生成这张图片本身,实现去噪。
2.降维,把一张图片降为一张低纬度的向量。
3.图像生成,给定一个向量去生成一张图片。
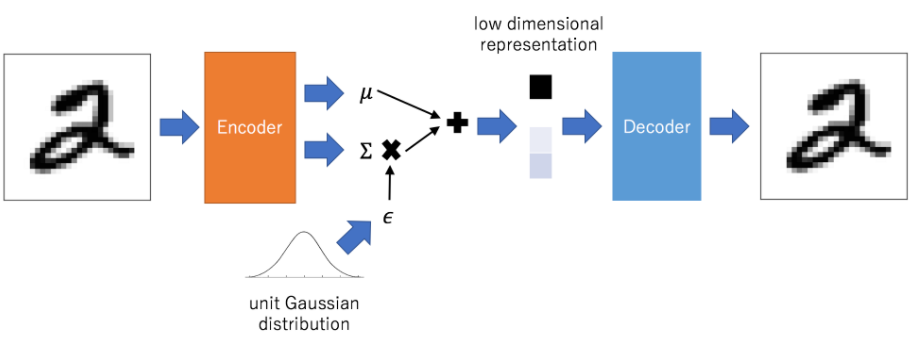
变分自编码器(VAE)
变分自编码器可以随机生成隐含变量,提高网络的泛化能力,比普通的自动编码器要好,缺点就是生成的图片会有点模糊。
实例1.基本自编码器
编译环境:tensorflow 2.0、python3.6.12
首先读取数据集,选用常用的手写数据集MNIST。
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt (x_train,_),(x_test,_) = tf.keras.datasets.mnist.load_data()
对训练和测试图片进行reshape何正规化操作
#自编码器的数据相似性,我们用来测试的数据仍是手写数字 print(x_train.shape) #(60000, 28, 28) print(x_test.shape) #(10000, 28, 28) x_train = x_train.reshape(x_train.shape[0],-1) x_test = x_test.reshape(x_test.shape[0],-1) x_train = tf.cast(x_train,tf.float32) /255 x_test = tf.cast(x_test,tf.float32) /255 print(x_train.shape) #(60000, 784) print(x_test.shape) #(10000, 784)
添加输入层、隐藏层、输出层的大小
input_size = 784 hidden_size = 32 output_size = 784
编写自编码器的模型
#编写自编码器模型 input = tf.keras.layers.Input(shape=(input_size,)) #encode en = tf.keras.layers.Dense(hidden_size,activation='relu')(input) #decode de = tf.keras.layers.Dense(output_size,activation='sigmoid')(en) model = tf.keras.Model(inputs=input,outputs=de) model.summary() #模型编译 model.compile(optimizer='adam', loss='mse')
编译、训练和绘出损失图
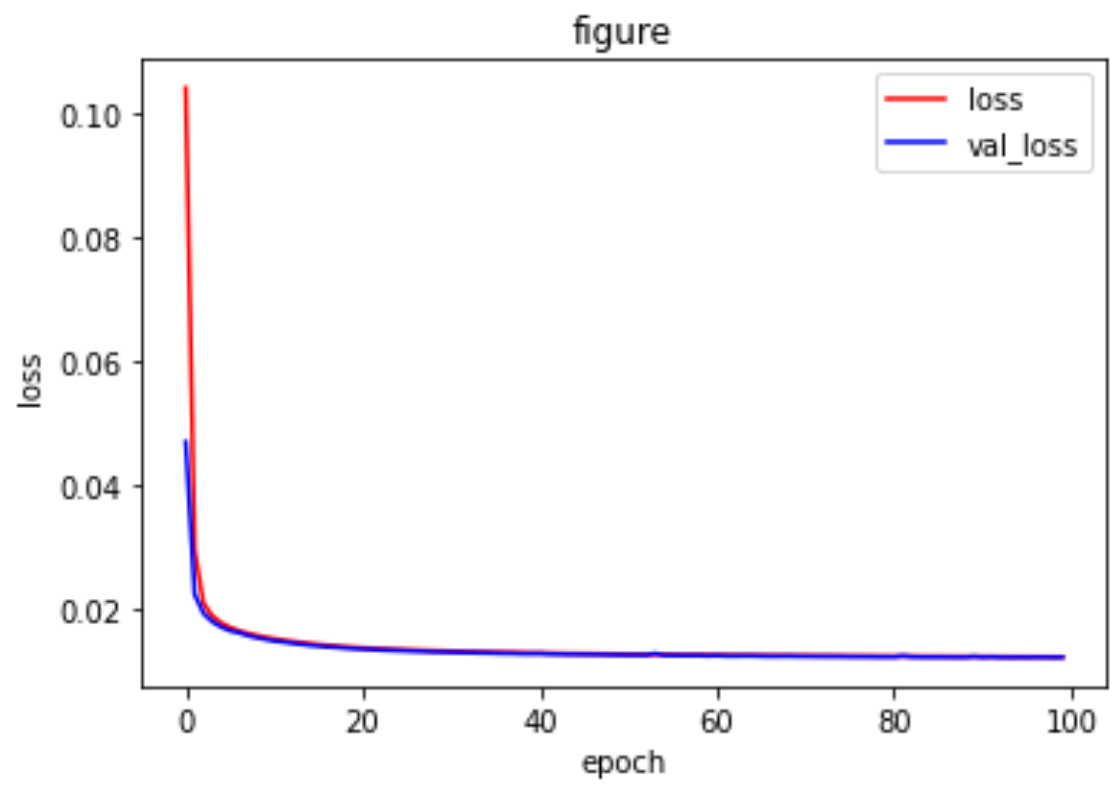
#train history = model.fit(x_train, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test,x_test)) print(history.history) loss = history.history['loss'] val_loss = history.history['val_loss'] plt.plot(history.epoch,loss,'r',label='loss') plt.plot(history.epoch,val_loss,'b',label='val_loss') plt.xlabel('epoch') plt.ylabel('loss') plt.title('figure') plt.legend() plt.show()
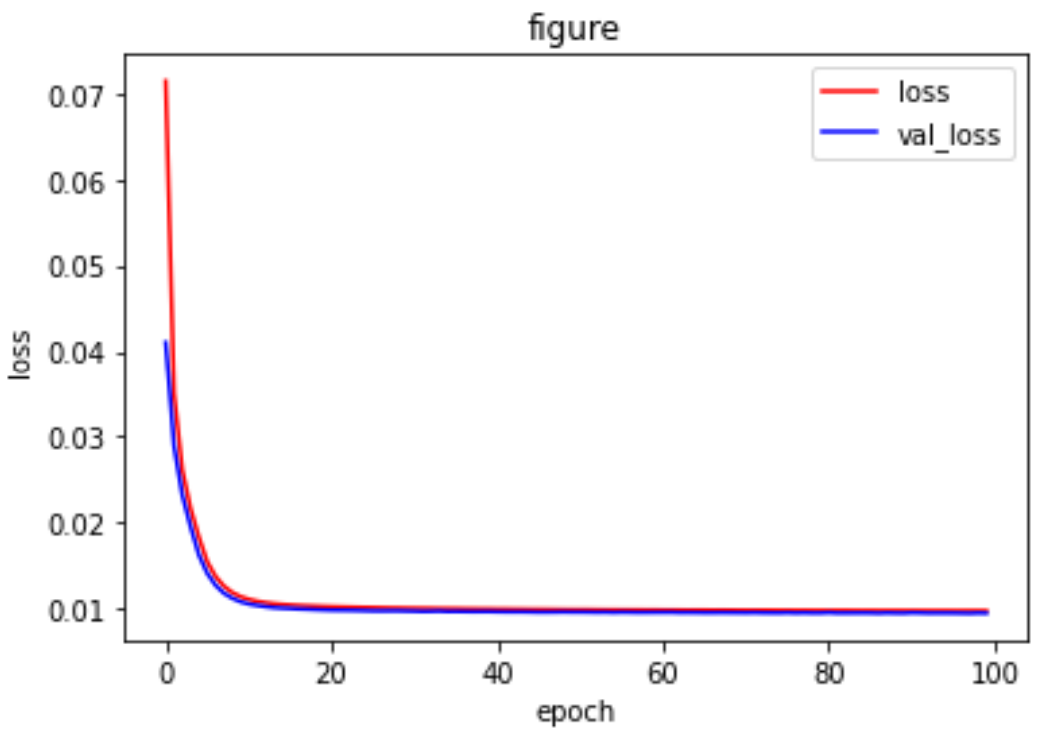
训练完成模型之后,把这个模型用在测试集上看一下效果
encode = tf.keras.Model(inputs=input,outputs=en) input_de = tf.keras.layers.Input(shape=(hidden_size,)) output_de = model.layers[-1](input_de) decode = tf.keras.Model(inputs=input_de,outputs=output_de) encode_test = encode(x_test) print(encode_test.shape) print(x_test.shape) decode_test = decode.predict(encode_test) print(decode_test.shape) #张量转化为numpy类型 x_test = x_test.numpy()
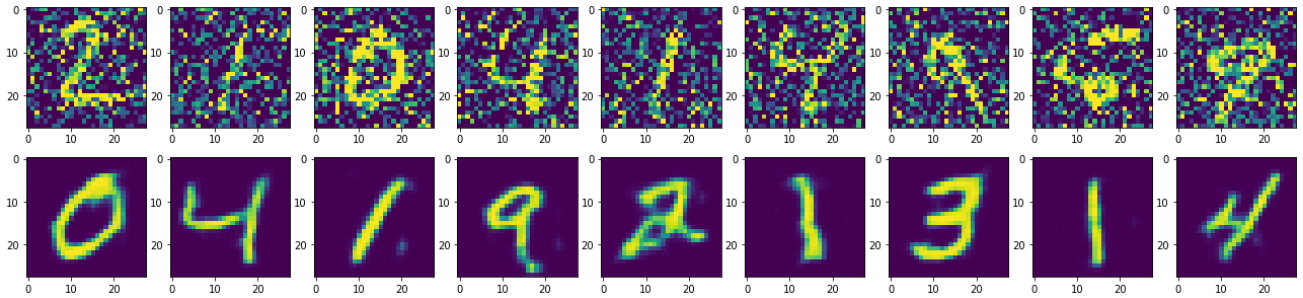
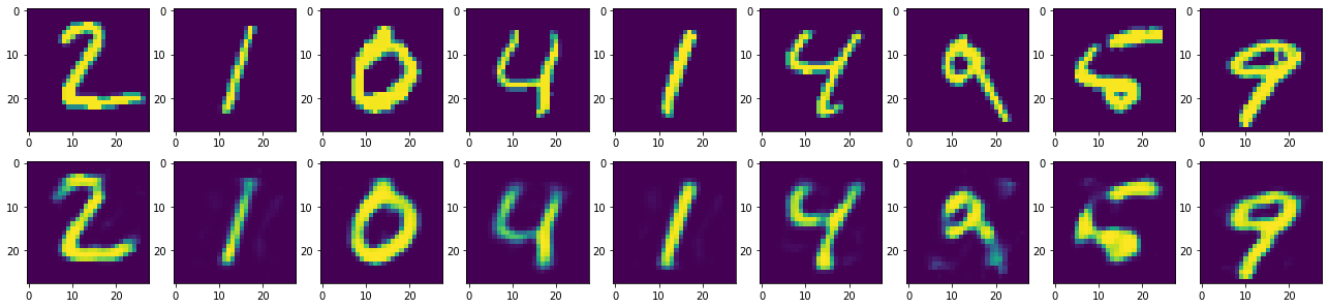
最后查看效果,可以发现结果产生的图片都会有一定程度的损失,也就是模糊:
n = 10 plt.figure(figsize=(25,5)) for i in range(1,n): ax = plt.subplot(2,n,i) plt.imshow(x_test[i].reshape(28,28)) ax = plt.subplot(2,n,i + n) plt.imshow(decode_test[i].reshape(28,28))
实例2.去噪编码器
这里和自编码器不同之处在于给归一化后的数据添加噪声来影响原来的图片。
#添加噪声 factor = 0.5 #np.random.normal(loc=0.0,scale=1.0,size=None) 对应高斯分布 # loc:float # 此概率分布的均值(对应着整个分布的中心centre) # scale:float # 此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高) # size:int or tuple of ints # 输出的shape,默认为None,只输出一个值 #要把最后的结果控制在0到-1之间 x_train_noise = x_train + factor*np.random.normal(size=x_train.shape) x_test_noise = x_test + factor*np.random.normal(size=x_test.shape) x_train_noise = np.clip(x_train_noise,0.,1.) x_test_noise = np.clip(x_test_noise,0.,1.)
查看一下添加噪声后的训练图像

去噪自编码器模型的搭建和自编码器一样不需要改动,在模型训练需要改变训练集为添加噪声后的训练集,测试集也是如此
#train history = model.fit(x_train_noise, x_train, epochs=10, batch_size=256, shuffle=True, validation_data=(x_test_noise,x_test))
之后再改变在去噪自编码器模型上使用的是添加噪声的测试集图片
decode = tf.keras.Model(inputs=input_de,outputs=output_de) encode_test = encode(x_test_noise) decode_test = decode.predict(encode_test)
查看一下损失和生成的图片是否达到去噪的效果
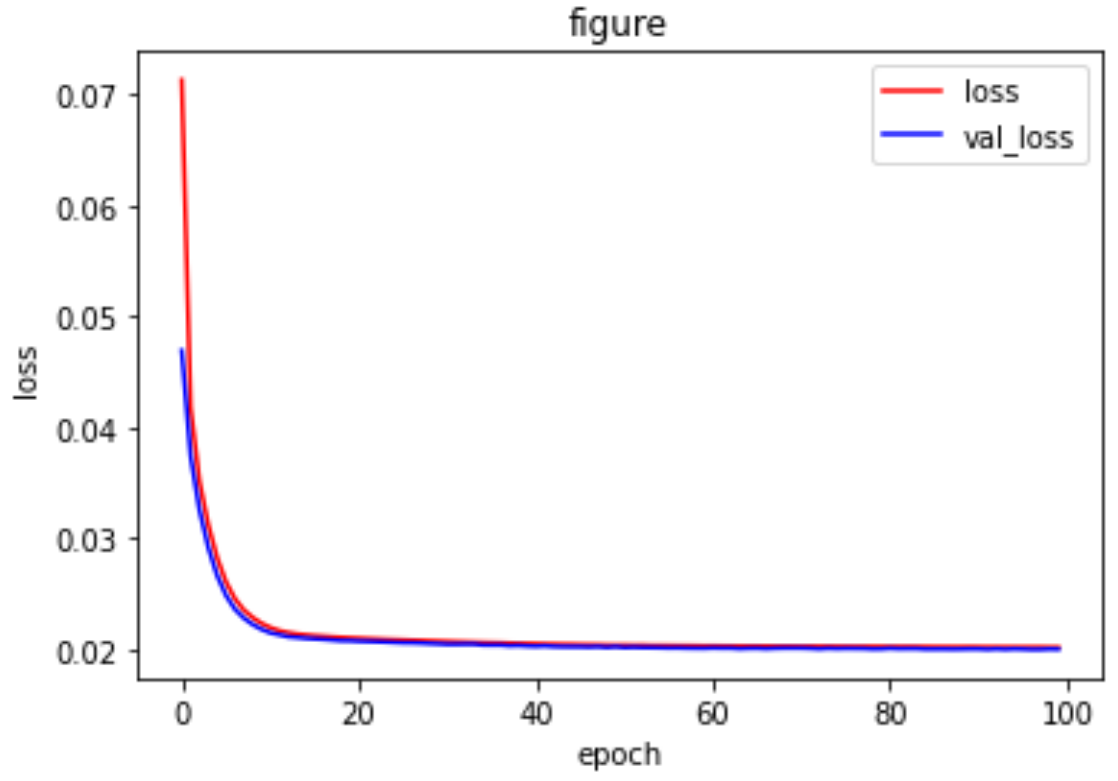
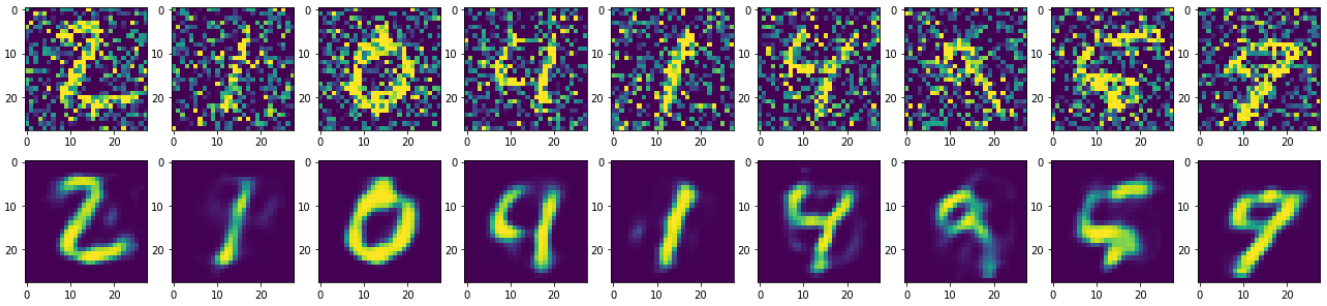
反卷积和上采样
下采样即pooling层,我们实现下采样一般有三种方法:
- 全局池化
- 平均池化
- 通过卷积改变stride
由于卷积过程中,我们的特征图像变得很小(比如长宽变为原图像的1/32),为了得到原图像大小的稠密像素预测,我们需要进行上采样。
通过下采样的方式我们可以反过来使用:
- 插值法
- 反池化
- 反卷积(转置卷积)
实例3.卷积去噪自编码器
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt (x_train,_),(x_test,_) = tf.keras.datasets.mnist.load_data() #自编码器的数据相似性,我们用来测试的数据仍是手写数字 print(x_train.shape) #(60000, 28, 28) print(x_test.shape) #(10000, 28, 28) #扩展维度,卷积网络常用的输入形式 x_train = np.expand_dims(x_train,-1) x_test = np.expand_dims(x_test,-1) print(x_train.shape) #(60000, 28, 28, 1) print(x_test.shape) #(10000, 28, 28, 1) #归一化 x_train = tf.cast(x_train,tf.float32) /255 x_test = tf.cast(x_test,tf.float32) /255 #添加噪声 factor = 0.5 #要把最后的结果控制在0到-1之间 x_train_noise = x_train + factor*np.random.normal(size=x_train.shape) x_test_noise = x_test + factor*np.random.normal(size=x_test.shape) x_train_noise = np.clip(x_train_noise,0.,1.) x_test_noise = np.clip(x_test_noise,0.,1.) #卷积去噪自编码器模型 input = tf.keras.layers.Input(shape=x_train.shape[1:]) #encode x = tf.keras.layers.Conv2D(16,(3,3),activation='relu',padding='same')(input) #28,28,16 x = tf.keras.layers.MaxPooling2D(padding='same')(x) #14,14,16 x = tf.keras.layers.Conv2D(32,(3,3),activation='relu',padding='same')(x) #14,14,32 x = tf.keras.layers.MaxPooling2D(padding='same')(x) #7,7,32 #decode x = tf.keras.layers.Conv2DTranspose(16,(3,3),strides=2,activation='relu',padding='same')(x) #14,14,16 x = tf.keras.layers.Conv2DTranspose(1,(3,3),strides=2,activation='sigmoid',padding='same')(x) #28,28,1 model = tf.keras.Model(inputs=input,outputs=x) model.summary() #模型编译 model.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001), loss='mse') #train history = model.fit(x_train_noise, x_train, epochs=100, batch_size=256, shuffle=True, validation_data=(x_test_noise,x_test)) print(history.history) loss = history.history['loss'] val_loss = history.history['val_loss'] plt.plot(history.epoch,loss,'r',label='loss') plt.plot(history.epoch,val_loss,'b',label='val_loss') plt.xlabel('epoch') plt.ylabel('loss') plt.title('figure') plt.legend() plt.show() pre_test = model.predict(x_train_noise) n = 10 plt.figure(figsize=(25,5)) for i in range(1,n): ax = plt.subplot(2,n,i) plt.imshow(x_test_noise[i].reshape(28,28)) ax = plt.subplot(2,n,i + n) plt.imshow(pre_test[i].reshape(28,28))
实验结果: