本文是一篇介绍Wrapper Induction的阅读笔记,原文详见《Wrapper induction:Efficiency and expressiveness》。
Wrapper Induction是一种自动的学习Wrapper的技术,通过一系列需要抽取的页面资源(训练数据),每个被抽取的文本段落都需要被标注来构建Wrapper Induction。文章分为以下几部分来介绍Wrapper Induction:
第一部分:Introduction
Ⅰ—EXPRESSIVENESS:介绍wrapper classes是如何有效处理Internet resources,并且通过one class来拓展处理其他网站资源。
Ⅰ-1—COVERAGE:我们调查了一些真实的网站,来决定哪些通过wrapper classes能够处理的,和以往追求100%准确率和召回率的采集方式(正则抽取或CSS选择器抽取)不同,我们对覆盖率更加感兴趣,能覆盖大约70%的网站抽取。
Ⅰ-2—RELATIVE EXPRESSIVENESS:另一个问题是拓展将一个wrapper classes复用模仿到其他。
Ⅱ—EFFICIENCY:我们的wrapper classes在抽取工作上被证明是有用的,但它们如何快速的学习?我们分为部分介绍:多少样本被需要?多少计算量被需要?
Ⅱ-1—SAMPLE COST:理论上训练的样本越多,wrapper就越有效,我们假定样本的数量是根据经验和分析得出的。
Ⅱ-1-a—EMPIRICAL RESULTS:通过测试的结果我们得出训练一个完美的wrapper通常需要2~3个样本就足够了。
Ⅱ-1-b—SAMPLE COMPLEXITY:We have shown that the number of examples required is polynomial in the relevant parameters;
Ⅱ-2—INDUCTION COST:在度量被训练的样本时,我们关注处理样本所花费的时间成本。
Ⅱ-2-a—EMPIRICAL RESULTS:测试学习算法通常每个样本在单个CPU上(less than)运行。
Ⅱ-2-b—TIME COMPLEXITY:Most of our wrapper classes can be learned in polynomial time.
第二部分:Wrapper Induction
之前提到了Wrapper Induction是一种构建wrapper classes的技术,下面是一些重要概念:
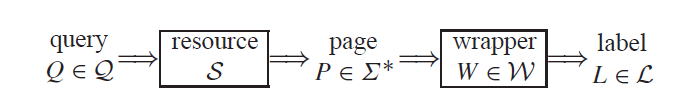
query我们不关注,resouce是一种资源(可以理解为互联网文档资源),page可以理解类比为html(想要抽取的页面),wrapper是我们都过训练样本获取的抽取模型,label是标签。
Attributes and tuples:简单的说就是每个page可以表示为若干个tuple,一个tuple是由一组attributes构成的向量表示。
Content and labels:简单的说就是每个page代表content,每个page由有个标签标注。
下面举个栗子:


上面左图是page的页面形式,右图是源码形式。而我们通过以下形式进行表示:
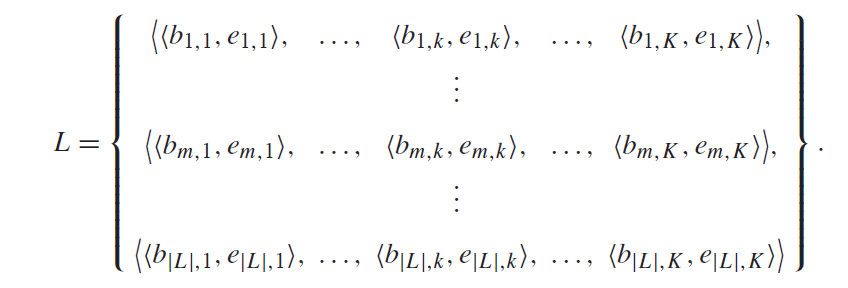
L代表page的标签,等号右边是page的表现形式,<bm,k,em,k>表示一个tuple,这里代表一个tuple具有两个attributes。
Wrappers and wrapper classes:Wrappers 是一种程序方法的集合,一个wrapper class作为Wrappers中的一个子集。
a wrapper W is a function from a page to a label; the notation W(P) = L indicates that the result of invoking wrapper W on page P is label L.
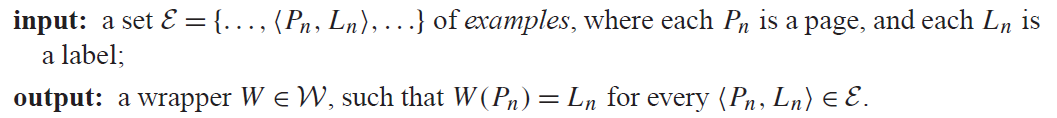
接下来会介绍六种wrapper class,其中比较简单的是 LR wrapper class。
我们会根据几个步骤来介绍wrapper class是如何生效的。
1、wrapper class在执行程序exec(w)是如何运行的;
2、定义wrapper class所构建的字符串分隔符向量;
3、定义字符串分隔符候选集cands(x);
4、定义字符串分隔符的限制条件constraints(x)和验证条件valid(x);
5、定义wrapper class学习程序learn(w),如何选择cands(x)和测试验证valid(x)。
第三部分:The LR wrapper class
LR wrapper class是一种比较简单的方法,它只关注需要抽取内容的左邻和右邻部分内容。
1、执行程序exec(w):

执行程序exec(w)可以看成是一个函数,通过输入想要抽取的页面page和包装器wrapper,输出结果label。其中<l1,r1,l2,r2,...,lk,rk>是我们通过字符串分隔符形成的向量。在该程序中我们其实是不断通过定义的左右分隔符来获取抽取信息的位置信息。
2、LR wrapper class的字符串分隔符向量
LR wrapper class分别具有左右两种分隔符,通过元组tuple<lk,rk>来将信息抽取出来记录位置信息。举个例子:

我们想要抽取“国家”信息和“数字”信息两种,这时我们定义k=2,左分隔符l1可以是<B>,右分隔符r1可以是</B>;左分隔符l2可以是<I>,右分隔符r2可以是</I>。
3、字符串分隔符候选集cands(x)
LR wrapper class分为左右两个候选集cands(l)和cands(r),上段中提到的左右分隔符只是对应候选集中的一个。同样我们举个栗子:
cands(l)可以如下表示为(其中![]() 表示换行符):
表示换行符):

cands(r)可以如下表示为:

4、字符串分隔符的限制条件constraints(x)和验证条件valid(x)
右分隔符u限制条件constraints(r):
a、u 必须不能是任何需要抽取的属性k中的一部分;
b、u 必须是任何需要抽取的属性k后面紧贴字符的前缀。
右验证方法valid(r):
当且仅当分隔符能够正确的抽取想要的信息时,我们返回true,否则返回false。(结合国家代码那个html栗子)

左分隔符u限制条件constraints(l):
a、u 必须是任何需要抽取的属性k前面紧贴字符的后缀,其中后缀满足条件(‘cde’是‘deabcde’的后缀,但是‘de’不是,因为前缀也是‘de’);
b、只针对l1,u 必须不能是抽取页面的尾部字符中任何一部分。
左验证方法valid(l):
当且仅当分隔符能够正确的抽取想要的信息时,我们返回true,否则返回false。(结合国家代码那个html栗子)

5、学习程序learn(w),如何选择cands(x)和测试验证valid(x)






至此LR wrapper class基本介绍完了!之后有机会介绍后五种相对比左右包装器复杂一些的方法。