对eBPF的理解
要理解eBPF首先需要理解其前身BPF
BPF(伯克利包过滤器Berkeley Packet Filter)诞生的目的是为了提供过滤数据包的方法,从而避免从内核空间复制无用的数据包到用户空间的行为。它最初是由从用户空间注入到内核的一个简单的字节码构成,它在那个位置利用一个校验器进行检查 —— 以避免内核崩溃或者安全问题 —— 并附着到一个套接字(socket)上,接着在每个接收到的包上运行。(就是通过一些字节码在端口接收的包一起运行,来避免内核崩溃),几年后它被移植到Linux平台上,由于它简化的语言和存在于内核中的即时编译器,BPF成为一个十分好用的编译器。
在 2013 年,Alexei Starovoitov 对 BPF 进行彻底地改造,并增加了新的功能,改善了它的性能。这个新版本被命名为 eBPF (意思是 “extended BPF”)。
eBPF的深入理解
eBPF本质是运行在内核中的虚拟机,eBPF为了避免代码的安全性问题,他在内核中实现了虚拟机执行用户指令。eBPF为用户提供了RISC(精简指令集,内含有常用的指令集),以及一些基本指令集,用户通过这组指令可以直接编写程序。程序在下发指令时也会通过eBPF的检查,避免了一些内核崩溃,被攻击等问题的发生。
eBPF运行的基本原理
通过与BPF系统的接口与内核进行交互,eBPF程序通过LVM(Linux环境下对磁盘分区进行管理的一种机制)和Cline(Linux系统的C语言编译器)编译,产生eBPF字节码,通过BPF系统调用,加载到内核,验证代码安全性。
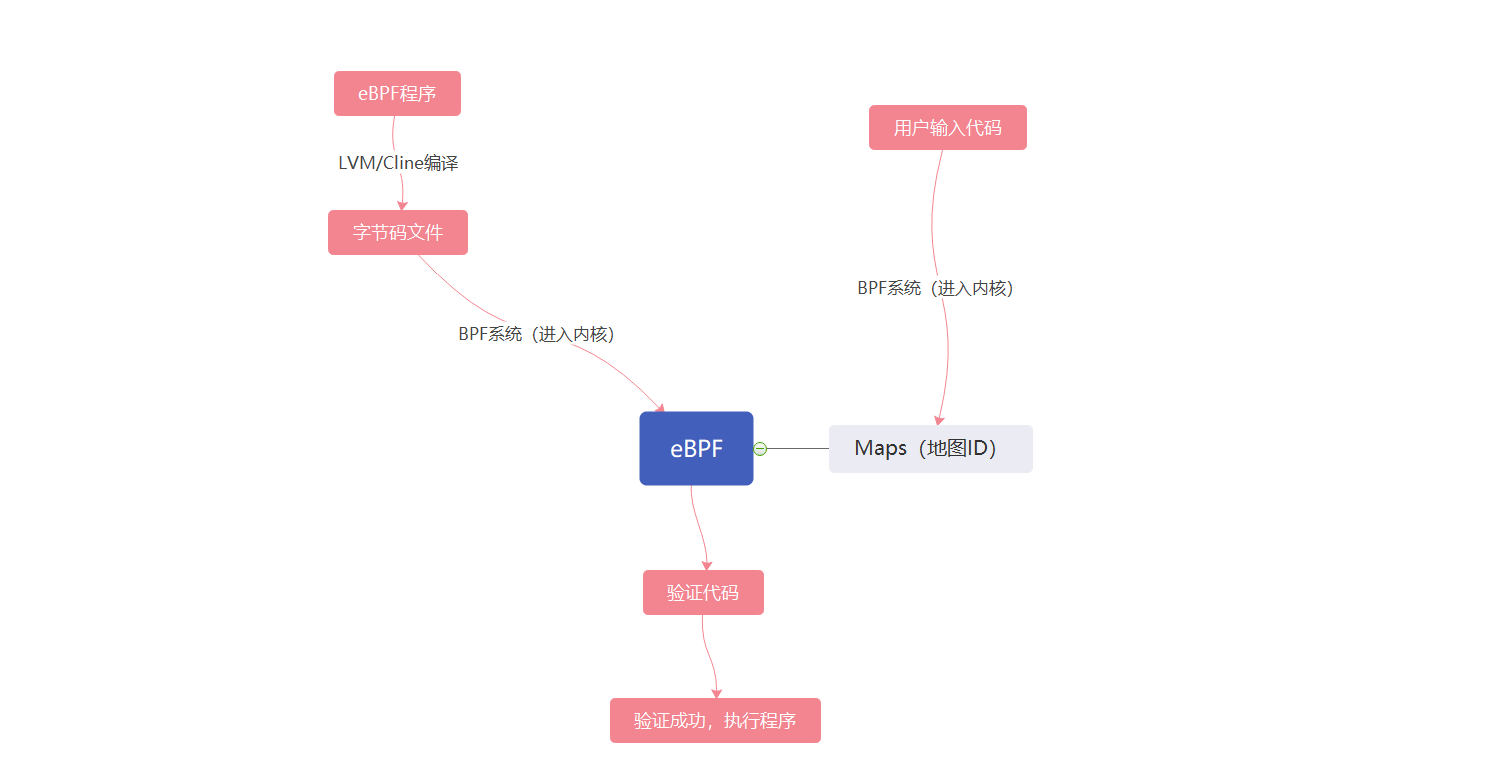
eBPF内核验证程序
分为三次测试。
第一次测试确保eBPF程序能够终止,无法到达的指令和无法访问的程序都无法加载,确保程序内不包含导致内核锁定的循环。
第二次要模拟一次eBPF程序的执行。在执行前后都需要检查虚拟机的状态,以确保寄存器和堆栈状态有效。禁止越界数据的出现。
第三次,需要验证者选择需要的内核功能来跳过已经进行过的模拟。
eBPF总结
eBPF是BPF的补充和更新,它存在与内核中,可以称它是一种“附加”到内核中虚拟机,当遍历代码路径时,所有附加的eBPF程序都会被执行,他在执行每一个eBPF程序前还会进行安全检查,防止安全问题的出现。总而言之,它的优点就是:安全和快速
但是正是由于eBPF的安全性,在加载每一个eBPF程序之前,会进行大量的检查工作,加重了系统的负担。同时限制了没有访问权限的指令,这些程序都没办法加载。在模拟eBPF程序执行时,执行指令前后都需要检查虚拟机的状态,禁止越界,访问越界数据也同样禁止。它的缺点:对代码和数据的准确性要求很高