Hibernate的系统 学习
一、Hibernate的介绍
首先,hibernate是数据持久层的一个轻量级框架。数据持久层的框架有很多比如:iBATIS,myBatis,Nhibernate,Siena等等。
并且Hibernate是一个开源的orm(object relations mapping)框架,提供了查询获取数据的方法,用面向对象的思想来操作数据库,节省了我们开发处理数据的时间。
2.那使用Hibernate的优点呢?
1.使用简介的hql语句(Hibernate query language)。可以不使用传统的insert,update等sql语句。比如insert一个对象,原来的做法是:insert into 表名称 alue(值1,值2,值3,……),而现在的做法是:save(对象)。
2.使用or映射。对象到关系数据库之间的映射。是从对象的角度操作数据库,再次体现了面向对象思想。原来的实体抽取方法:首先有了表,然后表映射实体对象。而现在Hibernate做法是:直接由对象映射到表。
3.没有侵入性,移植性比较好。什么是没有侵入性?就是Hibernate采用了pojo对象。所谓的pojo对象就是没有继承Hibernate类或实现Hibernate接口。这样的话,此类就是一个普通的Java类,所以移植性比较好。
4.支持透明持久化。透明是针对上层而言的。三层架构的理念是上层对下层的依赖,只是依赖接口不依赖具体实现。而Hibernate中的透明是指对业务逻辑层提供了一个接口session,而其他的都封装隐藏。持久化是指把内存中的数据存放到磁盘上的文件中。
3.当然一个事物,不可能十全十美,即使如此优秀的Hibernate也有自己的弱点。比如:若是大量数据批量操作。则不适合使用Hibernate。并且一个持久化对象不能映射到多张表中。
4.Hibernate中核心5个接口
1.Configuration接口:负责配置及启动Hibernate,用来创建sessionFactory
2.SessionFactory接口:一个SessionFactory对应一个数据源存储,也就是一个数据库对应一个SessionFactory。SessionFactory用来创建Session对象。并且SessionFactory是线程安全的,可以由多个线程访问SessionFactory共享。
3.Session接口:这个接口是Hibernate中常用的接口,主要用于对数据的操作(增删改查)。而这个Session对象不是线程安全的。不能共享。
4.Query接口:用于数据库的查询对象。
5.Transaction接口:Hibernate事务接口。它封装了底层的事务操作,比如JTA(;Java transcation architecture)所有的数据操作,比如增删改查都写在事务中。
基本的概念以及核心接口已经介绍,那Hibernate又是如何应用的呢?下篇博客将会介绍如何使用Hibernate?
1.创建普通的Java项目。
因为hibernate是一个轻量级的框架,不像servlet,还必须需要tomcat的支持,Hibernate只要jdk支持即可。
2.引入jar包。
可以在项目中直接引入jar包,在:项目--->属性--->然后如下图: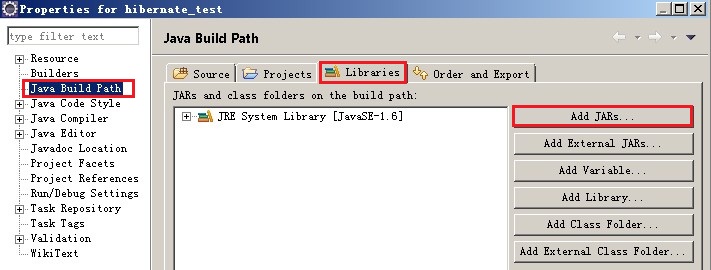
另一种办法就是引入库,相当于一个文件夹,把所有的jar包放到自己新建的文件夹中。在:窗体-->选项-->然后如下图:
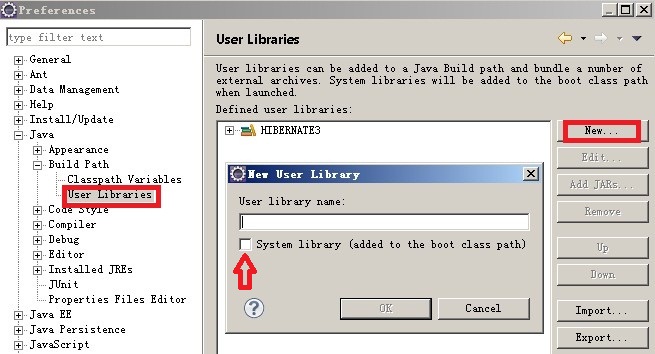
3.提供Hibernate的配置文件。hibernate.cfg.xml文件。完成相应的配置。
- <hibernate-configuration>
- <session-factory>
- <property name="hibernate.connection.driver_class">com.mysql.jdbc.Driver</property>
- <property name="hibernate.connection.url">jdbc:mysql://localhost:3306/hibernate_first</property>
- <property name="hibernate.connection.username">root</property>
- <property name="hibernate.connection.password">bjpowernode</property>
- <property name="hibernate.dialect">org.hibernate.dialect.MySQLDialect</property>
- </session-factory>
- </hibernate-configuration>
在这里连接MySQL数据库,解释一下上面的标签。按照顺序来依次解释:第一个是连接mySql的驱动;第二个是连接的url;url后面的hibernate_first是数据库名字;第三个是和第四个分别是用户名和密码。第五个是方言。因为 hibernate对数据库封装,对不同的数据库翻译成不同的形式,比如drp中的分页,若是使用Oracle数据库,则翻译成sql语句三层嵌套。若是使用mySql数据库,则翻译成limit语句。
4.建立实体User类:
- package com.bjpowernode.hibernate;
- import java.util.Date;
- public class User {
- private String id;
- private String name;
- private String password;
- private Date createTime;
- private Date expireTime;
- public String getId() {
- return id;
- }
- public void setId(String id) {
- this.id = id;
- }
- public String getName() {
- return name;
- }
- public void setName(String name) {
- this.name = name;
- }
- public String getPassword() {
- return password;
- }
- public void setPassword(String password) {
- this.password = password;
- }
- public Date getCreateTime() {
- return createTime;
- }
- public void setCreateTime(Date createTime) {
- this.createTime = createTime;
- }
- public Date getExpireTime() {
- return expireTime;
- }
- public void setExpireTime(Date expireTime) {
- this.expireTime = expireTime;
- }
- }
5.建立User.hbm.xml,此文件用来完成对象与数据库表的字段的映射。也就是实体类的那些字段需要映射到数据库表中呢。
- <?xml version="1.0"?>
- <!DOCTYPE hibernate-mapping PUBLIC
- "-//Hibernate/Hibernate Mapping DTD 3.0//EN"
- "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
- <hibernate-mapping>
- <class name="com.bjpowernode.hibernate.User">
- <id name="id">
- <generator class="uuid"/>
- </id>
- <property name="name"/>
- <property name="password"/>
- <property name="createTime"/>
- <property name="expireTime"/>
- </class>
- </hibernate-mapping>
6.我们也映射完毕了,但是hibernate怎么知道我们映射完了呢,以及如何映射的呢?这就需要我们把我们自己的映射文件告诉hibernate,即:在hibernate.cfg.xml配置我们的映射文件。
- <mapping resource="com/bjpowernode/hibernate/User.hbm.xml"/>
7.生成数据库表。大家也看到了我们上述还没有新建数据表呢,在第三步我们只是新建了数据库而已。按照我们普通的做法,我们应该新建数据表啊,否则实体存放何处啊。这个别急,数据库表这个肯定是需要有的,这个毋庸置疑,但是这个可不像我们原来需要自己亲自动手建立哦,现在hibernate需要帮我们实现哦,如何实现嗯,hibernate会根据配置文件hibernate.cfg.xml和我们的映射文件User.hbm.xml会自动给我们生成相应的表,并且这个表的名字也给我们取好:默认是User。那如何生成表呢?
- //默认读取hibernate.cfg.xml文件
- Configuration cfg = new Configuration().configure();
- SchemaExport export = new SchemaExport(cfg);
- export.create(true, true);
8.那我们就开始进行操作啦,我们添加一个用户对象,看看hibernate是如何添加的呢?跟我们以前的做法有什么不同呢?
- public class Client {
- public static void main(String[] args) {
- //读取hibernate.cfg.xml文件
- Configuration cfg = new Configuration().configure();
- //建立SessionFactory
- SessionFactory factory = cfg.buildSessionFactory();
- //取得session
- Session session = null;
- try {
- session = factory.openSession();
- //开启事务
- session.beginTransaction();
- User user = new User();
- user.setName("张三");
- user.setPassword("123");
- user.setCreateTime(new Date());
- user.setExpireTime(new Date());
- //保存User对象
- session.save(user);
- //提交事务
- session.getTransaction().commit();
- }catch(Exception e) {
- e.printStackTrace();
- //回滚事务
- session.getTransaction().rollback();
- }finally {
- if (session != null) {
- if (session.isOpen()) {
- //关闭session
- session.close();
- }
- }
- }
- }
- }
第八步,我们可以看到,没有我们熟悉的insert into表的sql语句了,那怎么添加进去的呢,到底添加了没?让我真实滴告诉你,确实添加进去了,不信的,可以自己尝试哦,这也是hibernate的优点,对jdbc封装的彻底,减少了我们对数据的操作时间哈。
看一下hibernate中整体的内容:
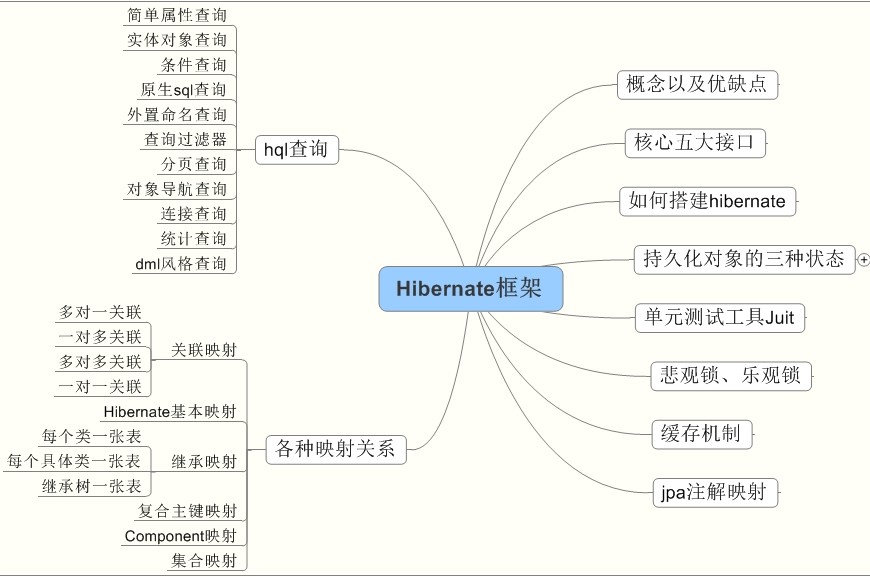
我们一一介绍其中的内容。
- Hibernate出现的原因上篇博客已经介绍,可以参考《Hibernate介绍》
- Hibernate中的核心五大接口,在上篇博客中也已经介绍,可以参考《Hibernate介绍》
- 如何搭建Hibernate,请参考《八步详解Hibernate的搭建及使用》
- 持久化对象的三种状态。
分别为:瞬时状态(Transient),持久化状态(Persistent),离线状态(Detached)。三种状态下的对象的生命周期如下:

三种状态的区别是:瞬时状态的对象:没有被session管理,在数据库没有;持久化状态的对象:被session管理,在数据库存在,当属性发生改变,在清理缓存时,会自动和数据库同步;离线状态:没有被session管理,但是在数据库中存在。
5.测试工具Juit。
测试类需要继承TestCase,编写单元测试方法,方法名称必须为test开头,方法没有参数没有返回值,采用public修饰。其中在测试中,查询对象时,使用get或者load两种方法进行加载,这种方法的区别:get不支持延迟加载,而load默认情况下是支持延迟加载。并且get查询对象不存在时,返回null;而load查询对象不存在时,则抛出ObjectNotFoundException异常。
6.悲观锁和乐观锁解释。
悲观锁为了解决并发性,跟操作系统中的进程中添加锁的概念一样。就是在整个过程中在事务提交之前或回滚之前,其他的进程是无法访问这个资源的。悲观锁的实现方式有两种:一种使用数据库中的独占锁;另一种是在数据库添加一个锁的字段。hibernate中声明锁如下:
Account account = (Account)session.get(Account.class, 1, LockMode.UPGRADE);而net.sf.hibernate.LockMode类表示锁模式,当取值LockMode.UPGRADE时,则表示使用悲观锁for update;而乐观锁是为了解决版本冲突的问题。就是在数据库中添加version字段,每次更新时,则把自己的version与数据库中的version进行比较,若是版本相比较低,则不允许进行修改更新。
7.H ibernate中的缓存机制。
缓存是什么呢?缓存是应用程序和数据库之间的内存的一片区域。主要的目的是:为了减少对数据库读取的时间。当查询数据时,首先在缓存中查询,若存在,则直接取出,若不存在,然后再向数据库中查询。所以应该把经常访问数据库的数据放到缓存中,至于缓存中的数据如何不断的置换,这也需要涉及一种淘汰数据的算法。
谈到这个hibernate中的缓存,你想到了什么呢?刚才叙述缓存时,是否感觉很熟悉,感觉从哪也听过似的。嗯呢,是呢,是很熟悉,写着写着就很熟悉,这个刚才的缓存以及缓存的置换算法就和计算机组成中的cache类似。
好吧,来回到我们hibernate中的缓存。
hibernate中的缓存可以分为两种:一级缓存,也称session缓存;二级缓存,是由sessionFactory管理。
那一级缓存和二级缓存有什么区别呢?区别的关键关于:缓存的生命周期,也就是缓存的范围不同。
那首先介绍一下缓存的生命周期,也就是缓存的范围。
1.事务缓存,每个事务都有自己的缓存,当事务结束,则缓存的生命周期同样结束,正如上篇博客中我们提到,对数据库的操作,增删改查都是放到事务中的,和事务保持同步,若是事务提交完毕,一般是不允许是再次对数据库进行操作。所以session是属于事务缓存的。
2.应用缓存,一个应用程序中的缓存,也就是应用程序中的所有事务的缓存。只有当应用程序结束时,此时的缓存的额生命周期结束。二级缓存就是应用缓存。
3.集群缓存,被一台机器或多台机器的进程共享。
这下明白了一级缓存和二级缓存的区别了吧。那一级缓存和二级缓存的共同点是:都是缓存实体属性,
二级缓存一般情况都是由第三方插件实现的。第三方插件如:
EHCache,JbossCache(是由Jboss开源组织提供的),osCache(open symphony),swarmCache。前三种对hibernate中的查询缓存是支持的,后一种是不支持hibernate查询缓存。
那什么是hibernate查询缓存呢?
查询缓存是用来缓存普通属性的,对于实体对象而言,是缓存实体对象的id。