Pagination
为什么要分页也不用多说了,大家都懂,DRF也自带了分页组件
这次用 前后端分离djangorestframework——序列化与反序列化数据 文章里用到的数据,数据库用的mysql,因为django自带的sqlite对于日期类型的数据会自动转成时间戳,导致数据再序列化时无法正常序列化成日期类型而出错
分页组件还是跟前面的认证组件,权限组件,频率组件很类似的
PageNumberPagination
在根目录创建一个utils文件夹,在该文件夹里创建一个pagination文件,在其内定义一个分页组件类,继承自DRF里自带的PageNumberPagination类:
DRF的分页组件PageNumberPagination源码

且注意这两个方法,paginate_queryset和get_paginated_response,后面视图类里会用到
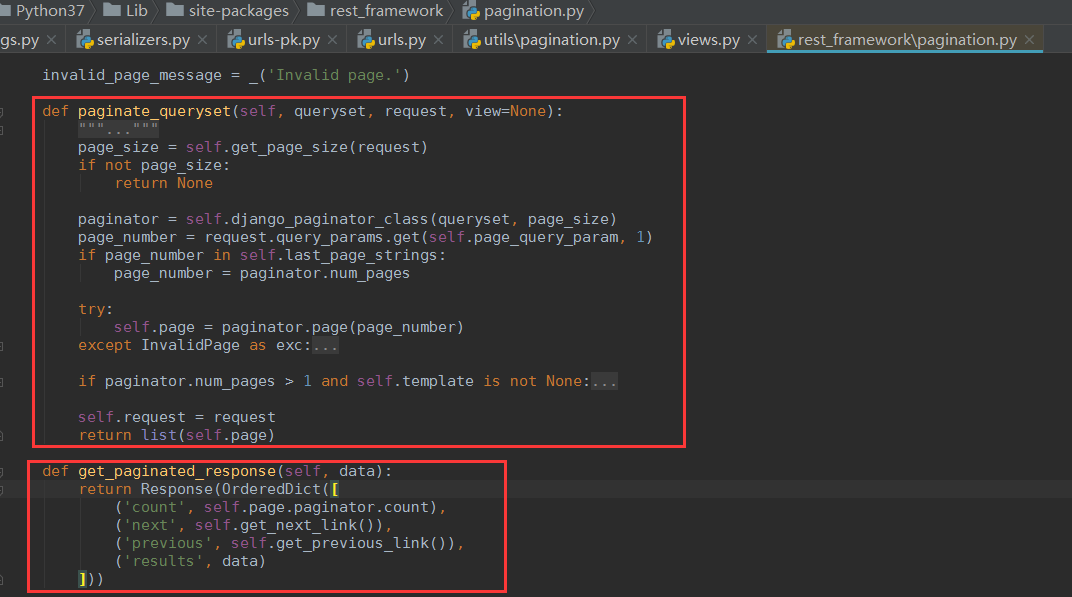
读django的源码,可知我们可以自定义一些属性或方法:
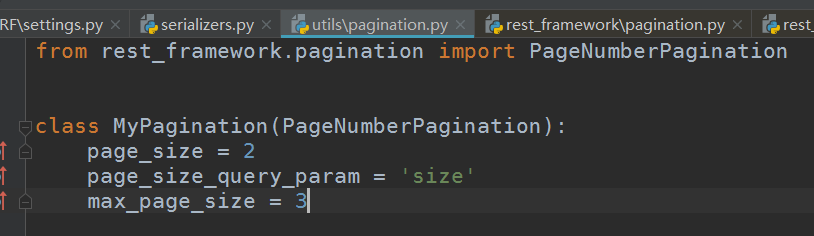
pagination:
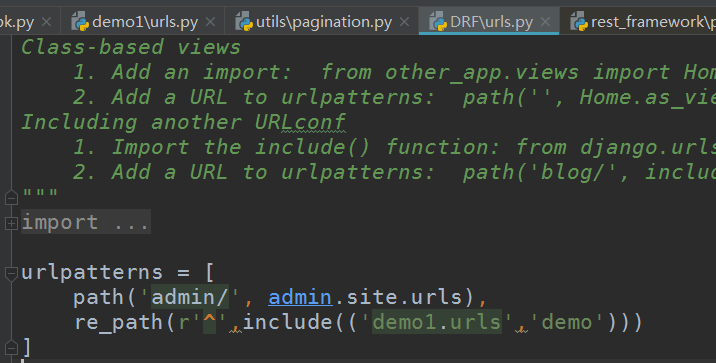
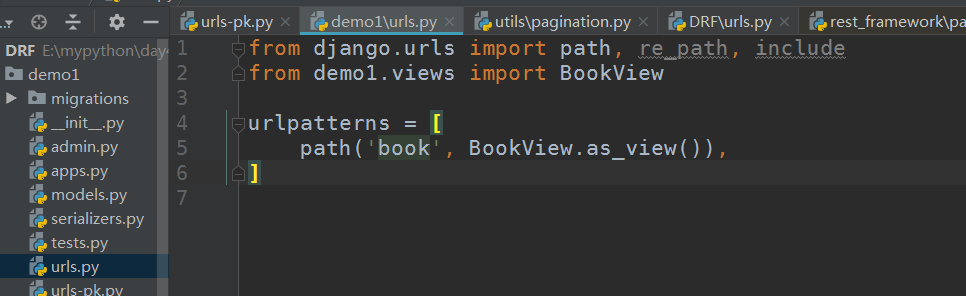
url:
view:

访问测试,显示一共8个数据,有上一页下一页,当前显示两个数据,这是刚才自定义分页组件时定义的

并且这个上一页下一页是可以直接点击的
相关代码:
pagination
from rest_framework.pagination import PageNumberPagination class MyPagination(PageNumberPagination): page_size = 2 page_size_query_param = 'size' max_page_size = 3
url:
from django.urls import path, re_path, include from demo1.views import BookView urlpatterns = [ path('book', BookView.as_view()), ]
view:
from demo1.serializers import BookSerializer from rest_framework.views import APIView from demo1.models import Book from utils.pagination import MyPagination class BookView(APIView): def get(self, request): queryset = Book.objects.all() # 1,实例化分页器对象 page_obj = MyPagination() # 2,调用分页方法去分页queryset page_queryset = page_obj.paginate_queryset(queryset, request, view=self) # 3,把分页好的数据序列化 ser_obj = BookSerializer(page_queryset, many=True) # 4, 带着上一页下一页连接的响应 return page_obj.get_paginated_response(ser_obj.data)
serializer:
class BookSerializer(serializers.ModelSerializer): category_display = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) publish_info = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj): return obj.get_category_display() def get_publish_info(self, obj): publish_obj = obj.publisher return {"id": publish_obj.id, 'title': publish_obj.title} def get_authors(self, obj): # obj是Book对象 author_list = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in author_list] class Meta: model = models.Book fields = '__all__' # depth = 1 # 表示外键查找层级 extra_kwargs = { "category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}, }
LimitOffsetPagination
同样的自定义分页组件,并继承此类即可:
pagination,其中的两个属性是看LimitOffsetPagination的源码所得:

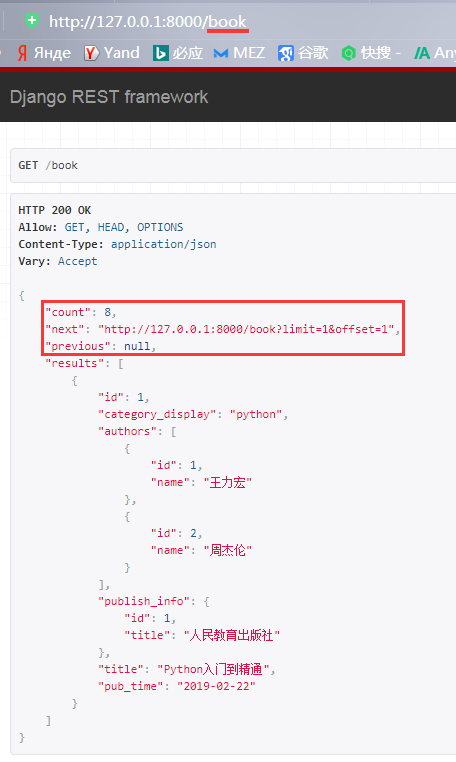
其他不用改,重启项目访问测试,一页只有一个数据,有上一页下一页的链接
并且上一页和下一页可以直接点击: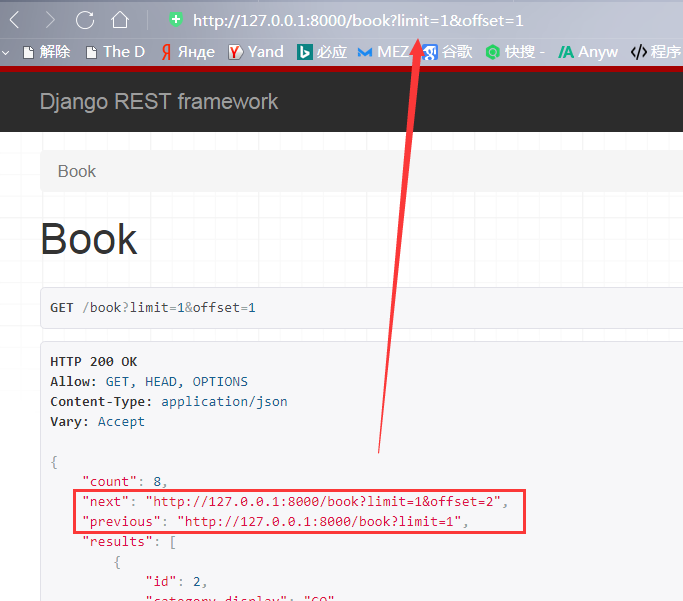
看起来好像和前面的PageNumberPagination差距不大对吧?LimitOffsetPagination,其参数offset是从第几个开始向后找,limit是只一次显示多少条数据的
当然你可以手动修改url的条件参数,从第一个开始找,每次显示8,这样就把我们本来就只有8个数据一起显示了
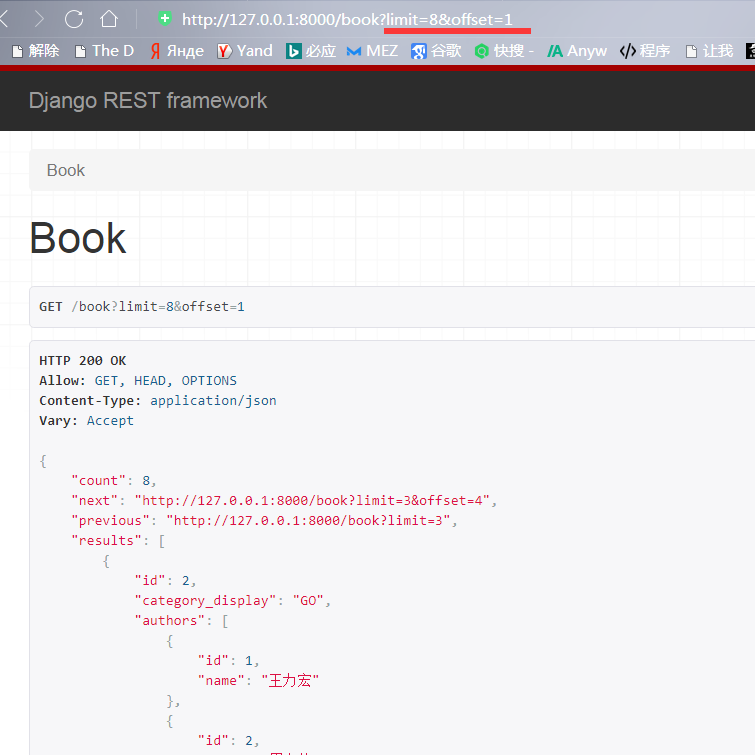
说到这,顺便说下,之前我们研究的Python爬虫, 有时候在爬数据时是发现网页没有刷新,但是是ajax异步请求,每次请求只显示一定数量的,就是因为有这个limit参数在,当时我们是怎么解决呢?就是直接在url后面修改limit参数,一次请求几百条数据或者多少都行,这样我们只请求了一次,但是这一下就拿到了多条数据,前面我们用的频率组件可以限制次数,到这我们一次请求拿几百或者几千这种的,就不好判断了
相关代码:
pagination:
from rest_framework.pagination import PageNumberPagination,LimitOffsetPagination class MyPagination(LimitOffsetPagination): default_limit = 1 max_limit = 3
view和url,serializers其实都没做任何更改:


from demo1.serializers import BookSerializer from rest_framework.views import APIView from demo1.models import Book from utils.pagination import MyPagination class BookView(APIView): def get(self, request): queryset = Book.objects.all() # 1,实例化分页器对象 page_obj = MyPagination() # 2,调用分页方法去分页queryset page_queryset = page_obj.paginate_queryset(queryset, request, view=self) # 3,把分页好的数据序列化 ser_obj = BookSerializer(page_queryset, many=True) # 4, 带着上一页下一页连接的响应 return page_obj.get_paginated_response(ser_obj.data)
from django.urls import path, re_path, include from demo1.views import BookView urlpatterns = [ path('book', BookView.as_view()), ]
from rest_framework import serializers from demo1 import models class PublishSerializer(serializers.Serializer): id = serializers.IntegerField() title = serializers.CharField(max_length=32) class AuthorSerializer(serializers.Serializer): id = serializers.IntegerField() name = serializers.CharField(max_length=32) class BookSerializer(serializers.ModelSerializer): category_display = serializers.SerializerMethodField(read_only=True) authors = serializers.SerializerMethodField(read_only=True) publish_info = serializers.SerializerMethodField(read_only=True) def get_category_display(self, obj): return obj.get_category_display() def get_publish_info(self, obj): publish_obj = obj.publisher return {"id": publish_obj.id, 'title': publish_obj.title} def get_authors(self, obj): # obj是Book对象 author_list = obj.author.all() return [{"id": author_obj.id, "name": author_obj.name} for author_obj in author_list] class Meta: model = models.Book fields = '__all__' # depth = 1 # 表示外键查找层级 extra_kwargs = { "category": {"write_only": True}, "publisher": {"write_only": True}, "author": {"write_only": True}, }
CursorPagination
这个游标分页,可以对访问的url的条件参数隐藏,防止被人根据url的条件参数猜出我们的数据量,可能有潜在的隐患
pagination:

访问测试,按id为11(11为数据库里的最后一个数据)开始倒序排序
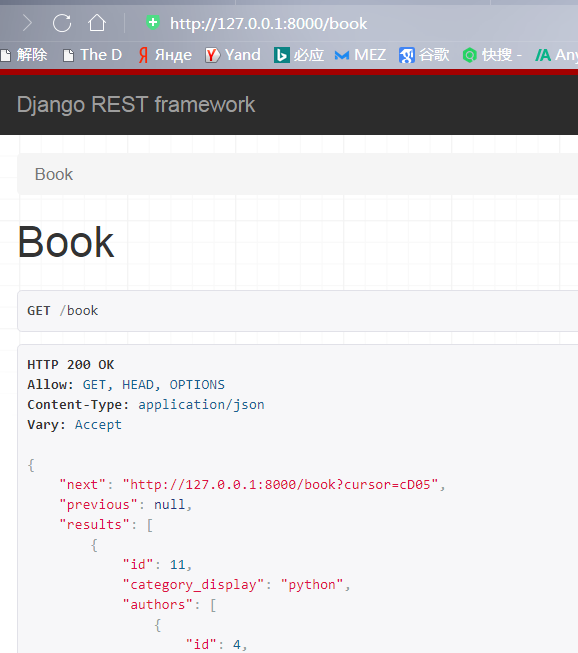
打开数据库,确实是倒序的
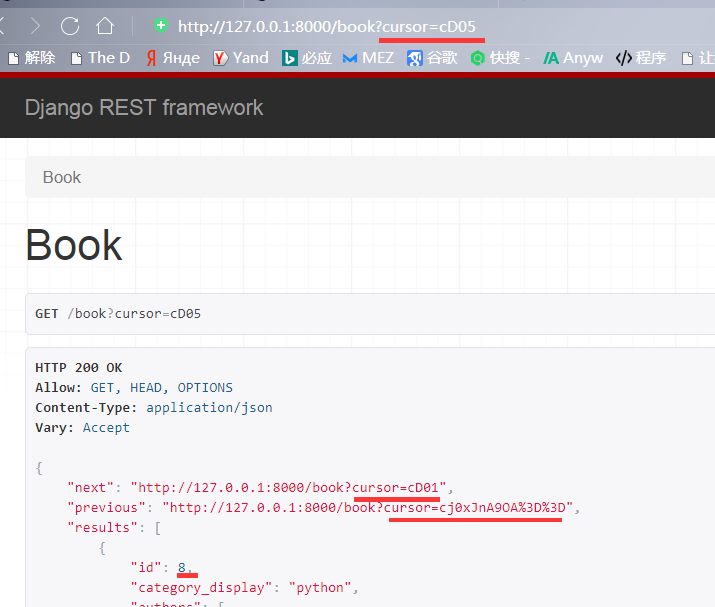
再点击上一页下一页,发现其参数是加密了的,根本无法通过这个条件参数猜解出我们的数据量
相关代码:
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination class MyPagination(CursorPagination): page_size = 2 ordering = '-id' # 表示从哪个字段开始排序
其他没有做任何更改,不再贴出浪费篇幅了
当然,这个还是可以使用之前的Modelserializer来优化代码,

# coding:utf-8 from rest_framework.generics import GenericAPIView from rest_framework.mixins import ListModelMixin from demo1.serializers import BookSerializer from demo1.models import Book from utils.pagination import MyPagination class BookView(GenericAPIView,ListModelMixin): queryset = Book.objects.all() serializer_class = BookSerializer pagination_class = MyPagination def get(self, request): return self.list(request)
其他不用作任何更改,访问测试:
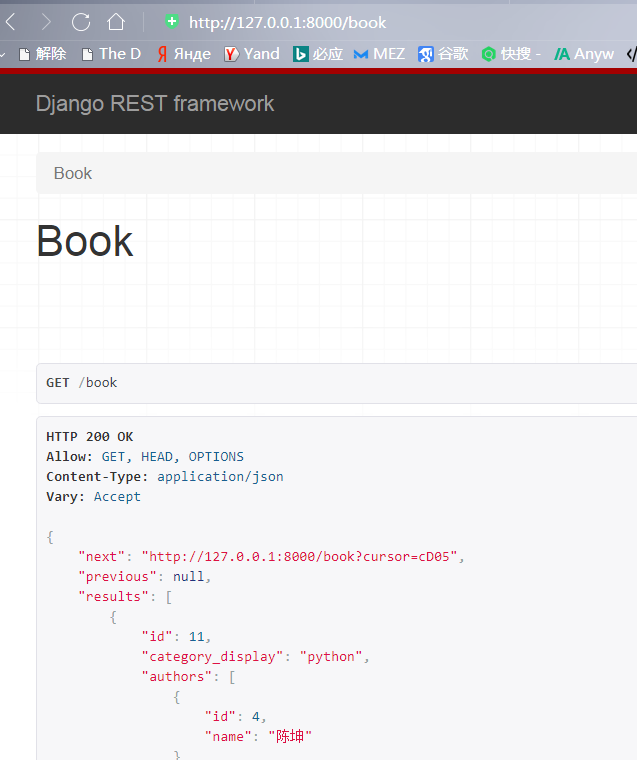
为什么这么方便,因为ListModelMixin中做了处理,假如有分页组件,那么就获取了分页的参数再返回:
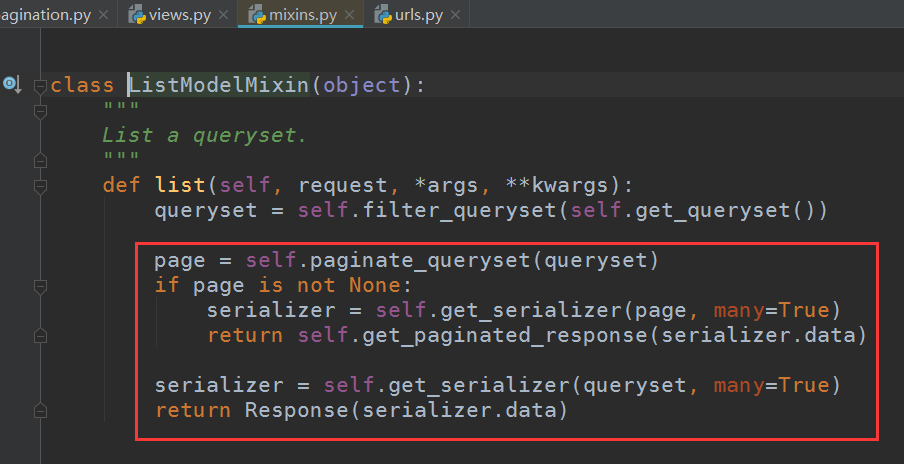
总结:
多看源码,根据需求选用源码的分页组件类,设定相关的参数