Scrapy这个成熟的爬虫框架,用起来之后发现并没有想象中的那么难。即便是在一些小型的项目上,用scrapy甚至比用requests、urllib、urllib2更方便,简单,效率也更高。废话不多说,下面详细介绍下如何用scrapy将妹子图爬下来,存储在你的硬盘之中。关于Python、Scrapy的安装以及scrapy的原理这里就不作介绍,自行google、百度了解学习。
一、开发工具
Pycharm 2017
Python 2.7
Scrapy 1.5.0
requests
二、爬取过程
1、创建mzitu项目
进入"E:CodePythonSpider>"目录执行scrapy startproject mzitu命令创建一个爬虫项目:
1 scrapy startproject mzitu
执行完成后,生产目录文件结果如下:
1 ├── mzitu 2 │ ├── mzitu 3 │ │ ├── __init__.py 4 │ │ ├── items.py 5 │ │ ├── middlewares.py 6 │ │ ├── pipelines.py 7 │ │ ├── settings.py 8 │ │ └── spiders 9 │ │ ├── __init__.py 10 │ │ └── Mymzitu.py 11 │ └── scrapy.cfg
2、进入mzitu项目,编写修改items.py文件
定义titile,用于存储图片目录的名称
定义img,用于存储图片的url
定义name,用于存储图片的名称
1 # -*- coding: utf-8 -*- 2 3 # Define here the models for your scraped items 4 # 5 # See documentation in: 6 # https://doc.scrapy.org/en/latest/topics/items.html 7 8 import scrapy 9 10 class MzituItem(scrapy.Item): 11 # define the fields for your item here like: 12 title = scrapy.Field() 13 img = scrapy.Field() 14 name = scrapy.Field()
3、编写修改spiders/Mymzitu.py文件
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from mzitu.items import MzituItem 4 from lxml import etree 5 import requests 6 import sys 7 reload(sys) 8 sys.setdefaultencoding('utf8') 9 10 11 class MymzituSpider(scrapy.Spider): 12 def get_urls(): 13 url = 'http://www.mzitu.com' 14 headers = {} 15 headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36' 16 r = requests.get(url,headers=headers) 17 html = etree.HTML(r.text) 18 urls = html.xpath('//*[@id="pins"]/li/a/@href') 19 return urls 20 21 name = 'Mymzitu' 22 allowed_domains = ['www.mzitu.com'] 23 start_urls = get_urls() 24 25 def parse(self, response): 26 item = MzituItem() 27 #item['title'] = response.xpath('//h2[@class="main-title"]/text()')[0].extract() 28 item['title'] = response.xpath('//h2[@class="main-title"]/text()')[0].extract().split('(')[0] 29 item['img'] = response.xpath('//div[@class="main-image"]/p/a/img/@src')[0].extract() 30 item['name'] = response.xpath('//div[@class="main-image"]/p/a/img/@src')[0].extract().split('/')[-1] 31 yield item 32 33 next_url = response.xpath('//div[@class="pagenavi"]/a/@href')[-1].extract() 34 if next_url: 35 yield scrapy.Request(next_url, callback=self.parse)
我们要爬取的是妹子图网站“最新”的妹子图片,对应的主url是http://www.mzitu.com,通过查看网页源代码发现每一个图片主题的url在<li>标签中,通过上面代码中get_urls函数可以获取,并且返回一个url列表,这里必须说明一下,用python写爬虫,像re、xpath、Beautiful Soup之类的模块必须掌握一个,否则根本无法下手。这里使用xpath工具来获取url地址,在lxml和scrapy中,都支持使用xpath。
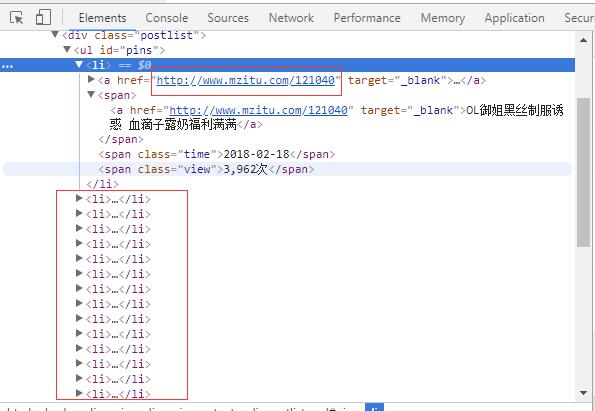
1 def get_urls(): 2 url = 'http://www.mzitu.com' 3 headers = {} 4 headers['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36' 5 r = requests.get(url,headers=headers) 6 html = etree.HTML(r.text) 7 urls = html.xpath('//*[@id="pins"]/li/a/@href') 8 return urls
name定义爬虫的名称,allowed_domains定义包含了spider允许爬取的域名(domain)列表(list),start_urls定义了爬取了url列表。
1 name = 'Mymzitu' 2 allowed_domains = ['www.mzitu.com'] 3 start_urls = get_urls()
分析图片详情页,获取图片主题、图片url和图片名称,同时获取下一页,循环爬取:
1 def parse(self, response): 2 item = MzituItem() 3 #item['title'] = response.xpath('//h2[@class="main-title"]/text()')[0].extract() 4 item['title'] = response.xpath('//h2[@class="main-title"]/text()')[0].extract().split('(')[0] 5 item['img'] = response.xpath('//div[@class="main-image"]/p/a/img/@src')[0].extract() 6 item['name'] = response.xpath('//div[@class="main-image"]/p/a/img/@src')[0].extract().split('/')[-1] 7 yield item 8 9 next_url = response.xpath('//div[@class="pagenavi"]/a/@href')[-1].extract() 10 if next_url: 11 yield scrapy.Request(next_url, callback=self.parse)
4、编写修改pipelines.py文件,下载图片
1 # -*- coding: utf-8 -*- 2 3 # Define your item pipelines here 4 # 5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting 6 # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html 7 import requests 8 import os 9 10 class MzituPipeline(object): 11 def process_item(self, item, spider): 12 headers = { 13 'Referer': 'http://www.mzitu.com/' 14 } 15 local_dir = 'E:\data\mzitu\' + item['title'] 16 local_file = local_dir + '\' + item['name'] 17 if not os.path.exists(local_dir): 18 os.makedirs(local_dir) 19 with open(local_file,'wb') as f: 20 f.write(requests.get(item['img'],headers=headers).content) 21 return item
5、middlewares.py文件中新增一个RotateUserAgentMiddleware类
1 class RotateUserAgentMiddleware(UserAgentMiddleware): 2 def __init__(self, user_agent=''): 3 self.user_agent = user_agent 4 def process_request(self, request, spider): 5 ua = random.choice(self.user_agent_list) 6 if ua: 7 request.headers.setdefault('User-Agent', ua) 8 #the default user_agent_list composes chrome,IE,firefox,Mozilla,opera,netscape 9 #for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php 10 user_agent_list = [ 11 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" 12 "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", 13 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", 14 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", 15 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", 16 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", 17 "Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", 18 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 19 "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 20 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", 21 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", 22 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", 23 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 24 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 25 "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", 26 "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", 27 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", 28 "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24" 29 ]
6、settings.py设置
1 # Obey robots.txt rules 2 ROBOTSTXT_OBEY = False 3 # Configure maximum concurrent requests performed by Scrapy (default: 16) 4 CONCURRENT_REQUESTS = 100 5 # Disable cookies (enabled by default) 6 COOKIES_ENABLED = False 7 DOWNLOADER_MIDDLEWARES = { 8 'mzitu.middlewares.MzituDownloaderMiddleware': 543, 9 'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware':None, 10 'mzitu.middlewares.RotateUserAgentMiddleware': 400, 11 }
7、运行爬虫
进入E:CodePythonSpidermzitu目录,运行scrapy crawl Mymzitu命令启动爬虫:
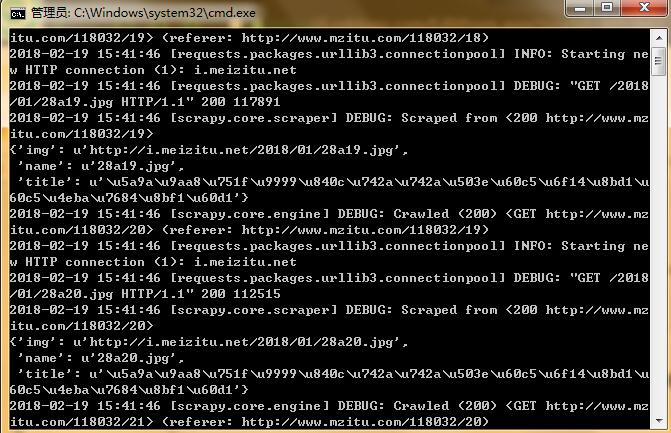
运行结果及完整代码详见:https://github.com/Eivll0m/PythonSpider/tree/master/mzitu