线程(下)
7.同步锁
这个例子很经典,实话说,这个例子我是直接照搬前辈的,并不是原创,不过真的也很有意思,请看:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
number = 100
def subnum():
global number
number -= 1
threads = []
for i in range(100):
t = threading.Thread(target=subnum,args=[])
t.start()
threads.append(t)
for i in threads:
i.join()
print(number)
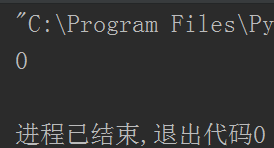
这段代码的意思是,用一百个线程去减1,以此让变量number为100的变为0
结果:
那么我稍微的改下代码看看:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
number = 100
def subnum():
global number
temp = number
time.sleep(0.2)
number = temp -1
threads = []
for i in range(100):
t = threading.Thread(target=subnum,args=[])
t.start()
threads.append(t)
for i in threads:
i.join()
print(number)
并没有很大的改变对吧,只是加了一个临时变量,并且中途停顿了0.2s而已。
而这个结果就不一样了:

这里我先说下,time.sleep(0.2)是我故意加的,就是要体现这个效果,如果你的电脑不加sleep就已经出现这个情况了那么你就不用加了,这咋回事呢?这就是线程共用数据的潜在危险性,因为线程都是抢着CPU资源在运行,只要发现有空隙就各自抢着跑,所以在这停顿的0.2s时间中,就会有新的线程抢到机会开始运行,那么一百个线程就有一百个线程在抢机会运行,抢到的时间都是在temp还没有减1的值,也就是100,所以大部分的线程都抢到了100,然后减1,少部分线程没抢到,抢到已经减了一次的99,这就是为什么会是99的原因。而这个抢占的时间和结果并不是根本的原因,究其根本还是因为电脑的配置问题了,配置越好的话,这种越不容易发生,因为一个线程抢到CPU资源后一直在运行,其他的线程在短暂的时间里得不到机会。
而为什么number -= 1,不借助其他变量的写法就没事呢?因为numebr -= 1其实是两个步骤,减1并重新赋值给number,这个动作太快,所以根本没给其他的线程机会。
图解:

那么这个问题我们怎么解决呢,在以后的开发中绝对会遇到这种情况对吧,这个可以解决呢?根据上面的讲解,有人会想到用join,而前面已经提过了join会使多线程变成串行,失去了多线程的用意。这个到底怎么解决呢,用同步锁
同步锁:当运行开始加锁,防止其他线程索取,当运行结束释放锁,让其他线程继续
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
r = threading.Lock() #创建同步锁对象
number = 100
def subnum():
global number
r.acquire() #加锁
temp = number
time.sleep(0.2)
number = temp - 1
r.release() #释放
threads = []
for i in range(100):
t = threading.Thread(target=subnum,args=[])
t.start()
threads.append(t)
for i in threads:
i.join()
print(number)
运行结果:
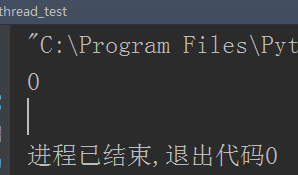
但是你发现没,这个运行太慢了,每个线程都运行了一次sleep,竟然又变成和串行运行差不多了对吧?不过还是和串行稍微有点不同,只是在有同步锁那里是串行,在其他地方还是多线程的效果
那么有朋友要问了,既然都是锁,已经有了一个GIL,那么还要同步锁来干嘛呢?一句话,GIL是着重于保证线程安全,同步锁是用户级的可控机制,开发中防止这种不确定的潜在隐患
8.死锁现象/可重用锁
前面既然已经用了同步锁,那么相信在以后的开发中,绝对会用到使用多个同步锁的时候,所以这里模拟一下使用两个同步锁,看看会有什么现象发生
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
a = threading.Lock() #创建同步锁对象a
b = threading.Lock() #创建同步锁对象b
def demo1():
a.acquire() #加锁
print('threading model test A....')
b.acquire()
time.sleep(0.2)
print('threading model test B....')
b.release()
a.release() #释放
def demo2():
b.acquire() #加锁
print('threading model test B....')
a.acquire()
time.sleep(0.2)
print('threading model test A....')
a.release()
b.release() #释放
threads = []
for i in range(5):
t1 = threading.Thread(target=demo1,args=[])
t2 = threading.Thread(target=demo2,args=[])
t1.start()
t2.start()
threads.append(t1)
threads.append(t2)
for i in threads:
i.join()
运行结果:
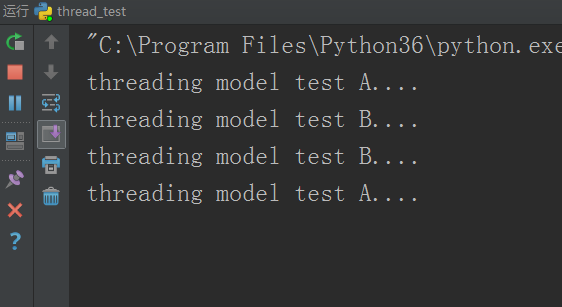
这里就一直阻塞住了,因为demo1函数用的锁是外层a锁,内层b锁,demo2函数刚好相反,外层b锁,内层a锁,所以当多线程运行时,两个函数同时在互抢锁,谁也不让谁,这就导致了阻塞,这个阻塞现象又叫死锁现象。
那么为了避免发生这种事,我们可以使用threading模块下的RLOCK来创建重用锁依此来避免这种现象
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
r = threading.RLock() #创建重用锁对象
def demo1():
r.acquire() #加锁
print('threading model test A....')
r.acquire()
time.sleep(0.2)
print('threading model test B....')
r.release()
r.release() #释放
def demo2():
r.acquire() #加锁
print('threading model test B....')
r.acquire()
time.sleep(0.2)
print('threading model test A....')
r.release()
r.release() #释放
threads = []
for i in range(5):
t1 = threading.Thread(target=demo1,args=[])
t2 = threading.Thread(target=demo2,args=[])
t1.start()
t2.start()
threads.append(t1)
threads.append(t2)
for i in threads:
i.join()
运行结果:
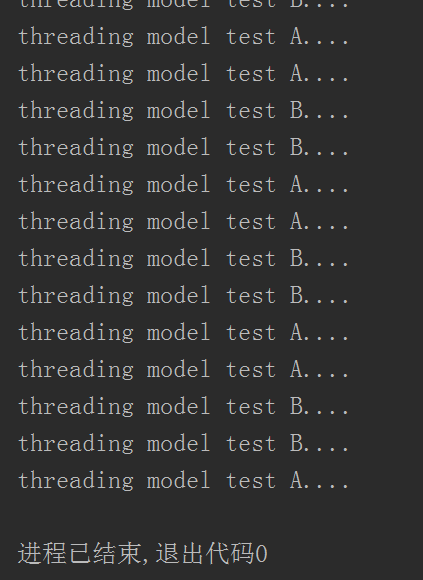
这个Rlock其实就是Lock+计算器,计算器里的初始值为0,每嵌套一层锁,计算器值加1,每释放一层锁,计算器值减1,和同步锁一样,只有当值为0时才算结束,让其他线程接着抢着运行。而这个Rlock也有一个官方一点的名字,递归锁
那么估计有朋友会问了,为什么会有死锁现象呢?或者你应该问,是什么生产环境导致有死锁现象的,还是那句,为了保护数据同步性,防止多线程操作同一数据时发生冲突。这个说辞很笼统对吧,我说细点。比如前面的购物车系统,虽然我们在操作数据时又重新取了一遍数据来保证数据的真实性,如果多个用户同时登录购物车系统在操作的话,或者不同的操作但会涉及到同一个数据的时候,就会导致数据可能不同步了,那么就可以在内部代码里加一次同步锁,然后再在实际操作处再加一次同步锁,这样就出现多层同步锁,那么也就会出现死锁现象了,而此时这个死锁现象是我们开发中正好需要的。
我想,说了这个例子你应该可以理解为什么lock里还要有lock,很容易导致死锁现象我们还是要用它了,总之如果需要死锁现象就用同步锁,不需要就换成递归锁。
9.信号量/绑定式信号量
信号量也是一个线程锁
1)Semaphore
信号量感觉更有具有多线程的意义。先不急着说,看看例子就懂:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
s = threading.Semaphore(3) #创建值为3的信号量对象
def demo():
s.acquire() #加锁
print('threading model test A....')
time.sleep(2)
s.release() #释放
threads = []
for i in range(10):
t = threading.Thread(target=demo,args=[])
t.start()
threads.append(t)
for i in threads:
i.join()
运行结果:

如果你亲自测试这段代码,你会发现,这个结果是3个一组出的,出了3次3个一组的,最后出了一个一组,3个一组都是并行的,中间停顿2秒。
这里可以给很形象的例子,假如某个地方的停车位只能同时停3辆车,当停车位有空时其他的车才可以停进来。这里的3个停车位就相当于信号量。
2)BoundedSemaphore
既然有信号量为我们完成这些一组一组的操作结果,但敢不敢保证这些线程就不会突然的越出这个设定好的车位呢?比如设定好的3个信号量一组,我们都知道线程是争强着运行,万一就有除了设定的3个线程外的一两个线程抢到了运行权,谁也不让谁,就是要一起运行呢?好比,这里只有3个车位,已经停满了,但有人就是要去挤一挤,出现第4辆或者第5辆车的情况,这个和现实生活中的例子简直太贴切了对吧?
那么我们怎么办?当然这个问题早就有人想好了,所以有了信号量的升级版——绑定式信号量(BoundedSemaphore)。既然是升级版,那么同信号量一样该有的都有的,用法也一样,就是有个功能,在设定好的几个线程一组运行时,如果有其他线程也抢到运行权,那么就会报错。
比如thread_lock = threading.BoundedSemaphore(5),那么多线程同时运行的线程数就必须在5以内(包括5),不然就报错。换句话,它拥有了实时监督的功能,好比停车位上的保安,如果发现车位满了,就禁止放行车辆,直到有空位了再允许车辆进入停车。
因为这个很简单,就多了个监督功能,其他和semaphore一样的用法,我就不演示了,自己琢磨吧
10.条件变量同步锁
不多说,它也是一个线程锁,本质上是在Rlock基础之上再添加下面的三个方法
condition = threading.Condition([Lock/RLock]),默认里面的参数是Rlock
wait():条件不满足时调用,释放线程并进入等待阻塞
notify():条件创造后调用,通知等待池激活一个线程
notifyall():条件创造后调用,通知等待池激活所有线程
直接上例子
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
from random import randint
class producer(threading.Thread):
'''
生产者
'''
def run(self):
global Li
while True:
value = randint(0,100) #创建一百以内随机数
print('生产者',self.name,'Append:'+str(value),Li)
if con.acquire(): #加锁
Li.append(value) #把产品加入产品列表里
con.notify() #通知等待池里的消费者线程激活并运行
con.release() #释放
time.sleep(3) #每3秒做一次产品
class consumer(threading.Thread):
'''
消费者
'''
def run(self):
global Li
while True:
con.acquire() #获取条件变量锁,必须和生产者同一个锁对象,生产者通知后在此处开始运行
if len(Li) == 0: #如果产品列表内没数据,表示消费者先抢到线程运行权
con.wait() #阻塞状态,等待生产者线程通知
print('消费者',self.name,'Delete:'+str(Li [0]),Li)
Li.remove(Li[0]) #删除被消费者用掉的产品
con.release() #释放
time.sleep(0.5) #每0.5秒用掉一个产品
con = threading.Condition() #创建条件变量锁对象
threads = [] #线程列表
Li = [] #产品列表
for i in range(5):
threads.append(producer())
threads.append(consumer())
for i in threads:
i.start()
for i in threads:
i.join()
运行结果:

图片只截取了部分,因为它一直在无线循环着的。这个生产者和消费者的模型很经典,必须理解,每个步骤分别什么意思我都注释了,不再赘述了。
11.event事件
类似于condition,但它并不是一个线程锁,并且没有锁的功能
event = threading.Event(),条件环境对象,初始值为False
event.isSet():返回event的状态值
event.wait():如果event.isSet()的值为False将阻塞
event.set():设置event的状态值为True,所有阻塞池的线程激活并进入就绪状态,等待操作系统调度
event.clear():恢复event的状态值False
不多说,看一个例子:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
class boss(threading.Thread):
def run(self):
print('boss:今晚加班!')
event.isSet() or event.set() #设置为True
time.sleep(5) #切换到员工线程
print('boss:可以下班了')
event.isSet() or event.set() #又设置为True
class worker(threading.Thread):
def run(self):
event.wait() #等待老板发话,只有值为True再往下走
print('worker:唉~~~,又加班')
time.sleep(1) #开始加班
event.clear() #设置标志为false
event.wait() #等老板发话
print('worker:oh yeah,终于可以回家了')
event = threading.Event()
threads = []
for i in range(5):
threads.append(worker())
threads.append(boss())
for i in threads:
i.start()
for i in threads:
i.join()
运行结果:

其实这个和condition的通信原理是一样的,只是condition用的是notify,event用的set和isset
*12.队列(queue)
本质上,队列是一个数据结构。
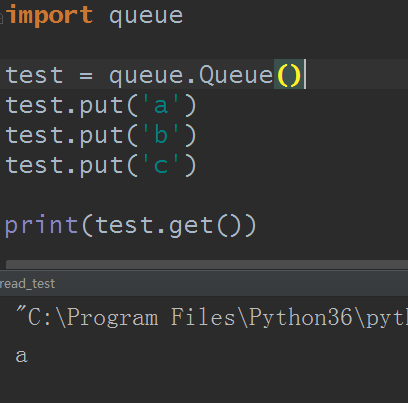
1)创建一个“队列”对象
import Queue
q = Queue.Queue(maxsize = 10)
Queue.Queue类即是一个队列的同步实现。队列长度可为无限或者有限。可通过Queue的构造函数的可选参数maxsize来设定队列长度。如果maxsize小于1就表示队列长度无限。
2)将一个值放入队列中
q.put(obj)
调用队列对象的put()方法在队尾插入一个项目。put()有两个参数,第一个item为必需的,为插入项目的值;第二个block为可选参数,默认为
1。如果队列当前为空且block为1,put()方法就使调用线程暂停,直到空出一个数据单元。如果block为0,put方法将引发Full异常。
3)将一个值从队列中取出
q.get()
调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。如果队列为空且block为False,队列将引发Empty异常。
例:
4)Python Queue模块有三种队列及构造函数:
- Python Queue模块的FIFO队列先进先出 class queue.Queue(maxsize)
- LIFO类似于堆,即先进后出 class queue.LifoQueue(maxsize)
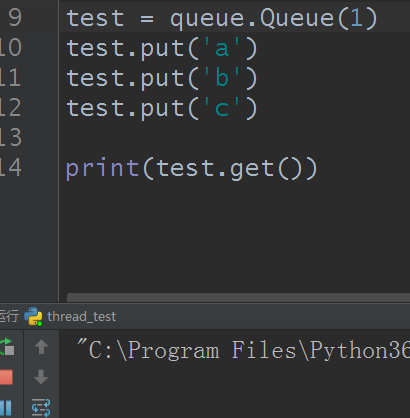
- 还有一种是优先级队列级别越低越先出来 class queue.PriorityQueue(maxsize)
当maxsize值比put的数量少时就会阻塞住,当数据被get后留有空间才能接着put进去,类似于线程的信号量
5)queue中的常用方法(q = Queue.Queue()):
q.qsize():返回队列的大小
q.empty():如果队列为空,返回True,反之False
q.full():如果队列满了,返回True,反之False,q.full与 maxsize 大小对应
q.get([block[, timeout]]) 获取队列,timeout等待时间
q.get_nowait():相当q.get(False)
q.put_nowait(item):相当q.put(item, False)
q.task_done():在完成一项工作之后,q.task_done() 函数向任务已经完成的队列发送一个信号
q.join():实际上意味着等到队列为空,再执行别的操作
6)队列有什么好处,与列表区别
队列本身就有一把锁,内部已经维持一把锁,如果你用列表的话,当环境是在多线程下,那么列表数据就一定会有冲突,而队列不会,因为此,队列有个外号——多线程利器
例:
#!usr/bin/env python
#-*- coding:utf-8 -*-
# author:yangva
import threading,time
import queue
from random import randint
class productor(threading.Thread):
def run(self):
while True:
r = randint(0,100)
q.put(r)
print('生产出来 %s 号产品'%r)
time.sleep(1)
class consumer(threading.Thread):
def run(self):
while True:
result =q.get()
print('用掉 %s 号产品'%result)
time.sleep(1)
q = queue.Queue(10)
threads = []
for i in range(3):
threads.append(productor())
threads.append(consumer())
for i in threads:
i.start()
运行结果:
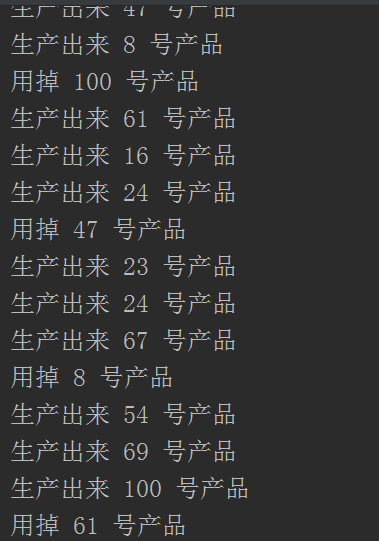
这里根本不用加锁就完成了前面的生产者消费者模型,因为queue里面自带了一把锁。
好的,关于线程的知识点,讲解完。
多线程式爬虫
有的朋友学完线程还不知道线程到底能运用于哪些生活实际,好的,不多说,来,我们爬下堆糖网(https://www.duitang.com/)的校花照片。
import requests
import urllib.parse
import threading,time,os
#设置照片存放路径
os.mkdir('duitangpic')
base_path = os.path.join(os.path.dirname(__file__),'duitangpic')
#设置最大信号量线程锁
thread_lock=threading.BoundedSemaphore(value=10)
#通过url获取数据
def get_page(url):
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
page=requests.get(url,headers=header)
page=page.content #content是byte
#转为字符串
page=page.decode('utf-8')
return page
#label 即是搜索关键词
def page_from_duitang(label):
pages=[]
url='https://www.duitang.com/napi/blog/list/by_search/?kw={}&start={}&limit=1000'
label=urllib.parse.quote(label)#将中文转成url(ASCII)编码
for index in range(0,3600,100):
u=url.format(label,index)
#print(u)
page=get_page(u)
pages.append(page)
return pages
def findall_in_page(page,startpart,endpart):
all_strings=[]
end=0
while page.find(startpart,end) !=-1:
start=page.find(startpart,end)+len(startpart)
end=page.find(endpart,start)
string=page[start:end]
all_strings.append(string)
return all_strings
def pic_urls_from_pages(pages):
pic_urls=[]
for page in pages:
urls=findall_in_page(page,'path":"','"')
#print('urls',urls)
pic_urls.extend(urls)
return pic_urls
def download_pics(url,n):
header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'}
r=requests.get(url,headers=header)
path=base_path+'/'+str(n)+'.jpg'
with open(path,'wb') as f:
f.write(r.content)
#下载完,解锁
thread_lock.release()
def main(label):
pages=page_from_duitang(label)
pic_urls=pic_urls_from_pages(pages)
n=0
for url in pic_urls:
n+=1
print('正在下载第{}张图片'.format(n))
#上锁
thread_lock.acquire()
t=threading.Thread(target=download_pics,args=(url,n))
t.start()
main('校花')
运行结果:

在与本py文件相同的目录下,有个duitangpic的文件夹,打开看看:

全是美女,而且不出意外又好几千张呢,我这只有一千多张是因为我手动结束了py程序运行,毕竟我这是演示,不需要真的等程序运行完。我大概估计,不出意外应该能爬到3000张左右的照片
怎么样,老铁,得劲不?刺不刺激?感受到多线程的用处了不?而且这还是python下的伪多线程(IO密集型,但并不算是真正意义上的多线程),你用其他的语言来爬更带劲。