说明:Urllib 是一个python用于操作URL的模块
python2.x ----> Urillib/Urllib2
python3.x ----> Urllib
一、变动说明:
python2 中的Urllib和Urllib2 在python3 中合并为Urllib库,使用方法变动如下:
python2 python3
import urllib2 --------------> import urllib.request/urllib.error import urllib --------------> import urllib.request/urllib.error/urllib.parse import urlparse --------------> import urllib.parse urllib2.open --------------> urllib.request.urlopen urllib.urlencode --------------> urllib.parse.urlencode urllib.quote --------------> urllib.request.quote cookielib.CookieJar --------------> http.CookieJar urllib2.Request --------------> urllib.request.Request
二、使用Urllib爬取网页(python3)
urlopen方法
#导入模块: import urllib.request #打开网页,并将打开的内容赋给变量(urllopen): content_text = urllib.request.urlopen('http://blog.51cto.com') #读取网页内容: content_text.read() / content_text.readlines() content_text.readline()
content_text
.getcode() ###打印状态码
.url() ##打印url地址
.getheaders() ##打印头信息
.info() ##打印响应信息
print (dir(content_text)) ##打印所有方法
使用write方法写入到文件
file_save = open('51cto.html',"wb") ##以二进制方式写入 file_save.write(content_text.read()) file_save.close()
使用urltrieve函数写入
#使用urllib.request.urltrieve函数写入 urllib.request.urlretrieve(url,filename='本地文件地址')
#示例 urllib.request.urlretrieve('http://blog.51cto.com',filename='2.html')
urlretrieve函数解析
urltrive函数,将远程数据下载到本地 urlretrieve(url, filename=None, reporthook=None, data=None) 参数 finename 指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。) 参数 reporthook 是一个下载状态报告。 参数 data 指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。 urlretrieve执行过程中会产生缓存,可用 urlcleanup()进行清除 urllib.request.urlcleanup()
对网址进行编码解码:
编码:
urllib.request.quote("http://blog.51cto.com") ----------> http%3A//blog.51cto.com 解码:
urllib.request.unquote("http%3A//blog.51cto.com")
三、模拟浏览器headers属性
浏览器headers信息

urllib.request.Request方法
使用爬虫模拟浏览器头信息:
A、urllib.request.build_opener()方法
headers = ("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3107.4 Safari/537.36") opener = urllib.request.build_opener() ###创建自定义opener对象 opener.addheaders = [headers] ###添加headers信息 data = opener.open(url) ##模仿浏览器访问网站
B、urllib.request.Request 方法的add_header()属性
url = "http://blog.51cto.com" req = urllib.request.Request(url) #创建一个request对象 req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3107.4 Safari/537.36")
#或者这样写
headers = {"User-Agent","...."}
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req)
超时设置:
import urllib.request urllib.request.urlopen(url,timeout=1)
有时候访问get请求(搜索)的时候会遇到编码问题,需要用urllib.request.quote()对关键字进行编码,然后在构造完整的url才能进行请求
如:
url=’http://xxx.com/search?wd=..’ key=’要搜索的关键词’ key_code=urllib.request.quote(key) url_all = url+key_code urllib.request.urlopen(url_all)
post请求(流程方法)
A、 设置好url网址
B、 构建表单数据,并用urllib.parse.urlencode对数据进行编码
C、 创建requset对象,参数包括url地址和要传递的数据
D、 添加头信息(add_header()),模拟浏览器
E、 使用urllib.request.urlopen()打开对应的request对象,完成信息传递
F、 后续处理(网页内容的处理和存储等)
代码实现:
B、需要分析网页源代码或f12查看属性,查看要传入值的属性,构建字典: values = {key1:v1,key2:v2} post_data = urllib.parse.urlencode(values).encode(‘utf-8’) C、req = urllib.request.Request(url,post_data) ##创建request对象 D、req.add_header(‘User-Agent’,…) #添加头信息 E、data = urllib.request.urlopen(req) ##打开网页
代理服务器设置
http://www.xicidaili.com/ ##查找代理服务器
代码实现
def use_proxy(proxy_addr,url):
import urllib.request
proxy = urllib.request.ProxyHandler({'http':proxy_addr}) #设置对应的代理服务器信息
#对于一个代理ip列表、可以写成
import random
proxy = urllib.request.ProxyHandler({"http":random.choice(ip列表)})
或换个方式
proxy_info = { 'host' : 'proxy.myisp.com', 'port' : 3128 }
proxy_support = urllib.request.ProxyHandler({"http" : "http://%(host)s:%(port)d" % proxy_info})
opener = urllib.request.build_opener(proxy,urllib.request.HTTPHandler) #创建自定义opener对象
urllib.request.install_opener(opener) #创建全局默认的oper对象
data = urllib.request.urlopen(url).read().decode(‘utf-8’)
return data
proxy_addr = 'xxx.xxx.xxx.xxx:7777'
data = use_proxy(proxy_addr,url)
print (len(data))
如果代理ip不能用会提示:
·
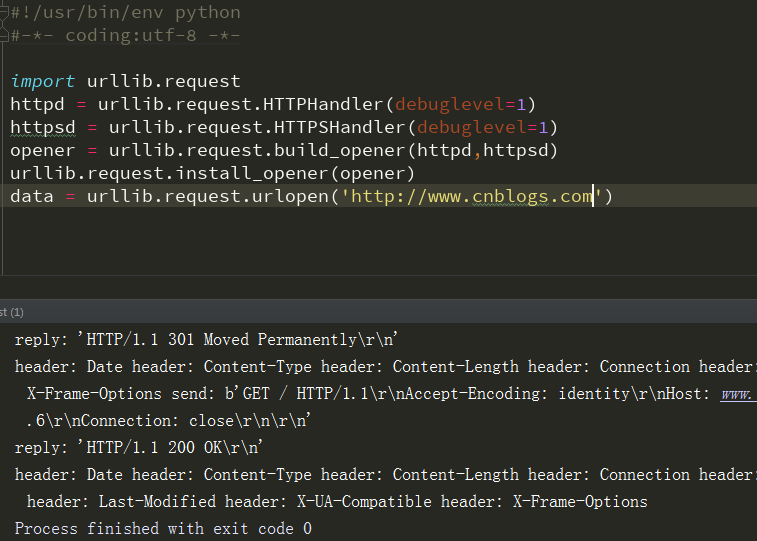
DebugLog
A、使用urllib.request.HTTPHandler() 和 urllib.request.HTTPSHandler() 将debuglevel 设置为1
B、使用urllib.request.build_opener() 创建自定义的opener对象,并设置以上为参数
C、用urllib.request.install_opener() 创建全局默认的opener对象
D、open
代码实现:
import urllib.request httpd = urllib.request.HTTPHandler(debuglevel=1) httpsd = urllib.request.HTTPSHandler(debuglevel=1) opener = urllib.request.build_opener(httpd,httpsd) urllib.request.install_opener(opener) data = urllib.request.urlopen(url)
异常处理:
URLError
HTTPrror

最终版
