决策边界:例子引出
比如我的决策是:当华为Mate降价到2000元的时候购买一个。对于这个问题,我的决策边界是2000元,也就是大于2000元的时候我不会购买,但小于2000元时我会选择购买。类似的生活中的例子很多。
决策边界分成两大类,分别是线性决策边界和非线性决策边界。拥有线性决策边界的模型我们称为线性模型,反之非线性模型。
模型的泛化能力:可以简单理解成“它在新的环境中的适应能力”,当然这个环境需要跟已有的环境类似才行。
上手实践让你理解的更快
1.导入模块
import matplotlib.pyplot as plt import numpy as np # product,这主要是用在可视化模块。 from itertools import product from sklearn.neighbors import KNeighborsClassifier
2.生成数据样本
# 在这里我们随机生成了样本。np.random.multivariate_normal是从多元正态分布中随机抽取样本的函数 # 其中一半的数据来源于第一个高斯分布,另一半的数据来自于第二个高斯分布。 n_points=100 X1=np.random.multivariate_normal([1,50],[[1,0],[0,10]],n_points) X2=np.random.multivariate_normal([2,50],[[1,0],[0,10]],n_points) # print(X1) # print(X2) X=np.concatenate([X1,X2]) y=np.array([0]*n_points+[1]*n_points) print(X.shape,y.shape)
3.训练不同的KNN模型来进行K值评估
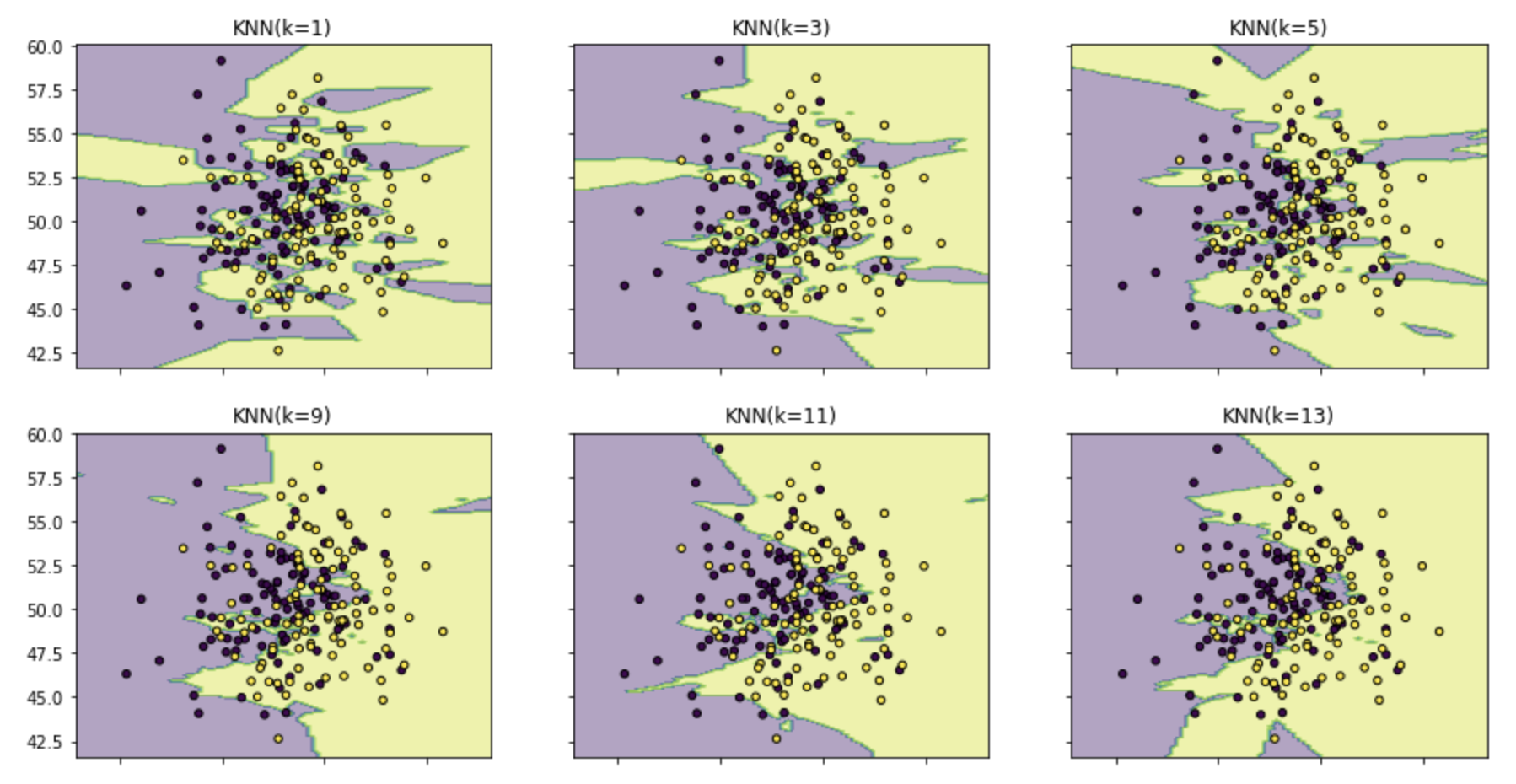
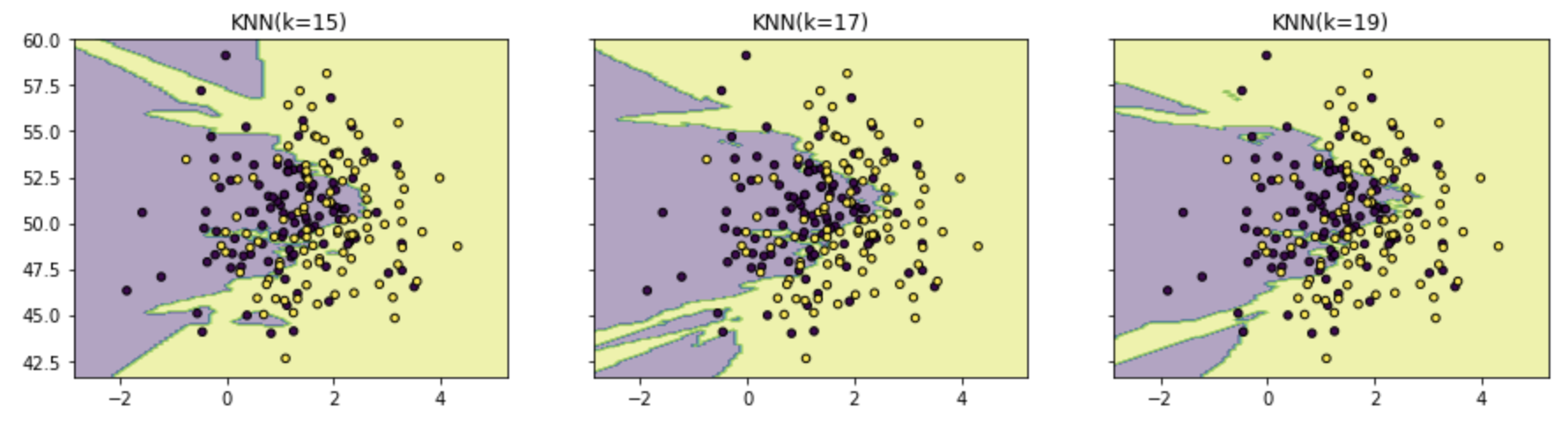
# 训练了9个不同的KNN模型。 # KNN模型的训练过程 clfs=[] neighbors=[1,3,5,9,11,13,15,17,19] for i in range(len(neighbors)): clfs.append(KNeighborsClassifier(n_neighbors=neighbors[i]).fit(X,y)) # print(clfs)
4.可视化过程:
# 可视化结果 x_min,x_max=X[:,0].min()-1,X[:,0].max()+1 y_min,y_max=X[:,1].min()-1,X[:,1].max()+1 xx,yy = np.meshgrid(np.arange(x_min,x_max,0.1), np.arange(y_min,y_max,0.1)) # print(xx) f,axarr = plt.subplots(3,3,sharex='col',sharey='row',figsize=(15,12)) for idx,clf, tt in zip(product([0,1,2],[0,1,2]), clfs, ['KNN(k=%d)'%k for k in neighbors]): Z = clf.predict(np.c_[xx.ravel(),yy.ravel()]) Z = Z.reshape(xx.shape) axarr[idx[0],idx[1]].contourf(xx,yy,Z,alpha = 0.4) axarr[idx[0],idx[1]].scatter(X[:,0],X[:,1],c = y, s = 20,edgecolor = 'k') axarr[idx[0],idx[1]].set_title(tt) plt.show()
结果