我的Elasticsearch系列文章,逐渐更新中,欢迎关注
0A.关于Elasticsearch及实例应用
00.Solr与ElasticSearch对比
01.ElasticSearch能做什么?
02.Elastic Stack功能介绍
03.如何安装与设置Elasticsearch API
04.如果通过elasticsearch的head插件建立索引_CRUD操作
05.Elasticsearch多个实例和head plugin使用介绍
06.当Elasticsearch进行文档索引时,它是怎样工作的?
10.Kibana科普-作为Elasticsearhc开发工具
11.Elasticsearch查询方法
15.使用Django进行ElasticSearch的简单方法
16.关于Elasticsearch的6件不太明显的事情
17.使用Python的初学者Elasticsearch教程
18.用ElasticSearch索引MongoDB,一个简单的自动完成索引项目
19.Kibana对Elasticsearch的实用介绍
20.不和谐如何索引数十亿条消息
21.使用Django进行ElasticSearch的简单方法
另外Elasticsearch入门,我强烈推荐ElasticSearch新手搭建手册和这篇优秀的REST API设计指南 给你,这两个指南都是非常想尽的入门手册。
在上一个博客中,我们了解了如何将Kibana用作开发工具以及如何使用Kibana加载示例数据。
从这个博客中,我们将研究Elasticsearch的查询DSL,它非常强大,对于任何Elasticsearch用户来说都是必不可少的知识领域。
Elasticsearch查询类型
Elasticsearch中的查询可以大致分为两类,
1.叶子查询
叶子查询在某些字段中查找特定值。这些查询可以独立使用。其中一些查询包括匹配,条件,范围查询。
2.复合查询
复合查询使用叶/复合查询的组合。基本上,它们将多个查询组合在一起以实现其目标结果。
下图大致显示了这两个查询的大致分类: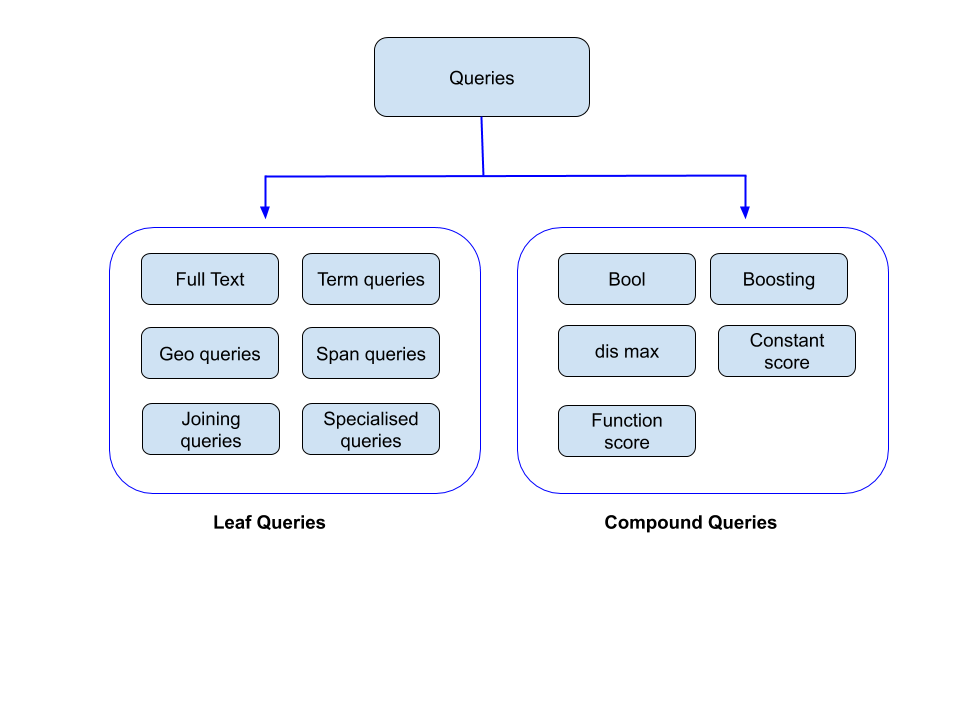
【图1】
如上图所示,Leaf和化合物分类中仍然有许多类别。在接下来的博客中,我们将更详细地访问上图中的大多数查询/查询类型。
基本查询样本
现在,让我们熟悉叶子的2个基本查询和复合查询类型中的一个查询以开始操作。
1.简单的“匹配”查询
假设我们考虑建立索引的文件在以前的博客,让我们尝试在球场上“FIRST_NAME”为搜索关键词“丹尼”的简单匹配查询。该查询将如下所示:
POST employees/_search
{
“query”: {
“match”: {
“country”: “China”
}
}
}
上面的查询将返回给我们所有国家为中国的文件
2.范围查询
现在让我们触发另一个查询,这个查询也是一个叶子查询。该查询将向我们返回所有薪水大于或等于500,000的员工。可以使用如下范围查询来实现:
POST/ _ { “ query”:{ “ range”:{ “ salary”:{ “ gte”:500000 } } } }
3.布尔查询
现在来了有趣的部分。我们如何比较以上查询?也就是说,我需要所有来自中国但收入超过50万的员工。
这需要上述两个叶查询的组合。现在,Elasticsearch提供了使用bool查询组合这些查询的工具。让我们讨论布尔查询的一般结构,然后回到问题所在。
布尔查询的一般结构:
POST _search { “ query”:{ “ bool”:{ “ must”:[...], “ filter”:[...], “ must_not”:[...], “ should”:[.. 。] } } }
must:子句(查询)必须出现在匹配的文档中,并将有助于得分。
filter:子句(查询)必须出现在匹配的文档中。但是与查询分数不同的是,忽略该分数。
应该:子句(查询)应出现在匹配的文档中。
must_not:子句(查询)不得出现在匹配的文档中。
现在回到我们的问题,我们的bool查询旨在重整所有来自中国的雇员并赚取超过500,000的工资,如下所示:
POST employee / _search { “ query”:{ “ bool”:{ “ must”:[ { “ match”:{ “ country”:“ China” } }, { “ range”:{ “ salary”:{ “ gte” :500000 } } } ] } } }
现在,让我们考虑是否要从列表中筛选出所有男性雇员。我们应该做什么?。只需在上面的查询中添加条件性别为“ Male”的must_not部分即可,如下所示:
POST employee / _search { “ query”:{ “ bool”:{ “ must”:[ { “ match”:{ “ country”:“ China” } }, { “ range”:{ “ salary”:{ “ gte” :500000 } } } ], “ must_not”:[ { “ match”:{ “ gender”:“ Male” } } ] } } }
查询上下文和过滤器上下文
默认情况下,Elasticsearch返回搜索结果时,会根据它们的相关性得分对它们进行排序,这表明文档与查询的匹配程度。计算该相关性分数,并将其与每个结果一起返回到元数据的_score参数中。
默认情况下,这是一个正浮点数。
对于不同类型的查询,_score计算技术可能有所不同。也就是说,“匹配”查询的得分计算可能与“跨度”查询的得分计算不同。
但最重要的是,分数计算取决于查询子句运行的上下文。也就是说,查询子句可以在“查询”上下文或“过滤器”上下文中运行。
查询上下文
在查询上下文中执行子句时,它将查找“文档与查询的匹配程度”。比赛越多,得分越高。
如下面的屏幕截图所示: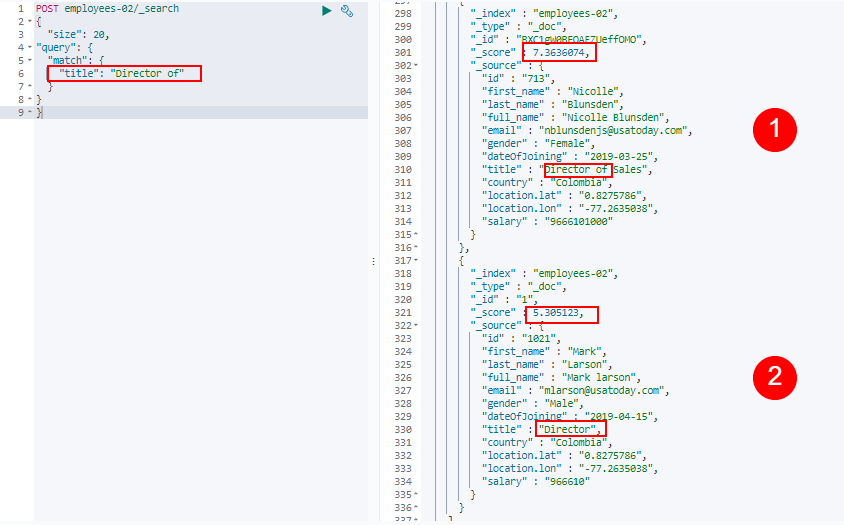
【图2】
在上面的示例中,我在“标题”字段中搜索了“导演”。该查询返回了一些结果,查找结果1,标题与查询子句(即关键字“ Director”和“ of”)完全匹配。因此,第一份文档的分数更高,为7.363
与第二个文档中一样,查询子句中只有一个关键词匹配(第二个文档中只有“ Director”已经匹配),因此比第一个文档的得分少(5.305)。
因此,与第二个文档相比,第一个文档的匹配度更高,这很明显地反映在两个文档的_score元数据中。
当在查询上下文中给出查询子句时,就会发生这种情况。
筛选条件
当在过滤器上下文中给出查询子句时,它仅查看文档是否包含not子句。这实际上是对/错的返回。假设我们在过滤器上下文中查询数据,通过询问文档字段性别是否匹配“ Male”,我们将只获得匹配的文档,而没有分数。
与查询上下文不同,筛选器上下文不使用时间来计算分数,因此筛选器上下文返回更快的结果。
下图显示了涉及按性别过滤的过滤器上下文示例,如下图所示: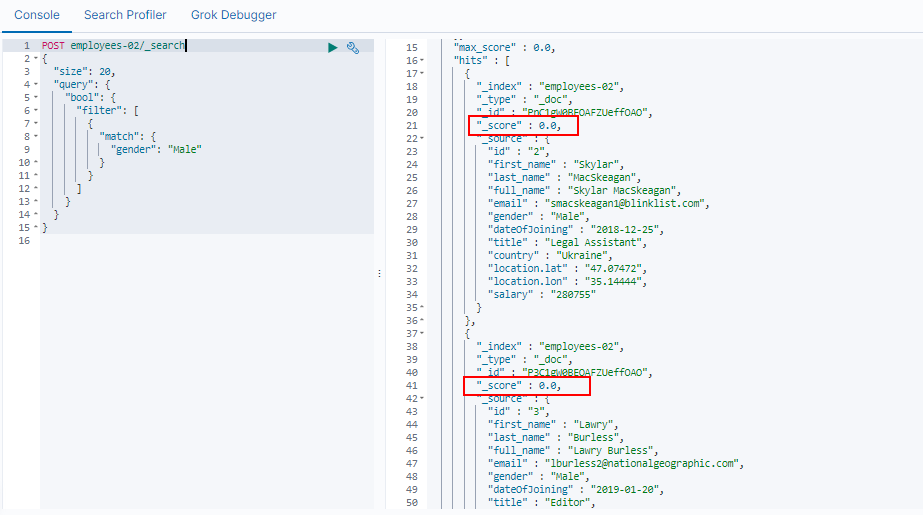
【图3】
在上面的示例中,您可以看到在过滤器上下文中应用时,结果文档的分数返回0。
重新访问布尔查询。
考虑到上述情况,是时候重新讨论布尔查询了。
在布尔查询中,必须和应节将在查询上下文中执行,这意味着必须节中的子句将计算分数。
bool查询中的must_not和should部分在哪里执行过滤条件中的查询子句,并且不会影响评分。
为了演示,让我们首先尝试在must节中使用相同的查询子句集,然后在must节中应用一个子句,然后在过滤器节中应用一个子句,然后查看分数如何变化。
案例1:“必须”部分中的两个子句

如您所见,在上面的查询中,两个子句都处于相同的必须条件中,并且第一个结果的文档返回的分数为2.4333658(在右侧面板中)
情况2:一个子句移到过滤器部分
让我们如下移动bool查询中的filter子句中的gender子句,然后运行查询。

现在,在右侧面板中,看分数,你可以看到,得分已经下降到1.7261622,这意味着只有在clausein 必须的部分被计算为得分,并在该条款过滤器部分不用于评分。
为了确认这一点,我们只能使用must节子句运行上面的查询,并查看它是否返回相同的分数。
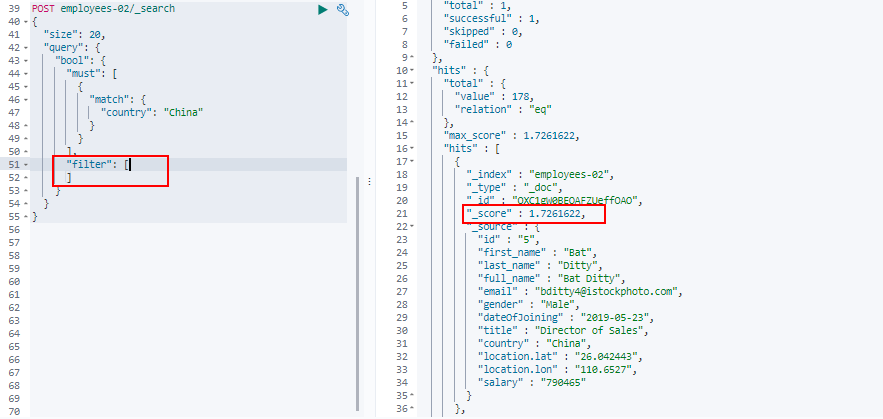
正如您所预测的那样,即使从查询中删除了filter子句,您也可以从上面的图片中看到分数保持不变。
结论
在此博客中,我们刚刚熟悉了Elasticsearch查询的分类,查询的上下文以及一些最基本的查询。
在下一个病房博客上,我们将详细探讨每种查询类型,并提供更多示例和数据集。