串的模式匹配算法,常见的有BF算法和KMP算法,其中BF算法可读性好,而KMP算法效率更高。
BF算法
BF算法也就是最朴素的模式匹配算法,也是一种暴力算法,非常好理解。
算法原理:
把目标串S的首字符与模式串T的首字符进行匹配,如果相等,继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到匹配成功或者
全部遍历完为止。
C语言实现:
1 //返回子串T在主串S中第pos个字符之后的位置,若不存在,则返回-1 2 int Index(char *S,char *T,int pos) //逐项比较 3 { 4 int j = 1,i = pos,lens=strlen(S),lent=strlen(T); //i用于主串S当前位置下表值,若pos不为1,则从pos位置开始匹配 j用于字串T中当前位置下标值 5 6 while(i<lens&&j<lent) //若i小于S的长度,且j小于T的长度则继续 7 { 8 if(S[i]==T[j]) 9 { 10 i++;j++; 11 } 12 else 13 { 14 i=i-j+2; //指针后退,重新开始匹配 15 j=1; 16 } 17 18 } 19 if(j>=lent) 20 return i-lent; 21 else 22 return -1; 23 }
KMP算法
BF算法的效率是比较低的,KMP算法是串的模式匹配中一种效率较高的算法。KMP算法的核心就是避免不必要的回溯,问题由模式串决定,不是由主串决定。
算法原理:
假设有两个字符串,一个是待匹配的字符串S,一个是要查找的关键字T。现在我们要在S中去查找是否包含T,用i来表示S遍历到了哪个字符,
用j来表示T匹配到了哪个字符。利用已经部分匹配这个有效信息,保持主串i指针不回溯,通过修改模式串j指针,让模式串尽量地移动到有效的位置。
那么整个KMP的重点就在于当某一个字符与主串不匹配时,我们应该知道j指针要移动到哪?
先举个例子找一找j的移动规律:

如上图:C和D不匹配了,我们要把j移动到哪?显然是第1位(也就是B处)。为什么?因为前面有一个A是相同的:

如下图也是一样的情况:

可以把j指针移动到第2位(也就是C处),因为前面有两个字母是一样的:

至此我们可以大概看出一点端倪,当匹配失败时,j要移动的下一个位置k。存在着这样的性质:最前面的k个字符和j之前的最后k个字符是一样的。
如果用数学公式来表示是这样的
P[0 ~ k-1] == P[j-k ~ j-1]
这个相当重要,如果觉得不好记的话,可以通过下图来理解:

弄明白了这个就应该可能明白为什么可以直接将j移动到k位置了。
一般,我们查找T中每一位前面的子串的前后缀有多少位匹配,从而决定j失配时应该回退到哪个位置,而结果就存储在next[ ]数组中。
我们可以得到如下的函数定义:
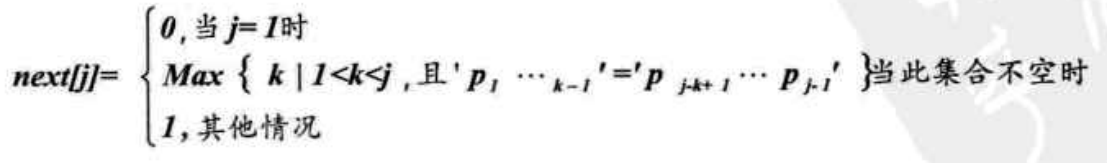
照此思路,求next [ ]数组的C语言实现如下
1 void get_next(char *T,int next[]) //修正前的next数组 2 { 3 int i = 1,j = 0; 4 5 next[1] = 0; 6 int m = strlen(T); 7 while(i<strlen(T)-1) // 根据已知的前j位推测第j+1位 8 { 9 if(j == 0||T[j]==T[i]) //T[I]表示后缀的单个字符,T[j]表示前缀的单个字符 10 { 11 ++i; 12 ++j; 13 next[i] = j; 14 } 15 else j = next[j]; //若字符不相同,j值回溯 16 } 17 }
求得了next [ ]数组,KMP算法也就不难实现了
1 //返回子串T在主串S中第pos个字符之后的位置,若不存在,则返回-1 2 int Index_kmp(char *S,char *T,int pos,int next[]) //逐项比较 3 { 4 int j = 0,i = pos,lens=strlen(S),lent=strlen(T); //i用于主串S当前位置下表值,若pos不为1,则从pos位置开始匹配 j用于字串T中当前位置下标值 5 get_next(T,next); //对子串T分析,得到next[]数组 6 while(i<lens&&j<lent) //若i小于S的长度,且j小于T的长度则继续 7 { 8 if(S[i]==T[j]||j==0) //两字母相等则继续,与朴素算法相比多了j==0 9 { 10 i++;j++; 11 } 12 else j = next[j]; //j指针后退,重新开始匹配 13 } 14 if(j>=lent) return i-lent; 15 else return -1; 16 }
后来人们又发现,next [ ]数组还有可以优化的地方。
(1)如果str[k] == str[j],很明显,我们的next[j+1]就直接等于k+1。用代码来写就是next[++j] = ++k;
可是我们知道,第j+1位是失配了的,如果我们回退j后,发现新的j(也就是此时的++k那位)跟回退之前的j也相等的话,必然也是失配。所以还得继续往前回退。
由此可得改进后的next [ ]数组 C语言实现
1 void get_nextval(char *T,int nextval[]) //修正后的nextval数组 2 { 3 int i = 1,j = 0; 4 5 nextval[1] = 0; 6 int m = strlen(T); 7 while(i<strlen(T)-1) 8 { 9 if(j == 0||T[j]==T[i]) 10 { 11 ++i; 12 ++j; 13 if(T[i]!=T[j]) nextval[i] = j; 14 else nextval[i] = nextval[j]; 15 } 16 else j = nextval[j]; 17 } 18 }