索引
创建索引的命令:
db.user.ensureIndex({"username":1})
获取当前集合的索引:
db.user.getIndexes()
删除索引的命令是:
db.user.dropIndex({"username":1})
在 MongoDB 中,我们同样可以创建复合索引,如:数字 1 表示 username 键的索引按升序存储,-1 表示 age 键的索引按照降序方式存储。
db.user.ensureIndex({"username":1, "age":-1})
该索引被创建后,基于 username 和 age 的查询将会用到该索引,或者是基于 username的查询也会用到该索引,但是只是基于 age 的查询将不会用到该复合索引。因此可以说,如果想用到复合索引,必须在查询条件中包含复合索引中的前 N 个索引列。然而如果查询条件中的键值顺序和复合索引中的创建顺序不一致的话,MongoDB 可以智能的帮助我们调
整该顺序,以便使复合索引可以为查询所用。如:
db.user.find({"age": 30, "username": "stephen"})
对于上面创建的索引,MongoDB 都会根据索引的 keyname 和索引方向为新创建的索引
自动分配一个索引名,下面的命令可以在创建索引时为其指定索引名,如:
db.user.ensureIndex({"username":1},{"name":"userindex"})
随着集合的增长,需要针对查询中大量的排序做索引。如果没有对索引的键调用 sort,
MongoDB 需要将所有数据提取到内存并排序。因此在做无索引排序时,如果数据量过大以
致无法在内存中进行排序,此时 MongoDB 将会报错。
唯一索引
在缺省情况下创建的索引均不是唯一索引。下面的示例将创建唯一索引,如:
db.user.ensureIndex({"userid":1},{"unique":true})
如果再次插入 userid 重复的文档时,MongoDB 将报错,以提示插入重复键,如:
db.user.insert({"userid":5})
db.user.insert({"userid":5})
会报如下
E11000 duplicate key error index: user.user.$userid_1 dup key: { : 5.0 }
如果插入的文档中不包含 userid 键,那么该文档中该键的值为 null,如果多次插入类似的文档,MongoDB 将会报出同样的错误,如:
db.user.insert({"userid1":5})
db.user.insert({"userid1":5})
报错如下
E11000 duplicate key error index: user.user.$userid_1 dup key: { : null }
删除刚刚创建的唯一索引。
db.user.dropIndex({"userid":1})
我们同样可以创建复合唯一索引,即保证复合键值唯一即可。如:
db.user.ensureIndex({"userid":1,"age":1},{"unique":true})
使用 explain
explain 是非常有用的工具,会帮助你获得查询方面诸多有用的信息。只要对游标调用该方法,就可以得到查询细节。explain 会返回一个文档,而不是游标本身。如:
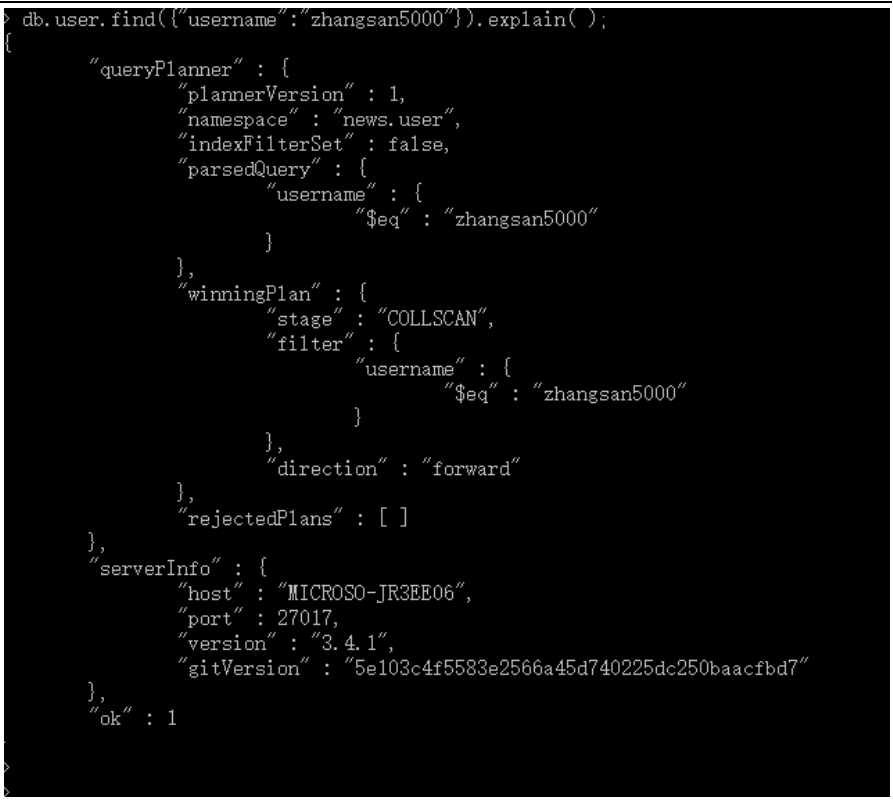
explain 会返回查询使用的索引情况,耗时和扫描文档数的统计信息。
explain executionStats 查询具体的执行时间
db.tablename.find().explain( "executionStats" )
关注输出的如下数值:explain.executionStats.executionTimeMillis