Env: VMWare Player, Win7, CentOS7, JDK8, Hadoop2.6
1. VM Structure
| Centos VM name | HOSTNAME(/etc/hostname) |
IP ADDR | |
| ecta | Master.Hadoop | 192.168.138.129 | |
| ectb | Slave1.Hadoop | 192.168.138.130 | |
| ecte | Slave2.Hadoop | 192.168.138.134 | |
2. 所有VM上都要配置 /ect/hosts,
"/etc/hosts"这个文件是用来配置主机将用的DNS服务器信息。
我们要测试两台机器之间知否连通,一般用"ping 机器的IP",如果想用"ping 机器的主机名"发现找不见该名称的机器(这也就是为什么在修改主机名的同时最好修改该文件中对应的主机名),解决的办法就是修改"/etc/hosts"这个文件,通过把LAN内的各主机的IP地址和HostName的一一对应写入这个文件的时候,就可以解决问题。
127.0.0.1 localhost
192.168.138.129 master.hadoop
192.168.138.130 Slave1.Hadoop
192.168.138.134 Slave2.Hadoop
reboot 后 [hadoop@Master ~]$
设置网卡自启动
cd /etc/sysconfig/network-scripts/
root 权限修改if-xxxx, ONBOOT=yes
重启网卡, service network restart
3. SSH无密码验证配置
SSH基本原理
SSH之所以能够保证安全,原因在于它采用了公钥加密。过程如下:
(1)远程主机收到用户的登录请求,把自己的公钥发给用户。
(2)用户使用这个公钥,将登录密码加密后,发送回来。
(3)远程主机用自己的私钥,解密登录密码,如果密码正确,就同意用户登录。
Master(NameNode | JobTracker)作为客户端,要实现无密码公钥认证,连接到服务器Salve(DataNode | Tasktracker)上时,
(1)首先在Master上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到所有的Slave上。
(2)当Master通过SSH连接Salve时,Salve就会生成一个随机数并用Master的公钥对随机数进行加密,并发送给Master。
(3)Master收到加密数之后再用私钥解密,并将解密数回传给Slave,Slave确认解密数无误之后就允许Master进行连接了。
这就是一个公钥认证过程,其间不需要用户手工输入密码。
Hadoop Master-Slave之间SSH无密码登录设置过程:
-1.
root 权限修改 /etc/ssh/sshd_config,保证下面三行没有被注释
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径
-2.
重启,service sshd restart
-3.
ssh-keygen –t rsa –P ''
运行后直接回车采用默认路径。生成的密钥对:id_rsa(私钥)和id_rsa.pub(公钥),默认存储在"/home/用户名/.ssh"目录下。
-4.
Master节点上把id_rsa.pub追加到授权的key里面
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
至此,本机普通用户可以无密码登录
-5.
~/.ssh里面,把公钥复制所有Slave机器上
ssh-copy-id hadoop@Slave1.Hadoop
ssh-copy-id hadoop@Slave2.Hadoop
这个命令的作用就是把当前机器的公钥追加到slave的authorized_keys里面;
效果跟scp复制到slave,然后cat 追加是一样的。
-6.
至此,Master账号可以ssh无密码登录到Slave
ssh hadoop@Slave1.Hadoop
-7.
如果登录不上,重启再试
-8.
从Slave无密码登录到Master,和Master无密码登录所有Slave原理一样,就是把Slave的公钥追加(>>)到Master的".ssh"文件夹下的"authorized_keys"中。
在Slave上root重复 1-4,
用scp把id_rsa.pub复制到Master上,如下
slave1上面
scp id_rsa.pub hadoop@Master.Hadoop:~/.ssh/slave_pub_key/s1
slave2上面
scp id_rsa.pub hadoop@Master.Hadoop:~/.ssh/slave_pub_key/s2
然后到Master上面,将s1,s2追加到Master的authorized_keys
[hadoop@Master .ssh]$ cat slave_pub_key/s1 >> authorized_keys
[hadoop@Master .ssh]$ cat slave_pub_key/s2 >> authorized_keys
-9.
Done.
4. Install JDK
(先在master上安装,装好后scp复制到各个slave)
首先需要确认jdk版本
如果是open jdk的版本,直接删除掉,不建议用open jdk版本
yum -y remove java-1.7.0-openjdk*
yum -y remove tzdata-java.noarch
下载JDK
解压到/usr, rm文件夹改名,从jdkxxxxx,改为java(个人习惯)
配置环境变量
sudo添加下面内容到文件末尾 /etc/profile, #后面是注释
# setup jdk path
export JAVA_HOME=/usr/java
export JRE_HOME=/usr/java/jre
export JAVA_BIN=/usr/java/bin
export PATH=$PATH:$JAVA_HOME:$JAVA_HOME/bin:$JRE_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使更改立即起效
source /etc/profile
查看jdk版本
java - version
复制到slave
scp -r /user/java hadoop@slave1:/user/java
如果出现Delta RPMs disabled because /usr/bin/applydeltarpm not installed
说明deltarpm 没有装,这个是一个用于增量安装的包,下面命令安装
yum provides '*/applydeltarpm'
yum install deltarpm
如果出现无法下载,或者速度太慢,就需要更改yum 源
可以先清除 yum clean all
然后自动获取源 yum repolist,将会自动确定新的源,并用最快的那个;
5. Install and Setup Hadoop
流程同JDK,下载解压改名到/usr/hadoop
sudo vim /etc/profile, 追加下面内容
#set hadoop path
export HADOOP_HOME=/usr/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export JAVA_HOME JAVA_BIN PATH CLASSPATH HADOOP_HOME HADOO_COMMON_LIB_NATIVE_DIR HADOOP_OPTS
复制到slave
scp -r /user/hadoop hadoop@slave1:/user/hadoop
6. Start Hadoop and Testing
./start-all.sh 这个命令已经废弃,用下面两个代替
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
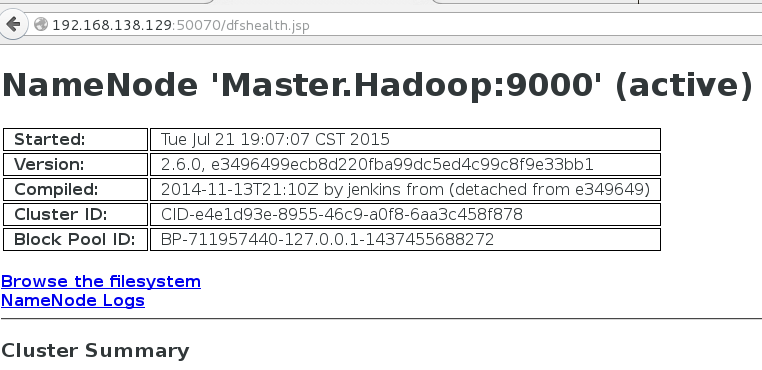
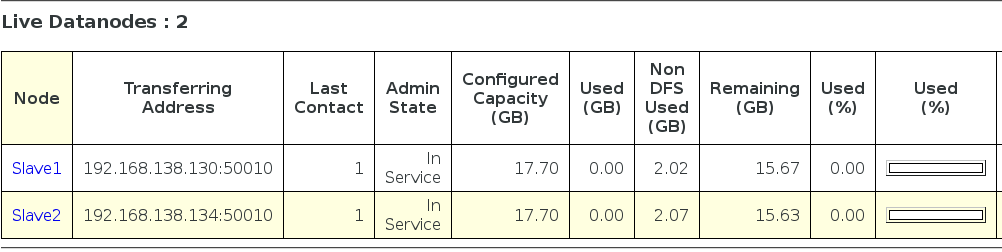
Live Nodes:
7. 查看启动的hdfs和yarn的进程
jps(Java Virtual Machine Process Status Tool)
Hadoop2.x 之后不再有Tracker 进程
查看集群状态
[hadoop@Master hadoop]$ bin/hdfs dfsadmin -report
Configured Capacity: 38002491392 (35.39 GB)
Present Capacity: 33613959168 (31.31 GB)
DFS Remaining: 33613950976 (31.31 GB)
DFS Used: 8192 (8 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.138.130:50010 (Slave1.Hadoop)
Hostname: Slave1.Hadoop
Decommission Status : Normal
Configured Capacity: 19001245696 (17.70 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 2171301888 (2.02 GB)
DFS Remaining: 16829939712 (15.67 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.57%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Jul 22 10:56:51 CST 2015
Name: 192.168.138.134:50010 (Slave2.Hadoop)
Hostname: Slave2.Hadoop
Decommission Status : Normal
Configured Capacity: 19001245696 (17.70 GB)
DFS Used: 4096 (4 KB)
Non DFS Used: 2217230336 (2.06 GB)
DFS Remaining: 16784011264 (15.63 GB)
DFS Used%: 0.00%
DFS Remaining%: 88.33%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Wed Jul 22 10:56:51 CST 2015
8. 运行sample 程序Wordcount
cd /usr/hadoop
sbin/start-all.sh
新建文本文件, 编辑添加单词
vim test.txt
新建文件夹test
[hadoop@Master hadoop]$ bin/hadoop fs -mkdir /test
将文件上传到hdfs
[hadoop@Master hadoop]$ ./bin/hadoop fs -put /usr/hadoop/test.txt /test/
查看上传的文件
hadoop fs -ls /test/
Jar运行
cd /usr/hadoop/bin
./hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar wordcount /test/test.txt /output/testResult
Error file exists
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.138.129:9000/output already exists
需要先清除输出 hadoop dfs -rmr output/
查看运行完后的文件
[hadoop@Master bin]$ hadoop fs -ls /output/testResult
Found 2 items
-rw-r--r-- 3 hadoop supergroup 0 2015-07-27 14:34 /output/testResult/_SUCCESS
-rw-r--r-- 3 hadoop supergroup 60 2015-07-27 14:34 /output/testResult/part-r-00000
查看运行结果,单词统计结果
[hadoop@Master bin]$ hdfs dfs -cat /output/testResult/*
cui1
ender2
great1
hadoop1
hello1
java1
nice1
test1
9. 常见问题及处理:
1.
slave2: chown: changing ownership of `/home/hadoop/deploy/hadoop-1.0.4/libexec/../logs': Operation not permitted
解决:用sudo chown -R mini /home/hadoop来解决,即将hadoop主目录授权给当前mini用户
2.
Jobtracker没启动,查log发现
org.apache.hadoop.security.AccessControlException: The systemdir hdfs://master:9000/tmp/hadoop/mapred/system is not owned by mini
解决:修改hadoop的配置文件:conf/hdfs-core.xml, 找到 dfs.permissions 的配置项 , 将value值改为 false
3.
slave 上用jps查看,没有DataNode
解决:
stop-all.sh清空hdfs-site.xml里面配置的dfs.data.dir的data和name目录,清空hadoop下面的tmp,hadoop namenode -formatstart-all.sh
4. put 不成功,错误如下
hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException:
首先关闭所有机器的防火墙,service iptables stop
然后, 禁用selinux: vim /etc/selinux/config,设置“SELINUX=disabled”
最后reboot
5. 主服务器与从服务器时间不同步,导致运行jar时候 yarn报错
this token is expired,
解决:主服务器安装NTP服务并启用,sudo systemctl start ntpd.service
从服务器同步主机时间, sudo ntpdate 192.168.138.129
6.