最近由于公司慢慢往spark方面开始转型,本人也开始学习,今后陆续会更新一些spark学习的新的体会,希望能够和大家一起分享和进步。
Spark是什么?
Apache Spark™ is a fast and general engine for large-scale data processing.(官方说法)
Spark,简单的说是一种通用的大数据计算框架。
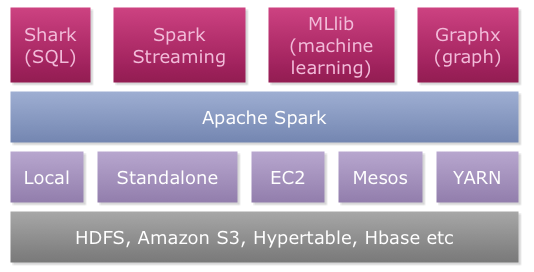
包含了常见领域的各种框架:核心组件-Spark Core、交互式查询-Spark SQL、准实时流式计算-Spark Streaming、机器学习-Spark MLlib、图计算-Spark GraphX。
Spark与Hadoop的关系
很多人说Spark可以替换Hadoop,这显然是错的。Spark是基于Hadoop的,即Spark主要用于大数据的计算,而Hadoop由于计算方面采用MapReduce的方式,多次反复读写磁盘,使得速度远远不如Spark快,所以Hadoop以后会用于大数据的存储(HDFS、Hive、HBase等)和资源调度(Yarn)。
Spark本身不具备存储功能,未来Spark+Hadoop的组合是一套完整的解决方案。
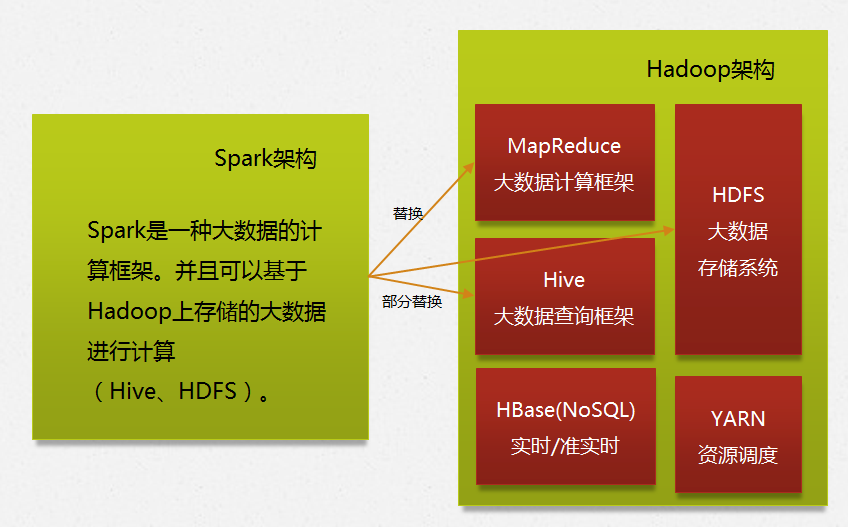
Spark可以替换MapReduce的计算框架、Spark SQL可以替换Hive的查询框架,但并没有Hive作为数据仓库的功能,所以只是部分替换。